![]()
![]()
![]()
![]()
![]()
14
Hier sind Sie schon bei der letzten Lektion der zweiten Woche angelangt und machen sich daran, letzte Feinheiten über Applets und AWT zu lernen. Mit dem heutigen Lernstoff können Sie eine große Vielfalt von Applets und Anwendungen in Java entwickeln. Die Lektionen der nächsten Woche werden fortgeschritteneren Lernstoff beinhalten, den Sie für komplexere Arbeiten mit Java benötigen.
Zum Abschluß dieser Woche werden wir uns heute mit einer Reihe von sehr unterschiedlichen Themen und anderen Feinheiten, die nirgendwo dazupassen, befassen wie:
Diese Lektion beginne ich mit ein paar kleinen Tips, die sonst nirgendwo hineinpassen: Die Verwendung von showStatus(), um Meldungen im Broswer-Statusfenster auszugeben, Applet-Informationen bereitzustellen und zwischen mehreren Applets auf der gleichen Seite eine Kommunikation zu ermöglichen.
Die in der Klasse Applet verfügbare showStatus()-Methode ermöglicht Ihnen die Anzeige einer Zeichenkette in der Statuszeile des Browser, in dem das Applet ausgegeben wird. Sie können dies zum Ausgeben von Fehler-, Verknüpfungs-, Hilfs- oder anderen Statusmeldungen benutzen:
getAppletContext().showStatus("Change the color");
Die Methode getAppletContext() ermöglicht Ihrem Applet Zugriff auf Funktionen des Browsers, in dem es enthalten ist. Sie haben dies teilweise schon im Zusammenhang mit Verknüpfungen kennengelernt, für die Sie die showDocument()-Methode benutzt haben, um den Browser zum Laden einer Seite aufzufordern. showStatus() bedient sich desselben Mechanismus, um Statusmeldungen auszugeben.
Das AWT-Toolkit bietet einen Mechanismus, zum Einbinden von Informationen in Ihr Applet. Normalerweise umfaßt der Browser, in dem das Applet betrachtet wird, eine Möglichkeit zur Anzeige von Bildschirminformationen. Mit diesem Mechanismus können Sie Ihr Applet mit Ihrem Namen oder Ihrer Organisation unterzeichnen oder entsprechende Informationen zur Kontaktaufnahme bereitstellen, damit die Benutzer auf Wunsch mit Ihnen in Verbindung treten können.
Zur Angabe von Informationen über Ihr Applet überschreiben Sie die Methode getAppletInfo():
public String getAppletInfo() {
return "GetRaven copyright 1995 Laura Lemay";
}
Da Applets auf Browser-Webseiten laufen, stellt die Möglichkeit, die Fähigkeit des Browsers zum Laden neuer Webseiten zu nutzen, ein gute Lösung dar. Java bietet einen Mechanismus, der dem Browser zum Laden einer neuen Seite veranlaßt. Sie können diesen Mechanismus beispielsweise zu Erstellung von animierten Imagemaps benutzen, die beim Anklicken eine neue Seite laden.
Zur Verknüpfung einer neuen Seite erstellen Sie eine neue Instanz der URL-Klasse. Sie haben dies bereits im Zusammenhang mit Bildern gesehen. Hier steigen wir aber etwas tiefer in die Materie ein.
Die URL-Klasse stellt einen »Uniform Resource Locator« dar, einen Zeiger auf eine Datei oder Objekt im World Wide Web. Um einen neuen URL zu erzeugen, können Sie einen von vier unterschiedlichen Konstruktoren verwenden:
Bei der letzten Form (Erstellen eines URL aus einer Zeichenkette) müssen Sie eine eventuell falsch gebildete URL-Adresse berücksichtigen, deshalb umgeben Sie den URL-Konstruktor mit einem try...catch-Block:
String url = "http://www.yahoo.com/";
try { theURL = new URL(url); }
catch ( MalformedURLException e) {
System.out.println("Bad URL: " + theURL);
}
Das ermitteln und erzeugen eines URL-Objektes ist der schwierige Teil. Wenn Sie eines haben, brauchen Sie es nur an den Browser weiterzugeben. Das geschieht in einer einzigen Codezeile, wobei der URL das URL-Objekt ist, mit dem die Verknüpfung hergestellt werden soll:
getAppletContext().showDocument(theURL);
Der Browser, der das Java-Applet mit diesem Code enthält, wird dann das Dokument laden und bei diesem URL anzeigen.
Listings 14.1 und 14.2 zeigen die beiden Klassen: ButtonLink und seine Handler-Klasse Bookmark. ButtonLink ist ein einfaches Applet, das drei Schaltflächen anzeigt, die wichtige Web-Standorte darstellen (die Schaltflächen sind in Abbildung 14.1 dargestellt). Durch Anklicken der Schaltflächen wird das Dokument von den Standorten, auf die sich diese Schaltflächen beziehen, geladen.
|
Abbildung 14.1:
|
Listing 14.1: Bookmark-Schaltflächen (Buttonlink.java)
1: // Buttonlink.java beginnt hier
2: import java.awt.*;
3: import java.net.*;
4:
5: public class ButtonLink extends java.applet.Applet {
6:
7: Bookmark bmlist[] = new Bookmark[3];
8:
9: public void init() {
10: bmlist[0] = new Bookmark("Laura's Home Page",
11: "http://www.lne.com/lemay/");
12: bmlist[1] = new Bookmark("Gamelan",
13: "http://www.gamelan.com");
14: bmlist[2]= new Bookmark("Java Home Page",
15: "http://java.sun.com");
16:
17: setLayout(new GridLayout(bmlist.length,1, 10, 10));
18: for (int i = 0; i < bmlist.length; i++) {
19: add(new Button(bmlist[i].name));
20: }
21: }
22:
23: public boolean action(Event evt, Object arg) {
24: if (evt.target instanceof Button) {
25: linkTo((String)arg);
26: return true;
27: }
28: else return false;
29: }
30:
31: void linkTo(String name) {
32: URL theURL = null;
33: for (int i = 0; i < bmlist.length; i++) {
34: if (name.equals(bmlist[i].name))
35: theURL = bmlist[i].url;
36: }
37: if (theURL != null)
38: getAppletContext().showDocument(theURL);
39: }
40: }
Listing 14.2: Bookmark-Schaltflächen (Bookmark.java)
1: import java.net.URL;
2: import java.net.MalformedURLException;
3:
4: class Bookmark {
5: String name;
6: URL url;
7:
8: Bookmark(String name, String theURL) {
9: this.name = name;
10: try { this.url = new URL(theURL); }
11: catch ( MalformedURLException e) {
12: System.out.println("Bad URL: " + theURL);
13: }
14: }
15:}
Dieses Applet besteht aus zwei Klassen: Die erste, ButtonLink, implementiert das Applet; die zweite, Bookmark, ist eine Klasse, die ein Bookmark (Lesezeichen) darstellt. Bookmarks bestehen wiederum aus zwei Teilen: einem Namen und einer URL.
Dieses spezielle Applet erstellt drei Bookmark-Instanzen (Zeilen 10 bis 15) und speichert sie in einem Bookmark-Array (dieses Applet könnte leicht so abgeändert werden, daß es Bookmarks als Parameter aus einer HTML-Datei enthält). Für jedes Bookmark wird eine Schaltfläche erstellt, deren Beschriftung dem Wert des Bookmark-Namens entspricht.
Durch Anklicken einer Schaltfläche wird die linkTo()-Methode aufgerufen. linkTo() ist in den Zeilen 31 bis 38 definiert und benutzt den Namen der Schaltfläche, die das Ereignis ausgelöst hat, um den eigentlichen URL aus dem Bookmark-Objekt zu ermitteln, und weist dann den Browser an, den URL zu laden, auf den dieses Lesezeichen verweist.
Zuweilen möchten Sie vielleicht mehrere Applets in eine HTML-Seite stellen. Um dies zu realisieren, können Sie mehrere verschiedene <APPLET>-Tags einbinden. Der Browser erstellt dann die Instanz für jedes Applet, das auf der HTML-Seite erscheint.
Was nun, wenn diese Applets miteinander kommunizieren sollen? Oder wenn in einem Applet etwas geändert wird, das die übrigen Applets in irgendeiner Weise betrifft? Die beste Möglichkeit hierfür ist die Verwendung des Applet-Kontexts, um mehrere Applets in eine Seite einzubinden.
Der Applet-Kontext ist in einer entsprechend benannten Klasse, der Klasse AppletContext, definiert. Um eine Instanz dieser Klasse für Ihr Applet zu holen, verwenden Sie die Methode getAppletContext(). Den Umgang mit der getAppletContext()-Methode haben Sie bereits in verschiedenen Beispielen gelernt. Sie können diese Methode auch verwenden, um andere Applets in eine Seite zu stellen. Um beispielsweise eine Methode mit dem Namen sendMessage() in allen Applets auf einer Seite aufzurufen (einschließlich des jeweils aktuellen Applets), verwenden Sie die getApplets()-Methode und eine for-Schleife, die etwa folgendermaßen aussieht:
for (Enumeration e = getAppletContext().getApplets();
e.hasMoreElements();) {
Applet current = (MyAppletSubclass)(e.nextElement());
current.sendMessage();
}
Die getApplets()-Methode gibt ein Enumeration-Objekt mit einer Liste der auf der Seite befindlichen Applets aus. Die for-Schleife für das Enumeration-Objekts ermöglicht Ihnen den Zugriff auf alle Elemente nacheinander in der Auflistung. Beachten Sie, daß jedes Element in dem Enumeration-Objekt eine Instanz der Objektklasse ist; um ein Ihren Wünschen entsprechendes Verhalten des Applet zu erreichen (und Meldungen von anderen Applets aufzunehmen), müssen Sie es so gestalten, daß es eine Instanz Ihrer Applet-Subklasse ist (in diesem Fall der Klasse MyAppletSubclass).
Etwas komplizierter wird es, wenn Sie eine Methode in einem spezifischen Applet aufrufen wollen. Hierfür geben Sie jedem Applet einen Namen und setzen in den Rumpf des betreffenden Applet-Codes eine Referenz auf diesen Namen.
Um einem Applet einen Namen zu geben, benutzen Sie das NAME-Attribut für <APPLET> in Ihrer HTML-Datei:
<P>This applet sends information:
<APPLET CODE="MyApplet.class" WIDTH=100 HEIGHT=150
NAME="sender"> </APPLET>
<P>This applet receives information from the sender:
<APPLET CODE="MyApplet.class" WIDTH=100 HEIGHT=150
NAME="receiver"> </APPLET>
Um eine Referenz zu einem anderen Applet auf der gleichen Seite zu erhalten, verwenden Sie die getApplet()-Methode aus dem Applet-Kontext mit dem Namen des betreffenden Applet. Dadurch erhalten Sie eine Referenz zu dem Applet dieses Namens. Sie können dann auf das Applet so verweisen, als wäre es nur ein anderes Objekt: Methoden aufrufen, seine Instanzvariablen setzen usw. Hier ein entsprechender Code dafür:
// Receiver-Applet holen
Applet receiver = (MyAppletSubclass)getAppletContext().getApplet("receiver");
// Anweisen zur Aktualisierung.
receiver.update(text, value);
In diesem Beispiel wird die getApplet()-Methode verwendet, um eine Referenz zu dem Applet mit dem Namen receiver zu erhalten. Beachten Sie, daß das von getApplet() ausgegebene Objekt eine Instanz der generischen Applet-Klasse ist; es ist anzunehmen, daß Sie dieses Objekt einer Instanz Ihrer Subklasse zuweisen wollen. Mit der Referenz zu dem benannten Applet, können Sie dann Methoden in diesem Applet aufrufen, als ob es ein anderes Objekt in Ihrer eigenen Umgebung wäre. Sie können beispielsweise, vorausgesetzt beide Applets besitzen eine update()-Methode, den Empfänger anweisen, sich selbst unter Verwendung der Informationen des aktuellen Applet zu aktualisieren.
Indem Sie Ihren Applets Namen geben und sich dann auf sie mit den in diesem Abschnitt beschriebenen Methoden beziehen, können Ihre Applets miteinander kommunizieren und sich auf die jeweils geänderten Informationen des anderen Applet aktualisieren, so daß alle Applets auf Ihrer Seite ein einheitliches Verhalten aufweisen.
Mit »Vernetzung« ist hier die Fähigkeit gemeint, zwischen einem Applet oder einer Anwendung über ein Netzwerk eine Verbindung zu einem System herzustellen. Hierfür stehen in Java die Klassen des Pakets java.net zur Verfügung, die plattformübergreifende Abstraktionen für einfache Vernetzungsoperationen, z.B. das Verbinden und Abrufen von Dateien über übliche Web-Protokolle und das Erstellen UNIX-artiger Sockets, enthalten. In Verbindung mit Ein- und Ausgabe-Streams (hierüber lernen Sie nächste Woche mehr) ist das Lesen und Schreiben von Dateien über ein Netz so einfach wie auf einem lokalen System.
Selbstverständlich gibt es gewisse Einschränkungen. Java-Applets können nicht auf der Platte der Gastmaschine, auf der der Browser läuft, schreiben und lesen. Java-Applets können nicht mit anderen Systemen, außer dem, auf dem sie ursprünglich gespeichert wurden, verbunden werden. Trotz dieser Einschränkungen können Sie aber viel erreichen und das Web umfassend nutzen, um Informationen über das Netz zu lesen und zu verarbeiten.
Dieser Abschnitt beschreibt zwei einfache Wege, wie Sie mit Systemen im Netz kommunizieren können:
Anstatt den Browser lediglich aufzufordern, den Inhalt einer Datei zu laden, möchten Sie vielleicht den Inhalt der Datei in Ihrem Applet benutzen. Ist die betreffende Datei im Web gespeichert und über die üblichen URL-Formen (http, ftp usw.) zugänglich, können Sie die URL-Klasse benutzen, um die Datei in Ihrem Applet zu verwenden.
Beachten Sie, daß Applets aus Sicherheitsgründen nur zurück zu dem gleichen Host, von dem sie ursprünglich geladen wurden, verbunden werden können. Das bedeutet beispielsweise bei einem Applet, das auf einem System namens www.myhost.com gespeichert ist, daß Ihr Applet nur mit diesem Host (und dem gleichen Hostnamen, deshalb vorsichtig mit Aliasnamen!) eine Verbindung herstellen kann. Befindet sich eine Datei, die das Applet abrufen möchte, auf dem gleichen System, sind URL-Verbindungen die einfachste Möglichkeit, dies zu erreichen.
Diese Sicherheitseinschränkung wird die Art und Weise, in der Sie Applets bis jetzt geschrieben und getestet haben, ändern. Da wir uns noch nicht mit Netzverbindungen beschäftigt haben, war es uns möglich, alle Tests auf der lokalen Platte durch einfaches Öffnen der HTML-Dateien oder mit dem Werkzeug zum Betrachten des Applet durchzuführen. Dies ist mit Applets, die Netzverbindungen öffnen, nicht möglich. Damit diese Applets richtig funktionieren, müssen Sie eines von zwei Dingen tun:
Sie werden schon merken, ob Ihr Applet und die Verbindung, die es öffnet, auf dem gleichen Server sind. Bei dem Versuch, ein Applet oder eine Datei von unterschiedlichen Servern zu laden, erhalten Sie, zusammen mit anderen unheimlichen, auf Ihrem Bildschirm oder der Java-Konsole ausgegebenen Fehlermeldungen, eine Sicherheitsausnahme.
Das haben wir abgehandelt! Beschäftigen wir uns jetzt mit den Methoden und Klassen zum Laden von Dateien aus dem Web.
Die URL-Klasse definiert eine Methode namens openStream(), die eine Netzverbindung mit einem bestimmten URL öffnet (eine HTTP-Verbindung für Web-URLs, eine FTP-Verbindung für FTP-URLs, usw.) und eine Instanz der Klasse InputStream (Teil des java.io-Pakets) ausgibt. Wenn Sie diesen Stream in einen DataInputStream (mit einem BufferedInputStream in der Mitte, um die Leistung zu steigern) konvertieren, können Sie Zeichen und Zeilen aus diesem Stream lesen (Sie lernen alles über Streams am Tag 19, »Java-Datenstreams«). Diese Zeilen öffnen beispielsweise eine Verbindung zu dem URL, der in der Variablen theURL gespeichert ist, und lesen dann den Inhalt jeder Zeile der Datei und geben ihn auf dem Standardausgabegerät aus:
try {
InputStream in = theURL.openStream();
DataInputStream data = new DataInputStream(new BufferedInputStream(in);
String line;
while ((line = data.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
System.out.println("IO Error: " + e.getMessage());
}
Das folgende Beispiel eines Applet nutzt die openStream()-Methode, um eine Verbindung zu einem Web-Standort herzustellen. Dann wird über diese Verbindung eine Datei (»Der Rabe« von Edgar Allen Poe) gelesen und in einem Textbereich angezeigt. Listing 14.3 enthält den Code; das Ergebnis nach dem Lesen der Datei sehen Sie in Abbildung 14.2.
|
Abbildung 14.2:
|
Hierzu ein äußerst wichtiger Hinweis: Wenn Sie diesen Code wie geschrieben kompilieren, funktioniert er nicht – und Sie erhalten eine Sicherheitsausnahme. Der Grund dafür ist, daß dieses Applet eine Verbindung zu dem Server www.lne.com zum Holen der Datei raven.txt öffnet. Wenn Sie dieses Applet kompilieren und damit arbeiten, läuft dieses Applet nicht auf www.lne.com (es sei denn, Sie sind »Ich« und kennen somit das Problem bereits). Bevor Sie dieses Applet kompilieren können, müssen Sie unbedingt die Zeile 18 so verändern, daß sie auf eine Kopie von raven.txt auf Ihrem Web-Server hinweist und Ihr Applet und Ihre HTML-Dateien auf dem gleichen Server installieren (Sie können raven.txt von der CD oder von genau dem URL holen).
Alternativ dazu können Sie Ihren Browser dazu benutzen, auf den URL http://www.lne.com/Web/JavaProf/GetRaven.html hinzuweisen. Diese Webseite lädt genau dieses Applet und sorgt für korrektes Runterladen der Datei. Da sich sowohl das Applet als auch die Textdatei auf dem gleichen Server befinden, funktioniert alles bestens.
Listing 14.3: Die GetRaven-Klasse
1: import java.awt.*;
2: import java.io.DataInputStream;
3: import java.io.BufferedInputStream;
4: import java.io.IOException;
5: import java.net.URL;
6: import java.net.URLConnection;
7: import java.net.MalformedURLException;
8:
9: public class GetRaven extends java.applet.Applet implements Runnable {
10: URL theURL;
11: Thread runner;
12: TextArea ta = new TextArea("Getting text...");
13:
14: public void init() {
15: setLayout(new GridLayout(1,1));
16:
17: // DIESEN TEXT VOR DER KOMPILIERUNG ÄNDERN!!!
18: String url = "http://www.lne.com/Web/JavaProf/raven.txt";
19: try { this.theURL = new URL(url); }
20: catch ( MalformedURLException e) {
21: System.out.println("Bad URL: " + theURL);
22: }
23: add(ta);
24: }
25:
26: public Insets insets() {
27: return new Insets(10,10,10,10);
28: }
29:
30: public void start() {
31: if (runner == null) {
32: runner = new Thread(this);
33: runner.start();
34: }
35: }
36:
37: public void stop() {
38: if (runner != null) {
39: runner.stop();
40: runner = null;
41: }
42: }
43:
44: public void run() {
45: URLConnection conn = null;
46: DataInputStream data = null;
47: String line;
48: StringBuffer buf = new StringBuffer();
49:
50: try {
51: conn = this.theURL.openConnection();
52: conn.connect();
53: ta.setText("Connection opened...");
54: data = new DataInputStream(new BufferedInputStream(
55: conn.getInputStream()));
56: ta.setText("Reading data...");
57: while ((line = data.readLine()) != null) {
58: buf.append(line + "\n");
59: }
60: ta.setText(buf.toString());
61: }
62: catch (IOException e) {
63: System.out.println("IO Error:" + e.getMessage());
64: }
65:}
66:}
Die init()-Methode (Zeilen 14 bis 24) richtet den URL und den Textbereich ein, in dem diese Datei angezeigt wird. Der URL könnte leicht über einen HTML-Parameter an das Applet abgegeben werden; hier wurde er der Einfachheit halber hartcodiert. Da es einige Zeit dauern kann, bis die Datei über das Netz geladen wird, stellen Sie diese Routine in einen eigenen Thread und benutzen die Ihnen inzwischen bestens bekannten Methoden start(), stop() und run(), um diesen Thread zu steuern. Innerhalb von run() (Zeilen 44 bis 64) findet die eigentliche Arbeit statt. Hier initialisieren Sie mehrere Variablen und öffnen dann die Verbindung zum URL (mit der openStream()-Methode in Zeile 50). Ist die Verbindung aufgebaut, richten Sie in den Zeilen 51 bis 55 einen Eingabe-Stream ein, von dem zeilenweise gelesen wird. Das Ergebnis wird in eine Instanz von StringBuffer (das ist eine änderbare Zeichenkette) gestellt. Ich stelle die gesamte Arbeit in einen Thread, da der Verbindungsaufbau und das Lesen der Datei – insbesondere über langsamere Verbindungen, einige Zeit in Anspruch nehmen kann. Parallel zum Laden der Datei sind möglicherweise andere Aktivitäten in dem Applet auszuführen.
Nachdem alle Daten gelesen wurden, konvertiert Zeile 60 das StringBuffer-Objekt in eine echte Zeichenkette und stellt das Ergebnis in den Textbereich.
Bezüglich dieses Beispiels ist noch etwas anderes zu beachten: nämlich daß der Teil des Codes, der eine Netzverbindung geöffnet, aus der Datei gelesen und eine Zeichenkette erstellt hat, zwischen eine try...catch-Anweisung gestellt wird. Tritt während des Versuchs, die Datei zu lesen oder zu verarbeiten, ein Fehler auf, ermöglicht diese Anweisung die Wiederherstellung, ohne daß das gesamte Programm abstürzt (in diesem Fall beendet das Programm mit einem Fehler, weil ansonsten wenig getan werden kann, wenn das Applet die Datei nicht lesen kann). Mit try...catch können Sie Ihrem Applet die Möglichkeit geben, auf Fehler zu reagieren und diese entsprechend zu behandeln. Am Tag 17 lernen Sie alles über Ausnahmen.
Für vernetzte Anwendungen, die über das hinausgehen, was die Klassen URL und URLconnection bieten (z.B. für andere Protokolle oder allgemeinere vernetzte Anwendungen), bietet Java die Klassen Socket und ServerSocket als Abstraktion von standardmäßigen TCP-Socket-Programmiertechniken.
Die Socket-Klasse bietet eine clientseitige Socket-Schnittstelle, die mit UNIX-Standard-Sockets vergleichbar ist. Um eine Verbindung herzustellen, legen Sie eine neue Instanz von Socket an (wobei der Hostname der Host ist, zu dem die Verbindung herzustellen ist, und Portnum die Portnummer ist):
Socket connection = new Socket(hostname, portnum);
Nachdem Sie den Socket geöffnet haben, können Sie Ein- und Ausgabe-Streams verwenden, um über diesen Socket zu lesen und zu schreiben (Sie lernen alles über Ein- und Ausgabe-Streams am Tag 19):
DataInputStream in = new DataInputStream(
new BufferedInputStream(connection.getInputStream()));
DataOutputStream out= new DataOutputStream(
new BufferedOutputStream(connection.getOutputStream()));
Zum Schluß müssen Sie den Socket schließen (dadurch werden auch alle Ein- und Ausgabe-Streams geschlossen, die Sie für diesen Socket eingerichtet haben):
connection.close();
Server-seitige Sockets funktionieren auf ähnliche Weise, mit Ausnahme der accept()-Methode. Ein Server-Socket richtet sich nach einem TCP-Port, um eine Client-Verbindung aufzubauen; wenn sich ein Client an diesen Port anschließt, akzeptiert die accept()-Methode eine Verbindung von diesem Client. Durch Verwendung von Client- und Server-Sockets können Sie Anwendungen entwickeln, die miteinander über das Netz kommunizieren.
Um einen Server-Socket zu erstellen und an einen Port anzubinden, legen Sie eine neue Instanz von ServerSocket mit der Portnummer an:
ServerSocket sconnection = new ServerSocket(8888);
Um diesen Port zu bedienen (und bei Anfrage eine Verbindung von Clients entgegenzunehmen), benutzen Sie die accept()-Methode:
sconnection.accept();
Sobald die Socket-Verbindung aufgebaut ist, können Sie die Ein- und Ausgabe-Streams verwenden, um vom Client zu lesen und zu schreiben.
Im nächsten Abschnitt, »Trivia: Ein einfacher Socket-Client und -Server«, gehen wir einige Codes durch, um eine einfache Socket-basierte Anwendung zu realisieren.
In der Version 1.02 von Java bieten die Klassen Socket und ServerSocket eine einfache abstrakte Socket-Implementierung. Sie können neue Instanzen dieser Klassen zum Aufbau oder Akzeptieren von Verbindungen anlegen und zur Weiter- oder Rückgabe von Daten von einem Client an einen Server.
Das Problem entsteht bei dem Versuch, das Socket-Verhalten von Java zu erweitern oder zu ändern. Die Klassen Socket und ServerSocket im java.net-Paket sind Final-Klassen, was bedeutet, daß Sie von diesen Klassen keine Subklassen erzeugen können (Final-Klassen lernen Sie am Tag 15, »Modifier»). Um das Verhalten der Socket-Klassen zu erweitern – beispielsweise um es Netzverbindungen zu ermöglichen, über eine Firewall oder einen Proxy zu arbeiten –, können Sie die abstrakten Klassen SocketImpl und die Schnittstelle SocketImplFactory verwenden, um eine neue Transportebene der Socket-Implementierung zu erstellen. Dieses Design stimmt mit dem ursprünglichen Konzept für die Java-Socket-Klassen überein: es diesen Klassen zu ermöglichen, mit unterschiedlichen Transportmechanismen auf andere Systeme portierbar zu sein. Das Problem dieses Mechanismus besteht darin, daß, während er in einfachen Fällen funktioniert, er es Ihnen aber nicht ermöglicht, zusätzlich zu TCP noch andere Protokolle hinzuzufügen (z.B. einen Verschlüsselungsmechanismus wie SSL zu realisieren) oder mehrere Socket-Implementierungen zur Java-Laufzeit zu haben.
Deshalb wurden Sockets in Java 1.1 so geändert, daß die Klassen Socket und ServerSocket »nicht final« und erweiterbar sind. Sie können jetzt Subklassen dieser Klassen mit Java 1.1 erstellen, die entweder die Standard-Socket-Implementierung benutzen oder eine von Ihnen selbst kreierte. Dies gestaltet die Vernetzungsfähigkeiten von Java 1.1 wesentlich flexibler.
Darüber hinaus wurden in Java 1.1 dem java.net-Paket verschiedene neue Features hinzugefügt:
Detaillierte Informationen über alle die Vernetzung betreffenden Änderungen zwischen Java 1.02 und 1.1 finden Sie auf den Seiten zu http://java.sun.com/products/jdk/1.1/docs/relnotes/features.html.
Den Abschluß des Themas Vernetzung in Java bildet das Beispiel eines Java-Programms, das die Socket-Klasse zur Realisierung einer einfachen netzbasierten Anwendung namens Trivia benutzt.
Trivia arbeitet folgendermaßen: Das Server-Programm wartet geduldig auf die Herstellung einer Verbindung eines Client. Wird die Verbindung von einem Client hergestellt, übermittelt der Server eine Frage und wartet auf die Reaktion. Am anderen Ende erhält der Client die Frage und veranlaßt den Benutzer zur Antwort. Der Benutzer gibt eine Antwort ein, die an den Server zurück übermittelt wird. Der Server überprüft dann, ob die Antwort richtig ist, und informiert den Benutzer. Der Server faßt noch einmal nach, indem er den Client fragt, ob er eine andere Frage möchte. Falls ja, wird der Prozeß wiederholt.
Im allgemeinen erweist es sich als zweckdienlich, bevor Sie damit beginnen, in umfangreichem Maße Code zu produzieren, einen kurzen vorläufigen Entwurf anzufertigen. Schauen wir uns also zuerst einmal an, was wir für den Trivia-Server und -Client benötigen. Server-seitig brauchen Sie ein Programm, das einen spezifischen Port der Hostmaschine hinsichtlich Client-Verbindungen überwacht. Wird ein Client entdeckt, wählt der Server eine Zufallsfrage und übermittelt sie über diesen spezifischen Port an den Client. Der Server gibt dann einen Wartestatus ein, bis er erneut eine Reaktion vom Client verzeichnet. Erhält der Server eine Antwort vom Client, überprüft er sie und gibt dem Client bekannt, ob die Antwort richtig oder falsch ist. Anschließend fragt der Server den Client, ob er eine weitere Frage wünscht, woraufhin er bis zur Antwort des Client einen weiteren Wartestatus eingibt. Abschließend wiederholt der Server entweder den Prozeß, indem er eine weitere Frage stellt, oder beendet die Verbindung mit dem Client. Zusammenfassend führt der Server die folgenden Aufgaben aus:
1. Warten auf die Verbindungsherstellung eines Client
Client-seitig ist dieses Trivia-Beispiel eine Anwendung, die von einer Befehlszeile aus arbeitet (auf diese Art leichter aufzeigbar). Der Client ist für die Verbindungsherstellung zum Server zuständig und wartet auf eine Frage. Bei Erhalt einer Frage vom Server zeigt der Client diese dem Benutzer an und gibt dem Benutzer die Möglichkeit zur Eingabe einer Antwort. Diese Antwort wird an den Server zurückübermittelt, und der Client wartet wieder auf die Reaktion des Server. Der Client zeigt dem Benutzer die Antwort des Server an und ermöglicht dem Benutzer zu bestätigen, ob er eine weitere Frage wünscht. Der Client sendet dann die Antwort des Benutzers an den Server und beendet die Verbindung, falls der Benutzer keine weiteren Fragen wünscht. Die hauptsächlichen Aufgaben des Client sind:
1. Herstellen der Verbindung zum Server
Der Server bildet den wesentlichsten Bestandteil bei den Trivia-Beispielen. Das Trivia-Server-Programm heißt TriviaServer und befindet sich auf der CD-ROM in der Datei TriviaServer.java. Hier die in der TriviaServer-Klasse definierten Instanzvariablen:
private static final int PORTNUM = 1234;
private static final int WAITFORCLIENT = 0;
private static final int WAITFORANSWER = 1;
private static final int WAITFORCONFIRM = 2;
private String[] questions;
private String[] answers;
private ServerSocket serverSocket;
private int numQuestions;
private int num = 0;
private int state = WAITFORCLIENT;
private Random rand = new Random(System.currentTimeMillis());
Die Konstanten WAITFORCLIENT, WAITFORANSWER und WAITFORCONFIRM sind allesamt Statuskonstanten, die der Definition unterschiedlicher Stati, in denen sich der Server befinden kann, dienen. Den Einsatz dieser Konstanten sehen Sie gleich. Die Frage- und Antwortvariablen sind Zeichenketten-Arrays zur Speicherung der Fragen und Antworten. Die serverSocket-Instanzvariable richtet sich nach der Server-Socket-Verbindung. numQuestions wird zur Speicherung der Gesamtanzahl der Fragen benutzt, wobei num die Anzahl der aktuell gestellten Fragen wiedergibt. Die state-Variable verfügt über den aktuellen Status des Server wie von den drei Statuskonstanten (WAITFORCLIENT, WAITFORANSWER und WAITFORCONFIRM) festgelegt. Und die rand-Variable wird dazu verwendet, Zufallsfragen auszuwählen.
Der TriviaServer-Konstruktor macht nicht viel mit Ausnahme der Erstellung eines ServerSocket anstatt eines DatagramSocket. Schauen Sie sich’s an:
public TriviaServer() {
super("TriviaServer");
try {
serverSocket = new ServerSocket(PORTNUM);
System.out.println("TriviaServer up and running...");
}
catch (IOException e) {
System.err.println("Exception: couldn't create socket");
System.exit(1);
}
}
Der größte Teil der Aktionen spielt sich in der run()-Methode in der TriviaServer-Klasse ab. Listing 14.4 zeigt den Quellcode für die Run-Methode.
Listing 14.4: Die run( )-Methode
1: public void run() {
2: Socket clientSocket;
3:
4: // Initialisieren de Fragen-/Antwort-Arrays
5: if (!initQnA()) {
6: System.err.println("Error: couldn't initialize questions and answers");
7: return;
8: }
9:
10: // Nach Clients suchen und Trivia-Fragen stellen
11: while (true) {
12: // Auf Client warten
13: if (serverSocket == null)
14: return;
15: try {
16: clientSocket = serverSocket.accept();
17: }
18: catch (IOException e) {
19: System.err.println("Exception: couldn't connect to client socket");
20: System.exit(1);
21: }
22:
23: // Fragen-/Antwortverarbeitung druchführen
24: try {
25: DataInputStream is = new DataInputStream(new
26: BufferedInputStream(clientSocket.getInputStream()));
27: PrintStream os = new PrintStream(new
28: BufferedOutputStream(clientSocket.getOutputStream()), false);
29: String inLine, outLine;
30:
31: // Serveranfrage ausgeben
32: outLine = processInput(null);
33: os.println(outLine);
34: os.flush();
35:
36: // Verarbeietung und Ausgabe Benutzereingabe
37: while ((inLine = is.readLine()) != null) {
38: outLine = processInput(inLine);
39: os.println(outLine);
40: os.flush();
41: if (outLine.equals("Bye."))
42: break;
43: }
44:
45: // Aufräumen
46: os.close();
47: is.close();
48: clientSocket.close();
49: }
50: catch (Exception e) {
51: System.err.println("Exception: " + e);
52: e.printStackTrace();
53: }
54: }
55: }
Durch Aufrufen von initQnA() initialisiert die run()-Methode zunächst die Fragen und Antworten. Über die initQnA()-Methode werden Sie gleich mehr erfahren. Danach wird eine Endlos-while-Schleife gestartet, die auf eine Client-Verbindung wartet. Stellt ein Client die Verbindung her, werden die entsprechenden I/O-Streams erzeugt und die Kommunikation durch die processInput()-Methode verarbeitet. processInput() ist unser nächstes Thema. processInput() verarbeitet kontinuierlich Client-Antworten und sorgt für das Stellen neuer Fragen, bis der Client sich entschließt, keine weiteren Fragen mehr zu erhalten. Dies wird vom Server entsprechend durch Übermitteln der Zeichenkette »Bye.« bestätigt. Die run()-Methode sorgt anschließend dafür, daß die Streams und der Client-Socket geschlossen werden.
Die processInput()-Methode richtet sich nach dem Server-Status und stellt die Logik des gesamten Fragen-/Antwortprozesses. Listing 14.5 zeigt den Quellcode für processInput.
Listing 14.5: Die processInput()-Methode
1: String processInput(String inStr) {
2: String outStr;
3:
4: switch (state) {
5: case WAITFORCLIENT:
6: // Frage stellen
7: outStr = questions[num];
8: state = WAITFORANSWER;
9: break;
10:
11: case WAITFORANSWER:
12: // Antwort prüfen
13: if (inStr.equalsIgnoreCase(answers[num]))
14: outStr = "That's correct! Want another? (y/n)";
15: else
16: outStr = "Wrong, the correct answer is " + answers[num] +
17: ". Want another? (y/n)";
18: state = WAITFORCONFIRM;
19: break;
20:
21: case WAITFORCONFIRM:
22: // Sehen, ob weitere Frage gewünscht
23: if (inStr.equalsIgnoreCase("y")) {
24: num = Math.abs(rand.nextInt()) % questions.length;
25: outStr = questions[num];
26: state = WAITFORANSWER;
27: }
28: else {
29: outStr = "Bye.";
30: state = WAITFORCLIENT;
31: }
32: break;
33: }
34: return outStr;
35: }
Als erstes ist bei der processInput()-Methode die lokale Variable outStr zu beachten. Der Wert dieser Zeichenkette wird in der Run-Methode an den Client zurückgesandt, wenn processInput antwortet. Beachten Sie also, wie processInput die lokale Variable outStr benutzt, um Informationen an den Client zurückzuführen.
In FortuneServer stellt der Status WAITFORCLIENT den Server im Status leer und auf eine Client-Verbindung wartend dar. Das bedeutet also, daß jedes Fall-Statement in der processInput()-Methode den Server in dem Status, den er gerade verläßt, darstellt. Das Fall-Statement WAITFORCLIENT wird beispielsweise eingegeben, wenn der Server den Status WAITFORCLIENT gerade verlassen hat. Anders ausgedrückt hat ein Client gerade eine Verbindung zum Server hergestellt. In diesem Fall setzt der Server die Ausgabezeichenkette auf die aktuelle Frage und den Status auf WAITFORANSWER.
Verläßt der Server den Status WAITFORANSWER, bedeutet dies, daß der Client mit einer Antwort reagiert hat. processInput() prüft die Antwort des Client mit die richtige Antwort und setzt dementsprechend die Ausgabezeichenkette. Anschließend setzt sie den Status auf WAITFORCONFIRM.
Im WAITFORCONFIRM-Status wartet der Server auf eine Bestätigungsantwort vom Client. In der Methode processInput() zeigt die Einzelfallaussage WAITFORCONFIRM an, daß der Server den Status verläßt, da der Client mit einer Bestätigung (ja oder nein) geantwortet hat. Hat der Client die Frage mit y bejaht, wählt processInput eine neue Frage und setzt den Status wieder auf WAITFORANSWER. Andernfalls gibt der Server Bye. an den Client aus und setzt den Status erneut auf WAITFORCLIENT, um auf eine neue Client-Verbindung zu warten.
Die Trivia-Fragen und -Antworten sind in einer Textdatei namens QnA.txt gespeichert und dort zeilenweise mit Fragen und Antworten im Wechsel aufgebaut. Wechselweise bedeutet, daß auf jede Frage eine entsprechende Antwort auf der nächsten Zeile folgt, woran sich wiederum die nächste Frage anschließt. Hier eine teilweise Auflistung der Datei QnA.txt:
What caused the craters on the moon?
meteorites
How far away is the moon (in miles)?
239000
How far away is the sun (in millions of miles)?
93
Is the Earth a perfect sphere?
no
What is the internal temperature of the Earth (in degrees)?
9000
Die initQnA()-Methode kümmert sich um das Lesen der Fragen und Antworten aus der Textdatei und deren Speicherung in getrennten String-Arrays. Listing 14.6 enthält den Quellcode für die initQnA()-Methode.
Listing 14.6: Die initQnA()-Methode
1: private boolean initQnA() {
2: try {
3: File inFile = new File("QnA.txt");
4: FileInputStream inStream = new FileInputStream(inFile);
5: byte[] data = new byte[(int)inFile.length()];
6:
7: // Fragen und Antworten in Byte-Array einlesen
8: if (inStream.read(data) <= 0) {
9: System.err.println("Error: couldn't read questions and answers");
10: return false;
11: }
12:
13: // Anzahl der Fragen/Antwort-Paare prüfen
14: for (int i = 0; i < data.length; i++)
15: if (data[i] == (byte)'\n')
16: numQuestions++;
17: numQuestions /= 2;
18: questions = new String[numQuestions];
19: answers = new String[numQuestions];
20:
21: // Fragen und Antworten in Zeichenkettenarray ablegen
22: int start = 0, index = 0;
23: boolean isQ = true;
24: for (int i = 0; i < data.length; i++)
25: if (data[i] == (byte)'\n') {
26: if (isQ) {
27: questions[index] = new String(data, 0, start, i – start – 1);
28: isQ = false;
29: }
30: else {
31: answers[index] = new String(data, 0, start, i – start – 1);
32: isQ = true;
33: index++;
34: }
35: start = i + 1;
36: }
37: }
38: catch (FileNotFoundException e) {
39: System.err.println("Exception: couldn't find the fortune file");
40: return false;
41: }
42: catch (IOException e) {
43: System.err.println("Exception: I/O error trying to read questions");
44: return false;
45: }
46:
47: return true;
48: }
Die initQnA()-Methode setzt zwei Arrays ein und füllt sie abwechselnd mit Zeichenketten aus der QnA.txt-Datei: erst eine Frage, dann eine Antwort, jeweils im Wechsel, bis das Dateiende erreicht ist.
Die einzige in TriviaServer verbleibende Methode ist main(), die lediglich das Server-Objekt erzeugt und es mit einem Aufruf an die Start-Methode startet:
public static void main(String[] args) {
TriviaServer server = new TriviaServer();
server.start();
}
Da Client-seitig im Trivia-Beispiel der Benutzer Antworten eingeben und Rückantworten vom Server erhalten muß, stellt sich die Implementierung als Befehlszeilenanwendung unkomplizierter dar. Vielleicht ist das nicht so nett wie ein grafisches Applet, gestaltet es aber sehr einfach, die Entwicklung der Kommunikationsereignisse zu verfolgen. Die Client-Anwendung heißt Trivia und befindet sich auf der CD-ROM in der Datei Trivia.java.
Die einzige in der Trivia-Klasse definierte Instanzvariable ist PORTNUM, die zur Definition der sowohl vom Client als auch vom Server benutzten Portnummer dient. Es gibt auch nur eine in der Trivia-Klasse definierte Methode: main(). Der Quellcode der main()-Methode ist in Listing 14.7 aufgeführt.
Listing 14.7: Die main()-Methode
1: public static void main(String[] args) {
2: Socket socket;
3: DataInputStream in;
4: PrintStream out;
5: String address;
6:
7: // Befelhzeilenargumente für Host-Adresse prüfen
8: if (args.length != 1) {
9: System.out.println("Usage: java Trivia <address>");
10: return;
11: }
12: else
13: address = args[0];
14:
15: // Socket und Streams initialisieren
16: try {
17: socket = new Socket(address, PORTNUM);
18: in = new DataInputStream(socket.getInputStream());
19: out = new PrintStream(socket.getOutputStream());
20: }
21: catch (IOException e) {
22: System.err.println("Exception: couldn't create stream socket");
23: System.exit(1);
24: }
25:
26: // Benutzereingabe und Server-Reaktion verarbeiten
27: try {
28: StringBuffer str = new StringBuffer(128);
29: String inStr;
30: int c;
31:
32: while ((inStr = in.readLine()) != null) {
33: System.out.println("Server: " + inStr);
34: if (inStr.equals("Bye."))
35: break;
36: while ((c = System.in.read()) != '\n')
37: str.append((char)c);
38: System.out.println("Client: " + str);
39: out.println(str.toString());
40: out.flush();
41: str.setLength(0);
42: }
43:
44: // Aufräumen
45: out.close();
46: in.close();
47: socket.close();
48: }
49: catch (IOException e) {
50: System.err.println("Exception: I/O error trying to talk to server");
51: }
52: }
Was Ihnen vielleicht als erstes bei der main()-Methode auffällt ist, daß sie ein Befehlszeilenargument sucht. Das erforderliche Befehlszeilenargument des Trivia-Client ist die Server-Adresse wie z.B. thetribe.com. Da es sich hierbei um eine Java-Anwendung und nicht um ein Applet handelt, reicht es nicht aus, nur die Verbindung zurück zum Server, von dem das Applet stammt, herzustellen – es gibt keinen Standard-Server, Sie können also die Verbindung zu einem beliebigen Server herstellen. In der Client-Anwendung müssen Sie die Server-Adresse entweder hartcodieren oder sie als Befehlszeilenargument anfordern. Ich bin kein großer Freund des Hartcodierens, da jede Änderung erneutes Kompilieren notwendig macht. Also das Befehlszeilenargument!
Ist das Befehlszeilenargument der Server-Adresse gültig (ungleich Null), erstellt die main()-Methode den erforderlichen Socket und I/O-Streams. Anschließend startet Sie eine while-Schleife, wobei sie Informationen vom Server verarbeitet und Benutzeranfragen an den Server zurück übermittelt. Wenn der Server die Übermittlung von Informationen beendet (mit Bye.), wird die while-Schleife mit break verlassen, und die main()-Methode sorgt für das Schließen des Socket und der Streams. Jetzt wissen Sie alles über den Trivia-Client!
Der Trivia-Server muß laufen, damit der Client arbeiten kann. Dazu müssen Sie zuerst unter Verwendung des Java-Interpreter den Server starten; dies wird folgendermaßen über einen Befehl auf Befehlszeilen-Ebene erreicht:
java TriviaServer
Auch der Trivia-Client wird über die Befehlszeile gestartet, allerdings müssen Sie eine Server-Adresse als einziges Argument spezifizieren. Nachfolgend ein Beispiel zum Starten des Trivia-Client und Anschluß an den Server thetribe.com:
java Trivia "thetribe.com"
Wenn Trivia-Client läuft und einige Fragen beantwortet hat, sollte die Ausgabe etwa so aussehen:
Server: Is the Galaxy rotating?
yes
Client: yes
Server: That’s correct! Want another? (y/n)
y
Client: y
Server: Is the Earth a perfect sphere?
no
Client: no
Server: That’s correct! Want another? (y/n)
y
Client: y
Server: What caused the craters on the moon?
asteroids
Client: asteroids
Server: Wrong, the correct answer is meteorites. Want another? (y/n)
n
Client: n
Server: Bye.
Eine in der Version 1.1 neue Einrichtung des AWT ist ein Mechanismus, der das Drucken von AWT-Komponenten und, bei AWT-basierten Applikationen, die Vergabe von Druckjobs an den lokalen Drucker plattformunabhängig ermöglicht.
Es gibt zwei wichtige AWT-Klassen, die für diese Möglichkeit des Druckens von ATW-Komponenten (eigentlich ist eine davon eine Schnittstelle) zuständig sind: PrintJob und PrintGraphics, die beide einen Bestandteil des java.awt-Pakets sind.
PrintJob ist dafür zuständig, einen bestimmten Druckjob zu starten, in die Warteschlange zu stellen und abzuschließen. Die PrintJob-Klasse startet die Ausgabe auf dem lokalen System (um, wenn möglich, den Druckdialog anzuzeigen), stellt Informationen über die Seitengröße und Auflösung bereit und beendet den Druckjob nach erfolgter Ausgabe. Um eine Instanz der PrintJob-Klasse zu erzeugen, müssen Sie zuerst eine Instanz des aktuellen Toolkits ermitteln und rufen dann von dieser Stelle aus die Methode getPrintJob() zur Erzeugung eines neuen PrintJob-Objektes auf. Als Argumente für die getPrintJob()-Methode benötigen Sie zum Drucken den Eltern-Frame, den Namen des Druckjobs und eine Liste von Eigenschaften (falls erforderlich). Mehr hierüber später.
Den zweiten Teil des Druckprozesses bildet die Schnittstelle PrintGraphics, die im allgemeinen innerhalb einer speziellen Version des Graphics-Objektes implementiert wird. So wie Sie mit dem standardmäßigen Grafikkontext Objekte auf dem Bildschirm zeichnen können, ermöglicht Ihnen dieser besondere Kontext zum Drucken der Grafik, Objekte auf einem Drucker auszugeben. Um ein PrintGraphics-Objekt zu benutzen, fordern Sie eines mit der PrintJob-Methode getGraphics() an und geben dieses Objekt dann an die Methode print() oder printAll() weiter, die für Component definiert wurden und deshalb zum Drucken einer gesamten Hierarchie von AWT-Komponenten verfügbar sind.
Um eine gesamte AWT-Benutzeroberfläche zu drucken, rufen Sie normalerweise printAll() auf. Die printAll()-Methode arbeitet dann wiederum die Komponentenhierarchie durch und ruft für jede einzelne Komponente print()auf. Die standardmäßige Ausführung von print() ruft lediglich paint() auf, die das, was am Bildschirm angezeigt wird, druckt. Wenn Sie die Druckeigenschaften erweitern oder überschreiben wollen, können Sie print() dementsprechend überschreiben. Beachten Sie, daß alle Standard-AWT-Komponenten auch standardmäßig gedruckt werden können, und Sie im allgemeinen daran nichts ändern müssen, es sei denn, Sie erstellen Ihre eigenen Komponenten.
Im einfachsten und normalsten Fall könnten Sie eine Schaltfläche oder ein Menüelement in Ihrer Anwendung erstellen, die/das dem Benutzer den Ausdruck des aktuellen Bildschirm ermöglicht. Um dies zu erreichen, verwenden Sie sowohl PrintJob als auch einen Kontext zum Drucken der Grafik. Listing 14.8 stellt ein Beispiel für den Ausdruck des aktuellen Fensters mit einer bestimmten Schaltfläche für Print Text dar.
Listing 14.8: Druckjob in die Warteschlange stellen
1: public void actionPerformed(ActionEvent e) {
2: if (e.getSource() instanceof Button) {
3: PrintJob job = getToolkit().getPrintJob(this, "Print Test",
4: (Properties)null);
5: if (job != null) {
6: Graphics pg = job.getGraphics();
7: if (pg != null) {
8: printAll(pg);
9: pg.dispose();
10: }
11: job.end();
12: }
13: }
14:}
Lassen Sie uns den Code durchgehen, damit Sie eine vage Vorstellung davon erhalten, was vor sich geht.
Die Zeilen 3 und 4 fordern von dem aktuellen Toolkit-Objekt der Anwendung einen aktuellen Druckjob an (das Toolkit-Objekt ist die zwischen den plattformübergreifenden Teilen Ihrer Anwendung und dem lokalen Fenster-Toolkit bestehende Verbindung). Die getPrintJob()-Methode löst im lokalen System die Anzeige eines Standard-Druckdialogs aus, damit Ihr Benutzer diesem Druckjob spezifische Eigenschaften zuordnen kann. Die getPrintJob()-Methode erhält drei Argumente:
Ist die Antwort des Benutzers an den Dialog OK oder Drucken (alles mit Ausnahme von Abbrechen), erhalten Sie eine Instanz von PrintJob und der Druck kann gestartet werden. Falls es sich der Benutzer anders überlegt und Abbrechen aus dem Dialog wählt, erhalten Sie ein null-Objekt, d.h. Sie müssen dies entsprechend prüfen bzw. testen (wie wir das in Zeile 5 gemacht haben).
Wenn das PrintJob-Objekt zur Verfügung steht, müssen Sie als nächsten Schritt den Kontext zum Drucken der Grafik holen. Sie können dies unter Verwendung der (Zeile 6) tun. Wenn alles funktioniert, erhalten Sie einen Drucken unterstützenden Grafikkontext, den Sie dann an die printAll()-Methode (Zeile 8) weitergeben können, der die Seite zum Drucken vervollständigt. Schließlich sendet die dispose()-Methode die Seite an den Drucker.
Um den Arbeitsgang abzuschließen, rufen Sie für den Druckjob end() auf, der für entsprechende Aufräumungsarbeiten nach erfolgtem Druck sorgt.
Detaillierte Informationen bezüglich Drucken im AWT finden Sie in den Druckspezifikationen unter http://java.sun.com/products/jdk/1.1/docs/guide/awt/designspec/printing.html.
Version 1.1 des AWT wurde in dem als Datenübertragung bezeichneten Bereich Unterstützung hinzugefügt: die Fähigkeit, Daten aus einer oder in eine Komponente und in andere Programme, die auf der systemeigenen Plattform laufen, unter Verwendung einer Zwischenablage auszuschneiden, zu kopieren oder einzufügen. Bisher ermöglichte Ihnen das AWT nur, Daten zwischen solchen Komponenten zu kopieren und einzufügen, in denen auf den systemeigenen Plattformen bereits grundlegende Fähigkeiten hierfür integriert waren (Text konnte beispielsweise zwischen Textfeldern und Textbereichen kopiert und eingefügt werden). Mit der Version 1.1 wird diese Fähigkeit so erweitert, daß auch andere Daten oder Objekte von einer Komponente in eine andere übertragen werden können.
Um Daten von einer Komponente in eine andere übertragen zu können, müssen Sie zuerst ein übertragbares Objekt definieren und dann Komponenten modifizieren oder erstellen, die die Fähigkeit besitzen, dieses Objekt zu übertragen.
Die Klassen und Schnittstellen hierfür sind im java.awt.datatransfer-Paket enthalten.
Ein austauschbares Objekt ist ein Objekt, das mit dem AWT-Datenübertragungsmechanismus von einer Komponenten in eine andere transportiert werden kann und eine bestimmte Menge von zu übertragenden Daten einkapselt (zum Beispiel formatierten Text). Genauer gesagt ist ein übertragbares Objekt ein Objekt, das die Transferable-Schnittstelle implementiert.
Wenn Sie ein übertragbares Objekt erstellen, müssen Sie als erstes entscheiden, welche »Flavors« das Objekt unterstützen soll. Ein Flavor ist im wesentlichen das Format der zu übertragenden Daten. Wenn Sie beispielsweise HTML-formatierten Text aus einem Browser kopieren und versuchen, ihn einzufügen, könnten die Daten in einem von mehreren unterschiedlichen Flavors eingefügt werden: als formatierter Text, als Klartext oder als HTML-Code. Daten-Flavors bestimmen, wie der Teil, von dem kopiert wird, und der Teil, in den eingefügt wird, verhandeln, wie die Daten selbst übertragen werden sollen. Wenn die Quelle und das Ziel der Datenübertragung nicht die gleiche Gruppe von Flavors unterstützen, können die Daten nicht übertragen werden.
Daten-Flavors werden durch MIME-Typen beschrieben, demselben Mechanismus, der von zahlreichen E-Mail-Programmen und dem World Wide Web selbst angewandt wird, um Inhalte zu kennzeichnen. Wenn Sie mit MIME-Typen nicht vertraut sind, können Sie in RFC 1521 die MIME-Spezifikation finden (es sollte Ihnen möglich sein, sich diese Spezifikation an jedem Web- oder FTP-Standort, der die verschiedenen Internet-RFC-Dokumente enthält, zu beschaffen, http://ds.internic.net/rfc/rfc1521.txt ist ein Beispiel hierfür). Zusätzlich zu dem logischen Flavor-Namen, hat das Daten-Flavor ebenfalls einen »benutzerlesbaren« Flavor-Namen, der für unterschiedliche internationale Sprachen entsprechend übersetzt werden kann. Daten-Flavors können außerdem eine entsprechende Java-Klasse haben – wenn beispielsweise das Daten-Flavor eine Unicode-Zeichenkette ist, würde die String-Klasse dieses Flavor repräsentieren. Wenn das Flavor keine es repräsentierende Klasse besitzt, wird die Klasse InputStream benutzt.
Um eine neues Daten-Flavor zu erstellen, erzeugen Sie eine neue Instanz von der DataFlavor-Klasse, indem Sie einen der beiden folgenden Konstruktoren verwenden:
Mit diesem DataFlavor-Objekt können Sie seine Werte abfragen oder MIME-Typen mit anderen DataFlavor-Objekten vergleichen, um die Übertragungsweise der Daten zu verhandeln.
Daten-Flavors werden von übertragbaren Objekten benutzt, die unter Verwendung der Transferable-Schnittstelle definiert werden. Ein übertragbares Objekt beinhaltet die zu übertragenden Daten und Instanzen jedes Daten-Flavors, das dieses Objekt repräsentiert. Darüber hinaus müssen Sie die Methoden getTransferDataFlavors(), isDataFlavorSupported() und getTransferData() implementieren, damit Ihr übertragbares Objekt auch effektiv verhandelt und übertragen werden kann (Einzelheiten hierzu finden Sie bei der Transferable-Schnittstelle).
Die Klasse StringSelection implementiert ein einfaches übertragbares Objekt zum Übertragen von Zeichenketten und verwendet dabei sowohl DataFlavor-Objekte als auch die Transferable-Schnittstelle. Wenn Sie hauptsächlich Text kopieren möchten, ist StringSelection hierfür die beste Stelle zum Ansatz (und möglicherweise das einzige übertragbare Objekt, das Sie effektiv benötigen). Eingehendes Untersuchen der Quelle der StringSelection-Klasse hilft Ihnen auch herauszufinden, auf welche Weise übertragbare Objekte arbeiten. (Sie können die Quelle mit dem JDK selbst finden, und sie ist ebenfalls in der Datenübertragungsspezifikation unter http://java.sun.com/products/jdk/1.1/docs/guide/awt/designspec/datatransfer.html) angegeben.
Beachten Sie, daß übertragbare Objekte zum Einkapseln von Daten und zur Bezeichnung seines Formats verwendet werden; sie führen in keinster Weise Formatierung dieser Daten durch. Dafür ist Ihr Programm zuständig, wenn Sie die Zwischenablage zur Einholung von Daten aus einer Quelle verwenden.
Nachdem Sie ein übertragbares Objekt erzeugt haben, können Sie eine Zwischenablage zur Übertragung dieses Objektes zwischen Komponenten und aus Java heraus auf die systemeigene Plattform verwenden. Java 1.1 bietet einen sehr leicht zu handhabenden Mechanismus für die Zwischenablage, der es Ihnen ermöglicht, Daten in die Zwischenablage zu stellen und Daten wieder aus dieser Zwischenablage zu laden. Sie können entweder eine einzelne Standardsystem-Zwischenablage verwenden, um Daten in andere und aus anderen Programmen, die auf der systemeigenen Plattform laufen, zu transportieren, oder Sie können Ihre eigenen Instanzen der Zwischenablage zur Erstellung besonderer Zwischenablagen oder mehrerer Gruppen von Spezialzwischenablagen verwenden.
In Java werden Zwischenablagen durch die Klasse Clipboard repräsentiert, die auch ein Bestandteil des java.awt.datatransfer-Pakets ist. Das Standardsystem Clipboard erhalten Sie durch Verwendung der Methoden getToolkit() und getSystemClipBoard() (wie Sie im letzten Abschnitt gelernt haben, bietet getToolkit() eine Möglichkeit, auf verschiedene systemeigene Fähigkeiten zuzugreifen) wie folgt:
Clipboard clip = getToolkit().getSystemClipboard()
Hier noch ein wichtiger Hinweis in bezug auf die Systemzwischenablage – aus Sicherheitsgründen können Applets derzeit nicht auf die Systemzwischenablage zugreifen (möglicherweise befinden sich sensitive Daten in dieser Zwischenablage). Dies hindert Applets daran, irgendwelche Daten in die oder von der systemeigenen Plattform zu kopieren oder einzufügen (mit Ausnahme der Fähigkeiten, die dort bereits vorhanden sind, wie Text innerhalb von Textfeldern und Textbereichen). Allerdings haben Sie die Möglichkeit, Ihre eigenen internen Zwischenablagen zum Kopieren und Einfügen zwischen Komponenten in einem Applet zu verwenden.
Jede Komponente, die Gebrauch von der Zwischenablage machen möchte – entweder um Daten unter Verwendung von Ausschneiden oder Kopieren in die Zwischenablage zu stellen, oder um Daten unter Verwendung von Einfügen aus der Zwischenablage zu holen –, muß die ClipboardOwner-Schnittstelle implementieren. Diese Schnittstelle verfügt über eine Methode: lostOwnership(), die aufgerufen wird, wenn eine andere Komponente die Kontrolle der Zwischenablage übernimmt.
Zur Durchführung von Ausschneiden oder Kopieren, d.h. um Daten in die Zwischenablage zu stellen, führen Sie folgende Schritte aus:
1. Erzeugen Sie eine Instanz Ihres Transferable-Objekts, um die zu kopierenden Daten zu speichern.
Um die Einfügen-Operation zu implementieren, d.h. Daten aus einer Zwischenablage entnehmen, führen Sie die folgenden Schritte aus:
1. Benutzen Sie die getContents()-Methode der Zwischenablage, die ein übertragbares Objekt ausgibt.
Hier ein sehr einfaches Anwendungsbeispiel, in dem die Zwischenablage zum Kopieren von Text aus einem Textfeld in ein anderes benutzt wird (wie in Abbildung 14.3 gezeigt). Listing 14.9 führt den Code für dieses Beispiel auf.
|
Abbildung 14.3:
|
Listing 14.9: Kopieren und Einfügen
1: import java.awt.*;
2: import java.awt.event.*;
3: import java.awt.datatransfer.*;
4:
5: public class CopyPaste extends Frame
6: implements ActionListener, ClipboardOwner {
7: Button copy, paste;
8: TextField tfcopy, tfpaste;
9: Clipboard clip;
10:
11: public static void main(String[] arg) {
12: CopyPaste test = new CopyPaste();
13: test.setSize(200,150);
14: test.show();
15: }
16:
17: CopyPaste() {
18: super("Copy and Paste");
19: clip = getToolkit().getSystemClipboard();
20: setLayout(new FlowLayout());
21:
22: copy = new Button("Copy From");
23: copy.addActionListener(this);
24: add(copy);
25:
26: tfcopy = new TextField("", 25);
27: add(tfcopy);
28:
29: paste = new Button("Paste To");
30: paste.addActionListener(this);
31: paste.setEnabled(false);
32: add(paste);
33:
34: tfpaste = new TextField("",25);
35: add(tfpaste);
36: }
37:
38: public void actionPerformed(ActionEvent e) {
39: if ((e.getSource() == copy) &&
40: (tfcopy.getText() != null)) {
41: String txt = tfcopy.getText();
42: StringSelection trans = new StringSelection(txt);
43: clip.setContents(trans,this);
44: paste.setEnabled(true);
45: }
46: else if (e.getSource() == paste) {
47: Transferable topaste = clip.getContents(this);
48: if (topaste != null) {
49: try {
50: String txt = (String)topaste.getTransferData(
51: DataFlavor.stringFlavor);
52: tfpaste.setText(txt);
53: paste.setEnabled(false);
54: }
55: catch (Exception except) {
56: System.out.println("Can't get data.");
57: }
58: }
59: }
60: }
61:
62: // muß cliboardowner-Schnittstelle genügen
63: public void lostOwnership(Clipboard clip, Transferable contents) {
64: }
65:}
Folgendes ereignet sich in dieser Anwendung (und beachten Sie, daß dies eine Anwendung und kein Applet ist):
Internationalisierung steht für den Prozeß der Erstellung einer Anwendung oder von Teilen einer Anwendung, die leicht übersetzbar sind oder von anderen Kulturen und Sprachen als der englischen verwendet werden. Für die größte Anzahl von Programmen – geschrieben in einer beliebigen Programmsprache – gilt, daß sich die Übersetzung in eine andere Sprache als schwierig erweist. Zeichenketten für Schaltflächenbeschriftungen werden häufig in das Programm kompiliert. Auch die Formatierung von Datum und Zahlen stellt sich im Englischen besonders dar. Für diese Art von Programmen muß der Programmcode normalerweise manuell von einem Programmierer in dem Bestimmungsland »übersetzt« werden, damit die Anwendung in diesem Land verstanden werden kann. Diesen Prozeß der Konvertierung eines Programmes nennt man Lokalisierung.
Obgleich die Lokalisierung eines Programmes durch die entsprechende Übersetzung ausreichend gut funktioniert, stellt sie dennoch viel Arbeit für den Übersetzer dar, und das Resultat sind schließlich verschiedene Versionen desselben Programms für unterschiedliche Sprachen und Kulturen (und bei Änderungen des ursprünglichen Programms werden umfangreiche Pflegemaßnahmen erforderlich). Die Programmübersetzer eines Programms hätten eine wesentlich leichtere Aufgabe, wenn man gleich zu Beginn der Entwicklung des Programms die sprach- und kulturspezifischen Teile des Programms von den anderen Teilen dieses Programms trennen könnte. Mit einer solchen Trennung könnte sich die Lokalisierung so einfach wie die Änderungen einiger Zeichenketten gestalten.
Diese Trennung von sprach- und kulturspezifischen Teilen von anderen Teilen eines Programmes nennt man Internationalisierung und Java 1.1 beinhaltet Möglichkeiten, die Erstellung internationaler Programme zu erleichtern. Wenn Sie in einer Umgebung arbeiten, in der Ihr Java-Code möglicherweise in anderen Ländern verwendet wird, werden Sie diese von Java gebotenen Möglichkeiten sicherlich gern einsetzen wollen. Deshalb ist es gut, bei jedem Programmentwurf vorauszuplanen und zu bedenken, wann und wo Ihre Code eingesetzt werden wird.
Einige Teile von Java sind bereits international – zum Beispiel der von Java verwendete Unicode-Zeichensatz, der Ihnen die Darstellung einer großen Vielfalt an internationalen Zeichen ermöglicht. Bei anderen Teilen haben Sie allerdings lediglich die Möglichkeit, zwischen verschiedenen Sprachen und Kulturen umzuschalten und Formate auf vielfältige unterschiedliche Weisen zu formatieren.
Sowohl die Internationalisierung als auch Lokalisierung benutzen das Konzept einer Locale, um auf eine spezifische Gruppe von sprachlichen oder kulturellen Unterschieden hinzuweisen. Ein Locale muß nicht unbedingt eine Sprache wie Französisch oder Deutsch sein, obwohl diese Sprachen definitiv Locales sind. Eine Locale kann ebenso auf eine unterschiedliche Kultur hindeuten. Britisches Englisch bedient sich beispielsweise einer anderen Formatierung von Zahlen und Datumsangaben als amerikanisches Englisch. Deshalb ist britisches Englisch eine Locale.
Bei der Erstellung eines internationalen Programms, müssen Sie die aktuelle Locale und die Gruppe von Locales, die dieses Programm unterstützt, definieren. Jedes Mal, wenn das Programm dann eine Aktion ausführt, die in einer anderen Locale unterschiedlich sein kann – die Benutzung von Zeichenketten, Fehlermeldungen, was und wie Sie drucken –, erfolgt dies auf der Grundlage dieser aktuellen Locale. Diese Architektur gestaltet nicht nur das Umschalten zwischen unterstützten Locales einfach, sondern vereinfacht auch im Bedarfsfall die Eingliederung einer neuen Locale. Beachten Sie also, daß Locales nicht notwendigerweise global für das gesamte Programm gelten – unterschiedliche Teile des Programms können unterschiedliche aktuelle Locales haben.
Locales werden in Java 1.1 durch die Klasse Locale, einem Teil des java.util-Pakets, definiert und wann immer Sie auf eine Locale in Ihrem Programm Bezug nehmen, sollten Sie Instanzen dieser Klasse verwenden. Die Locale-Klasse ist einfach ein Feldname für eine spezifische Locale, die einen ISO-Standardmechanismus zur Bezeichnung verschiedener Locales, die spezielle Codes für das Land, die Sprache und für beliebige andere Varianten benutzen, einsetzt. Tabelle 14.1 zeigt die Codes für verschiedene Sprachen und Länder.
Tabelle 14.1: Internationale Sprach- und Ländercodes
|
Locale |
Sprache |
Land |
|
da_DK |
Dänisch |
Dänemark |
|
DE_AT |
Deutsch |
Österreich |
|
DE_CH |
Deutsch |
Schweiz |
|
DE_DE |
Deutsch |
Deutschland |
|
el_GR |
Griechisch |
Griechenland |
|
en_CA |
Englisch |
Kanada |
|
en_GB |
Englisch |
Groß Britannien |
|
en_IE |
Englisch |
Irland |
|
en_US |
Englisch |
USA |
|
es_ES |
Spanisch |
Spanien |
|
fi_FI |
Finnisch |
Finnland |
|
fr_BE |
Französisch |
Belgien |
|
fr_CA |
Französisch |
Kanada |
|
fr_CH |
Französisch |
Schweiz |
|
fr_FR |
Französisch |
Frankreich |
|
it_CH |
Italienisch |
Schweiz |
|
it_IT |
Italienisch |
Italien |
|
ja_JP |
Japanisch |
Japan |
|
ko_KR |
Koreanisch |
Korea |
|
nl_BE |
Holländisch |
Belgien |
|
nl_NL |
Holländisch |
Niederlande |
|
no_NO |
Norwegisch (Nynorsk) |
Norwegen |
|
no_NO |
B Norwegisch (Bokmål) |
Norwegen |
|
pt_PT |
Portugiesisch |
Portugal |
|
sv_SE |
Schwedisch |
Schweden |
|
tr_TR |
Türkisch |
Türkei |
|
zh_CN |
Chinesisch (vereinfacht) |
China |
|
zh_TW |
Chinesisch (traditionell) |
Taiwan |
Glücklicherweise enthält die Locale-Klasse mehrere Klassenvariablen, die viele der allgemeineren Locales beinhalten, so daß Sie häufig einfach nur diese Variablen in Ihrem Programmen verwenden müssen. Allgemeine Locales könnten sein Locale.US, Locale.UK, Locale.JAPAN, Locale.FRENCH usw. (weitere Einzelheiten über die Locale-Klasse finden Sie in der API-Dokumentation).
Die aktuelle Locale für jeden Teil Ihres Programms können Sie entweder selbst herausfinden oder hierfür die Component-Methode getLocale()oder setLocale() zum Einrichten dieser Locales benutzen (beachten Sie, daß bei getLocale() und setLocale() unterschiedliche Komponenten unterschiedliche Locales haben können). Die Locale per Voreinstellung ist Locale.ENGLISH.
Das Locale-Objekt ist einfach der schnelle Weg, eine bestimmte Locale zu identifizieren. Schwierig wird es dann, wenn Sie diese Locale dazu benutzen, die Art der Anzeige und Formatierung verschiedener Teile des Programmes festzulegen. Für die Art und Weise, in der Locale-spezifische Daten benutzt werden, gibt es zwei übergreifende Themen:
Resource Bundles sind eine Form der Strukturierung von Zeichenketten in Ihrem Programm, wobei verschiedene Zeichenketten für unterschiedliche Locales verwendet werden. Eine bestimmte Schaltfläche könnte beispielsweise eine Beschriftung in Englisch, in Französisch, in Deutsch usw. haben.
Resource Bundles werden als Subklassen der ResourceBundle-Klasse (Teil von java.util) implementiert und mit dem Standard-Klassenladeprogramm in ein Java-Programm geladen. Die eigentlichen Dateinamen der Resource Bundles leiten sich aus einem Bundle-Namen her (zum Beispiel »Labels«, »Meldungen«, »Fehler«, »Menüpunkte« oder aus irgend etwas anderem, das Sie verwenden möchten) mit lokalen Codes für die Sprache, das Land und, falls vorhanden, die Variante, die an den Namen mit Unterstrichen angehängt sind, beispielsweise wäre labels_en_US der Dateiname für amerikanisches Englisch, labels_DE für Deutsch oder labels_fr_CA für kanadisches Französisch. Die Codes für die Sprache, das Land und die Variante sind, wie für die Klasse Locale, durch einen ISO-Standard definiert. Um ein bestimmtes Bundle zu laden, benutzen Sie die Methode ResourceBundle.getResourceBundle()mit dem Namen des Bundle, der Locale und der aktuell geladenen Klasse.
Locale-spezifische Ressourcen werden innerhalb der eigentlichen Bundles gespeichert und entsprechender Zugriff ist über verschiedene, von ResourceBundle definierte Methoden möglich, wie beispielsweise getString(), getObject(), getMenu() usw.
Hier ist beispielsweise ein einfacher Code, der ein Resource Bundle für die aktuelle Locale lädt (und dabei getLocale() zur Bestimmung dieser Locale verwendet) und anschließend drei Schaltflächen mit in diesen Bundles gespeicherten Beschriftungen erstellt:
Locale currentLocale = getLocale();
ClassLoader loader = this.getClass().getClassLoader();
ResourceBundle labels = ResourceBundle.getResourceBundle("Labels",
currentLocale, loader);
Button ok = new Button(labels.getString("label1");
Button cancel = new Button(labels.getString("label2");
Um ein Resource Bundle zu erstellen, erzeugen Sie eine Subklasse von ResourceBundle und führen die Methode handleGetObject() aus. Resources werden im allgemeinen als Schlüsselwertpaare gespeichert und das Argument für handleGetObject() muß der Name eines Schlüssels sein. Wie Sie diese Resources in dieser Klasse speichern bleibt Ihnen überlassen.
Ein allgemein üblicher Weg Ressourcen zu speichern, könnte einfach die Speicherung als ein Array von Schlüsselwertpaaren sein, wodurch erneutes Laden der Resources mit dem Schlüssel leichtgemacht wird. Da dieser Mechanismus sehr geläufig ist, bietet Java 1.1 genau für diesen Zweck eine Klasse: ListResourceBundle. Um Ihre eigenen Resources Bundles zu erstellen, erzeugen Sie einfach eine Subklasse von ListResourceBundle, definieren die Resources als ein zweidimensionales Array und überschreiben die Methode getContents(), um auf dieses Array hinzuweisen. Hier ein einfaches Beispiel für die zwei von mir im vorigen Beispiel benutzten Schaltflächen:
import java.util.*;
class Labels extends ListResourceBundle {
public Object[][] getContents() {
return contents;
}
static final Object[][] contents = {
{"label1", "OK,"},
{"label2", "Cancel,"}
};
}
Zum Lokalisieren dieser Ressourcen müssen Sie lediglich die Klassen mit den korrekten Locale-Codes umbenennen und dann die Zeichenketten »OK« und »Cancel« in die aktuelle Sprache übersetzen. Der Code zum Lesen des ResourceBundle und zur Erstellung der Schaltflächen übernimmt die restlichen Aufgaben.
Beachten Sie, daß obgleich in diesem Beispiel das Bundle Zeichenketten beinhaltete, die ResourceBundle-Klasse derart konzipiert ist, daß die Werte für jeden Schlüssel ein beliebiges Java-Objekt sein können. Sie könnten beispielsweise die Schaltflächen selbst in dem Resources Bundle erstellen und sie dann einfach laden und im Hauptcode verwenden.
Verschiedene Locales können auch die Art der Formatierung von Zahlen, Datumsangaben und anderen Meldungen festlegen. Java 1.1 bietet zur Handhabung internationaler Formatierungsfragen im java.text eine Gruppe von Klassen zur Handhabung der Formatierung. Die besonders nützlichen Klassen sind DecimalFormat, DateFormat und MessageFormat.
NumberFormat wird auf unterschiedliche Weise zur Formatierung von Zahlen benutzt: für Währungseinheiten, Prozentsätze, ob Kommata bei Tausendern gesetzt werden, Plus- oder Minuszahlen, usw.
Um eine bestimmte Zahl zu formatieren, erstellen Sie, basierend auf der Locale und dem speziellen, von Ihnen gewünschten Format ein Formatierungsobjekt und benutzen dann zur Konvertierung eines Wertes in die korrekt formatierte Zeichenkette die format()-Methode von diesem Objekt. Hier ein Beispiel zum Drukken einer Währungseinheit, in diesem Fall Französische Franc:
NumberFormat cfmt = NumberFormat.getDefaultCurrency(Locale.FRENCH)
System.out.println("Taxes Withheld: " + cfmt.format(taxes);
Die Formatierung von Datum und Zeit erfolgt auf sehr ähnliche Weise, mit der Ausnahme, daß die Formatierungsklasse entweder DateFormat oder SimpleDate-Format ist. Letztere ist einfacher zu benutzen und ermöglicht es Ihnen, die Ausgabe gemäß einer speziellen Form festzulegen, nehmen wir beispielsweise an, es sollen anstatt des kompletten Datums nur Stunden und Minuten gedruckt werden:
DateFormat tfmt = DateFormat.getDateFormat(
DateFormat.DEFAULT, Locale.FRANCE);
tfmt.setPattern("hh:mm", false);
System.out.println("Time:" + fmt.format(System.currentTimeMillis()));
Die Formatierung von Meldung ist etwas komplexer. Meldungsformatierung wird für Zeichenketten benutzt, die zur Laufzeit aus mehreren verschiedenen Werten aufgebaut wird, zum Beispiel »Die Verarbeitung ist zu 50% abgeschlossen,« oder »Der Code YourFile.java hat 14 Fehler«. Das Problem der Meldungen besteht darin, daß in unterschiedlichen Sprachen mit unterschiedlicher Reihenfolge von Substantiv und Pronomen, die verschiedenen Werte an unterschiedlichen Stellen in der Meldung erscheinen können, was es recht schwierig gestaltet, die verschiedenen Teile der Zeichenkette einfach in eine Resource-Datei zu ziehen.
Meldungsformate umgehen dieses Problem durch Benutzung einer einzelnen Zeichenkette mit auszutauschenden Schemata, ähnlich der Art und Weise wie printf()in C und C++ arbeitet. Das Meldungsschema kann für jede Locale ausgetauscht werden (es kann in einem Resource Bundle gespeichert werden) und die tatsächlichen Werte können dann in unterschiedlicher Reihenfolge für unterschiedliche Schemata eingesetzt werden. Hier ein Beispiel:
Object vals[] = new Object[3];
vals[0] = 4;
vals[1] = 56;
vals[2] = "Disk 3";
MessageFormat mfmt = new MessageFormat(
"%0 files on %2 were processed in %1 seconds."_;
System.out.println(mfmt.format(vals, mfmt, null));
mfmt.setPattern("Disk: %2 Files: %0 Time Elapsed: %1");
System.out.println(mfmt.format(vals, mfmt, null));
Mit dem Thema Internationalisierung sind wir in diesem Abschnitt nur ganz leicht in Berührung gekommen; Java 1.1 enthält eine Vielzahl unterschiedlicher Mechanismen zur Handhabung anderer Punkte der Internationalisierung, einschließlich der Sortierreihenfolge für Zeichenketten, Zeichensatzkonvertierungen, Font-Unterstützung für Unicode-Zeichen und eine Reihe anderer Merkmale. Falls Sie weitere Informationen über das Erstellen internationaler Programme wünschen, bietet Ihnen SUN eine umfangreiche Spezifikation über Internationalisierung als Teil der Dokumentation für das 1.1-JDK. Sie können es online durchblättern unter http://java.sun.com/products/jdk/1.1/docs/guide/intl/.
Die Freigabe von Java 1.1 beinhaltet eine Anzahl fortgeschrittenerer Features, die es ermöglichen, Java zum Aufbau großangelegter Anwendungen außerhalb des Rahmens von Applets und Web-Browsern einzusetzen. Diese fortgeschritteneren Eigenschaften verleihen Java und seinen unterstützenden Klassen größere Leistungsfähigkeit und Flexibilität, sind allerdings auch äußerst komplex.
Während Sie sich zu einem fortgeschritteneren Java-Programmierer entwickeln und insbesondere, wenn Sie planen, mit Java-Programmieren Ihren Lebensunterhalt zu verdienen, müssen Sie sich höchstwahrscheinlich mit einigen – oder allen – dieser fortgeschritteneren Eigenschaften befassen. Da es sich bei diesem Buch eher um eine Einführung in die Materie handelt, werde ich lediglich den Verwendungszweck jeder dieser Eigenschaften zusammenfassen, anstatt ins Detail zu gehen. Morgen, wenn Sie Ihre dritte Woche beginnen, werden wir auf die Sprache selbst zurückkommen.
Die fortgeschritteneren Java-Eigenschaften, die ich heute beschreiben möchte, sind:
Schon seit geraumer Zeit verfolgt die Gemeinde der Software-Entwicklung verstärkt den Gedanken wiederverwendbarer Komponenten. Eine Komponente – im allgemeinen Sinn, nicht im Sinne des AWT – ist ein wiederverwendbares Software-Teil, das leicht zur Erstellung von Anwendungen verwendet werden kann, und zwar mit weitaus größerer Entwicklungseffizienz. Dieser Gedanke der Wiederverwendung sorgfältig zusammengestellter Software wurde zu einem gewissen Maße dem Verfahren des Montagebandes entliehen, das während der industriellen Revolution in den Vereinigten Staaten, lange vor der Ära moderner Computer, so populär wurde. Auf Software angewandt bedeutet das, einmalig zu Beginn kleine, wiederverwendbare Komponenten zu bauen und sie dann in höchstmöglichem Maße wiederzuverwenden und damit den gesamten Entwicklungsprozeß zu rationalisieren.
Obwohl Komponenten-Software ihre Vorteile bietet, muß sich die vollständig wiederverwendbare Software erst noch richtig etablieren. Dies aus einer Vielzahl von Gründen, nicht zuletzt der Tatsache, daß die Software-Industrie im Vergleich zu den Industrien, die sich während der industriellen Revolution etabliert haben, noch sehr jung ist. Es leuchtet ein, daß es einige Zeit dauert, die schwachen Punkte im gesamten Software-Produktionsprozeß auszumerzen. (Wenn Sie meine Einstellung teilen, nehmen Sie die rapiden, in der Welt der Software stattfindenden Veränderungen bereitwillig an und genießen die Tatsache, daß Sie ein Teil von so etwas ähnlichem wie einer Revolution sind – eine Informationsrevolution. Aber ich schweife ab!)
Das vielleicht größte Problem dem sich Komponenten-Software stellen mußte, ist der große Bereich ungleichartiger Mikroprozessoren und heute eingesetzter Betriebssysteme. Es gab eine Reihe angemessener Versuche in der Komponenten-Software, die aber immer auf ein spezifisches Betriebssystem limitiert waren. Die VBX- und OCX-Komponentenarchitekturen von Microsoft verzeichneten große Erfolge in der Welt des PC, konnten aber wenig zum Schließen der Lücke zwischen anderen Betriebssystemtypen beitragen. Wirft man das Arbeitsvolumen in die Waagschale, daß dazu benötigt wird, um eine inhärente, plattformabhängige Komponententechnologie auf einer Vielzahl von Betriebssystemen zum Laufen zu bringen, macht die ausschließliche Fokussierung auf den PC-Markt von Microsoft Sinn.
Bevor es zur der explosionsartigen Entwicklung im Internet-Bereich kam, stellte die Plattformabhängigkeit nicht so ein großes Problem dar. PC-Entwickler machten sich nicht unbedingt allzu viele Gedanken darum, daß ihre Produkte nicht auf einem Solaris-System laufen konnten. Okay, einige PC-Entwickler gingen auf Nummer sicher und sorgten für Anschluß Ihrer Anwendungen an die Macintosh-Plattform, allerdings oftmals unter beträchtlichem Entwicklungsaufwand. Das gesamte Szenario änderte sich durch den vom Internet erzeugten Schmelztiegel der Betriebssysteme. Daraus ein erneutes Interesse, Software zu entwickeln, die von jedermann, unabhängig vom benutzten Betriebssystem, benutzt werden kann. Java trug in großem Maße dazu bei, echt plattformunabhängige Software-Entwicklung Wirklichkeit werden zu lassen. Allerdings hatte Java bis vor kurzem keine Antwort auf das Problem der Komponenten-Software – dazu kommen wir gleich.
Als ob das Problem der Plattformabhängigkeit noch nicht genug war, leiden einige verfügbare Komponententechnologien darunter, in einer spezifischen Programmiersprache oder für eine spezielle Umgebung entwickelt werden zu müssen. So wie die Plattformabhängigkeit Komponenten zur Laufzeit verkrüppelt, führt Limitierung der Komponentenentwicklung auf eine spezifische Programmiersprache oder Entwicklungsumgebung gleichermaßen zur Verkrüpplung der Komponenten im Entwicklungsbereich. Software-Entwickler würden lieber selbst entscheiden, welche Sprache für eine bestimmte Aufgabe und welche Entwicklungsumgebung die am besten geeignete ist, als gezwungen zu sein, eine den Einschränkungen einer Komponententechnologie unterliegende zu verwenden. Demnach muß sich jede realistische, auf lange Sicht ausgerichtete Komponententechnologie dem Problem der Plattform- und Sprachabhängigkeit stellen. Und das bringt mich zu unserem Thema: JavaBeans. Die JavaBeans-Technologie von JavaSoft ist eine Komponententechnologie, die direkte Antworten auf beide Probleme bietet. Die JavaBeans-Technologie verspricht das Paradigma der Zusammenfügung von Komponenten-Software auf eine neue Ebene zu heben. Im Augenblick befindet sich die JavaBeans-Spezifikation in der Entwicklung und die vorläufige Freigabe soll im Anschluß daran erfolgen.
JavaBeans wird als architektur- und plattformunabhängiges API zur Erstellung und Verwendung dynamischer Java-Software-Komponenten realisiert. JavaBeans setzt an dem Punkt an, wo andere Komponententechnologien aufgehört haben, und verwendet die portable Java-Plattform als Basis zur Bereitstellung einer kompletten Lösung für Komponenten-Software, die in der Welt des Online ohne weiteres anwendbar ist.
Nach dem schnellen Erfolg des Laufzeitsystems und der Programmiersprache von Java, war JavaSoft die Bedeutung der Entwicklung einer kompletten Lösung für die Komponententechnologie klar. Man antwortete mit der JavaBeans-Technologie, deren Designziele in folgender Spezifikationsliste zusammengefaßt werden können:
Die erste Anforderung von JavaBeans – so kompakt zu sein – beruht auf der Tatsache, daß die JavaBeans-Komponenten häufig in verteilten Umgebungen verwendet werden, in denen komplette Komponenten eventuell über eine Internet-Verbindung mit geringer Bandbreite übertragen werden. Genauer gesagt müssen Komponenten so kompakt wie möglich sein, um eine angemessene Übertragungszeit zu ermöglichen. Der zweite Teil dieses Designziels bezieht sich auf die Leichtigkeit, mit der diese Komponenten erstellt und verwendet werden. Leicht verwendbare Komponenten kann man sich relativ leicht vorstellen, aber die Erzeugung einer Komponentenarchitektur, die das Erstellen von Komponenten leicht gestaltet, ist eine völlig andere Sache. Versuche auf der Ebene der Komponenten-Software werden dem Entwickler oftmals durch komplexes Programmieren von APIs erschwert. JavaBeans-Komponenten müssen also nicht nur leicht zu verwenden, sondern auch leicht zu entwickeln sein. Dies stellt für Sie und mich eine wesentliche Anforderung dar, da sie weniger Kopfschmerzen bereitet und uns mehr Zeit gibt, die Komponenten mit blumigen Eigenschaften auszuschmükken.
JavaBeans-Komponenten basieren größtenteils auf der bereits in der traditionellen Applet-Programmierung von Java verwendeten Klassenstruktur, was wiederum für diejenigen von uns, die viel Zeit und Energie darauf aufwenden, Java zu erlernen, einen enormen Vorteil bietet. JavaSoft hat versprochen, daß die rund um das AWT-Paket entworfenen Java-Applets sich größenmäßig leicht an die neuen JavaBeans-Komponenten anpassen lassen. Auch dies leistet den positiven Nebeneffekt der ausgesprochenen Kompaktheit von JavaBeans-Komponenten, da Java-Applets hinsichtlich der Größe bereits sehr leistungsfähig sind.
Das zweite Hauptziel von JavaBeans ist vollständige Portabilität; darüber haben wir zu Beginn dieser Lektion gesprochen. JavaSoft befindet sich in der abschließenden Phase eines JavaBeans-API, das eine Definition des spezifischen Komponentenrahmens für JavaBeans-Komponenten liefert. Aus diesem JavaBeans-API und dem plattformunabhängigen Java-System, auf dem es basiert, wird sich die plattformunabhängige Komponentenlösung zusammensetzen. Als Folge davon brauchen sich Entwickler keine Gedanken um die Einbeziehung plattformspezifischer Bibliotheken bei Ihren Java-Applets zu machen. Das Ergebnis sind wiederverwendbare Komponenten, die die Computerwelt glücklich und friedlich unter einem Dach vereinigen. (Okay, vielleicht ist das etwas zu viel verlangt – ich begnüge mich schon mit der Entwicklung einer Komponente, die ohne Anbringen von Modifizierungen auf einem Java-unterstützten System läuft.)
Die bestehende Java-Architektur bietet bereits eine große Anzahl von Vorteilen, die leicht auf Komponenten anwendbar ist. Eine der wesentlicheren Eigenschaften von Java ist ihr eingebauter Klassenerkennungsmechanismus, der dynamische Interaktionen zwischen Objekten ermöglicht. Daraus entsteht ein System, in dem sich Objekte unabhängig von ihrem Ursprung oder ihrer Entwicklungsgeschichte ineinander einbauen lassen. Dieser Mechanismus zur Klassenauffindung stellt nicht nur eine nette Eigenschaft von Java dar, sondern ist in jeder Komponentenarchitektur eine notwendige Voraussetzung und für JavaBeans ein Glücksfall, daß diese Funktionalität von Java bereits kostenlos geboten wird. Andere Komponentenarchitekturen mußten vertrackte Registriermechanismen implementieren, um zu dem gleichen Ergebnis zu kommen.
Darüber hinaus erhält JavaBeans aus der bestehenden Java-Funktionalität noch die Persistence, d.h. die Fähigkeit eines Objektes, seinen internen Status zu speichern und wieder zu laden. Diese Persistence erfolgt in JavaBeans automatisch einfach durch die Verwendung des in Java bereits vorhandenen Serialisation-Mechanismus. Falls erforderlich, können Entwickler alternativ speziell angepaßte Persistence-Lösungen erstellen.
Obwohl kein Schlüsselelement der JavaBeans-Architektur, stellt die Unterstützung für verteiltes Rechnen bei JavaBeans dennoch ein Hauptthema dar. Da verteiltes Rechnen, als ein Ergebnis der komplexen Natur der verteilten Systeme, relativ komplexe Lösungen erforderlich macht, hebt JavaBeans die Verwendung von externen verteilten, auf Bedarf basierten Methoden an. Anders ausgedrückt ermöglicht JavaBeans Entwicklern die Verwendung verteilter Rechenmechanismen, wann immer erforderlich, überlädt sich aber auch nicht mit entsprechender Unterstützung für verteiltes Rechnen. Mann könnte jetzt die JavaBeans-Architekten für faul halten, Tatsache ist aber, daß genau in diesem Designansatz der Schlüssel für die Kompaktheit der JavaBeans-Komponenten liegt, da verteilte Rechenlösungen unvermeidlich zu höherer Systemverwaltungszeit führen.
Entwickler von JavaBeans-Komponenten haben die Möglichkeit, die für ihre Bedürfnisse am besten geeignete Methode auszuwählen. Mit seiner Technologie der Remote Method Invocation (RMI) (Methoden-Fernaufruf) bietet JavaSoft eine verteilte Rechenlösung, die aber den JavaBeans-Entwicklern keinesfalls die Hände bindet. Unter anderem beinhalten andere Lösungsmöglichkeiten CORBA (Common Object Request Broker Architecture) und von Microsoft DCOM (Distributed Component Object Model). Der Punkt ist, daß verteiltes Rechnen säuberlich von JavaBeans abgetrennt wurde, um die Struktur straff zu halten und gleichzeitig Entwicklern, die verteilte Unterstützung benötigen, eine breiten Bereich an Optionen zu bieten. Das letzte Designziel von JavaBeans behandelt Probleme der Entwicklungszeit und die Art und Weise, wie Entwickler Anwendungen unter Verwendung von JavaBeans-Komponenten erstellen. Die Architektur von JavaBeans umfaßt Unterstützung für die Spezifizierung von Eigenschaften der Entwicklungszeit und Bearbeitungsmechanismen zur weiteren Erleichterung visueller Bearbeitung von JavaBeans-Komponenten. Das hat zur Folge, daß Entwickler visuelle Werkzeuge zum nahtlosen Zusammenfügen und Modifizieren von JavaBeans-Komponenten einsetzen können, ganz ähnlich der Weise, in der bestehende visuelle PC-Werkzeuge mit Komponenten wie VBX- oder OCX-Steuerungen arbeiten. Komponentenentwickler spezifizieren so die Art und Weise, in der die Komponenten in einer Entwicklungsumgebung zu verwenden und zu manipulieren sind. Allein diese Eigenschaft wird offiziell die Verwendung von professionellen visuellen Editoren einleiten und der Produktivität von Anwendungsentwicklern in bedeutender Weise Auftrieb verleihen.
Für viele Entwickler, die nicht ganz mit dem Gedanken von Software-Komponenten vertraut sind, wird die Beziehung zwischen JavaBeans und Java etwas verwirrend sein. Wurde für Java nicht als eine objektorientierte Technologie mit der Fähigkeit, wiederverwendbare Objekte zu bedienen, die Werbetrommel geschlagen? Ja oder nein. Ja, Java bietet eine Möglichkeit der Erstellung wiederverwendbarer Objekte, allerdings gibt es einige Regeln oder Standards, die für die Art und Weise wie Objekte miteinander interagieren maßgeblich sind. Durch Spezifizieren umfangreicher Gruppen von Mechanismen für die Interaktion zwischen Objekten, zusammen mit allgemeinen, von den meisten Objekten zu unterstützende Aktionen wie Persistenz- und Ereignishandhabung, baut JavaBeans auf dem bestehenden Design von Java auf.
Das aktuelle Java-Komponentenmodell ist, obgleich es nicht schlecht ist, relativ limitiert, wenn es darum geht, echte Wiederverwendung und Interoperabilität zu liefern. Auf der Objektebene gibt es definitiv keinen einfachen Mechanismus zur Erstellung wiederverwendbarer Java-Objekte, die mit anderen Objekten dynamisch in konsequenter Weise in Wechselwirkung treten können. Was Sie dem am nächsten kommend in Java durchführen können, ist, Applets zu erstellen und zu versuchen, diese auf einer Webseite miteinander kommunizieren zu lassen, was nicht gerade eine leichte Aufgabe ist. JavaBeans stellt den Rahmen, in dem diese Kommunikation stattfinden kann, mit Leichtigkeit zur Verfügung. Noch wichtiger ist die Tatsache, daß JavaBeans-Komponenten leicht über eine Standardgruppe von gut definierten Eigenschaften getriggert werden können. JavaBeans vereinigt die Leistungsstärke eines voll ausgereiften Java-Applet mit der Kompaktheit und Wiederverwendbarkeit von Java-AWT-Komponenten, wie beispielsweise Schaltflächen.
JavaBeans-Komponenten sind jedoch nicht auf visuelle Objekte wie Schaltflächen beschränkt. Sie können genauso einfach nicht visuelle JavaBeans-Komponenten entwickeln, die zusammen mit anderen Komponenten einige Hintergrundfunktionen ausüben. Auf diese Weise vereinigt JavaBeans die Leistungsstärke visueller Java-Applets mit nicht visuellen Java-Anwendungen unter dem festen Dach eines Komponentenrahmens.
Sie können eine Vielzahl von JavaBeans-Komponenten gemeinsam benutzen, ohne daß Sie unter Verwendung visueller Werkzeuge einen Code schreiben müssen. Diese Möglichkeit der gleichzeitigen Benutzung einer Vielzahl von Komponenten, deren Ursprung dabei unwichtig ist, stellt eine Verbesserung des aktuellen Java-Modells dar. Sicherlich können Sie andere, in Java bereits integrierte Objekte benutzen, müssen aber über ausführliches Wissen, die Schnittstelle des Objektes betreffend, verfügen. Darüber hinaus müssen Sie das Objekt programmatisch in Ihren Code integrieren. JavaBeans-Komponenten legen ihre eigenen Schnittstellen visuell dar und stellen somit ein Mittel zur Bearbeitung ihrer Eigenschaften ohne Programmierung bereit. Des weiteren können Sie mit der Verwendung eines visuellen Editors eine JavaBeans-Komponente einfach in eine Anwendung einfügen, ohne daß Sie eine einzige Zeile Code schreiben müssen. Hier sehen wir eine vollständig neue Ebene der Flexibilität und Wiederverwendung, die mit Java allein bisher nicht möglich war.
Okay, genug gesagt über JavaBeans und darüber, was es kann und warum es »cool« ist. Konzentrieren wir uns jetzt auf einige Einzelheiten, um festzustellen, wie das alles möglich ist. Behalten Sie dabei im Auge, daß JavaBeans letztendlich eine Programmierschnittstelle ist, was bedeutet, daß all seine Eigenschaften als Erweiterungen der Standard-Klassenbibliothek von Java realisiert werden. Somit wird die gesamte, von JavaBeans zur Verfügung gestellte Funktionalität tatsächlich in dem JavaBeans-API realisiert. Das JavaBeans-API selbst ist eine Reihe von kleineren APIs, die spezifischen Funktionen oder Services gewidmet sind. Die nachfolgende Liste zeigt wesentliche Komponentenservices in dem JavaBeans-API, die zur Erleichterung all der Eigenschaften, die Sie heute gelernt haben, notwendig sind:
Durch entsprechendes Verständnis dieser Services und wie sie arbeiten, bekommen Sie einen größeren Einblick in die Technologie von JavaBeans. Jeder dieser Services wird in Form von kleineren, in dem größeren API enthaltenen APIs realisiert. In den nächsten Abschnitten widmen wir uns jedem dieser APIs und erklären, warum sie notwendige Elemente der JavaBeans-Architektur darstellen.
Die die grafische Benutzeroberfläche vermischenden APIs bieten einer Komponente ein Werkzeug zur Vereinigung ihrer Elemente der grafischen Benutzeroberfläche mit dem Container-Dokument, das normalerweise nur die die Komponente beinhaltende Webseite ist. Die meisten Container-Dokumente haben Menüs und Werkzeugleisten, die zur Anzeige der speziellen, von dieser Komponenten bereitgestellten Eigenschaften dienen. Die die grafische Benutzeroberfläche vermischenden APIs ermöglichen der Komponente, dem Menü und der Werkzeugleiste des Container-Dokuments Eigenschaften hinzuzufügen. Diese APIs definieren auch den Mechanismus, der Raumverhandlungen zwischen den Komponenten und ihren Containern ermöglicht. Anders gesagt, die die grafische Benutzeroberfläche vermischenden APIs sind auch für die Definition der Layout-Eigenschaften von Komponenten zuständig.
Ein Container-Dokument ist ein JavaBeans-Komponenten enthaltendes Dokument (normalerweise HTML), das als Eltern für alle in ihm enthaltenen Komponenten dient. Neben anderen Dingen, sind Container-Dokumente normalerweise für die Verwaltung des Hauptmenüs und der Werkzeugleiste zuständig.
Die Persistenz-APIs spezifizieren den Mechanismus, mit dem Komponenten innerhalb des Kontexts eines Container-Dokumentes gespeichert und geladen werden können. Komponenten erben per Voreinstellung den automatischen, von Java bereitgestellten Serialisations-Mechanismus. Entwickler haben ebenfalls die Freiheit, auf den speziellen Erfordernissen ihrer Komponenten basierende, besser ausgearbeitete Persistenz-Lösungen zu entwerfen.
Die APIs zur Ereignisbehandlung spezifizieren eine ereignisgesteuerte Architektur, die die Wechselwirkung der Komponenten miteinander definiert. Das Java-AWT beinhaltet bereits ein leistungsstarkes, ereignishandhabendes Modell, das als Grundlage für die Komponenten-APIs zur Ereignisbehandlung dient. Diese APIs sind wesentlich, wenn es darum geht, den Komponenten die Freiheit zu gewähren, in konsequenter Weise miteinander zu interagieren.
Die Introspektions-APIs definieren Techniken, die Komponenten dazu veranlassen, ihre interne Struktur zur Entwurfszeit direkt zur Verfügung zu stellen. Diese APIs enthalten die notwendige Funktionalität, es Entwicklungstools zu ermöglichen, eine Komponente nach ihrem internen Status abzufragen, einschließlich der Schnittstellen, Methoden und Member-Variablen, aus denen die Komponente besteht. Die APIs sind, basierend auf der Ebene, auf der sie benutzt werden, in zwei getrennte Abschnitte unterteilt. Die Introspektions-APIs der unteren Ebene ermöglichen beispielsweise Entwicklungswerkzeugen direkten Zugriff auf die Komponenteneigenschaften, also eine Funktion, die Sie nicht unbedingt in den Händen von Komponentenbenutzern sehen wollen. APIs der höheren Ebene verwenden APIs der unteren Ebene zur Bestimmung der Teile einer Komponente, die zur Änderung durch den Benutzer exportiert werden. Das heißt, obwohl Entwicklungswerkzeuge zweifellos Gebrauch von beiden Arten von APIs machen, werden sie die APIs der höheren Ebene nur dann verwenden, wenn sie dem Benutzer Komponenteninformationen bereitstellen.
Application Builder Support APIs stellen die bei Entwurfszeit für Bearbeitung und Manipulation der Komponenten erforderliche Systemverwaltungszeit bereit. Diese APIs werden größtenteils von visuellen Entwicklungswerkzeugen eingesetzt, um die Möglichkeit eines visuellen Layouts und Bearbeitung von Komponenten während der Erstellung einer Anwendung zu bieten. Der Teil einer Komponente, der die visuellen Bearbeitungsmöglichkeiten bereitstellt, wurde speziell so entworfen, daß er physisch von der Komponente selbst getrennt ist und somit dazu beiträgt, autonome Laufzeitkomponenten so kompakt wie möglich zu gestalten. In einer reinen Laufzeitumgebung werden Komponenten nur mit der erforderlichen Laufzeitkomponente übertragen. Entwickler, die sich der Vorteile von Entwurfszeitkomponenten bedienen wollen, können leicht den Entwurfszeitteil der Komponente erlangen.
Reicht das vorerst? Oder wollen Sie noch mehr wissen? Die JavaBeans-Spezifikationen sind verfügbar auf der Java-Webseite unter
http://java.sun.com/products/jdk/1.1/docs/guide/beans/
JavaBeans – Technik, Konzepte, Beispiele von Michael Morrison (Markt & Technik, ISBN 3-8272-5284-9) ist sehr gut als Einführung in JavaBeans und welche Möglichkeiten es Ihnen bietet geeignet.
Das Java-Security-API bietet Java-Entwicklern einen Rahmen, der ihnen die Aufnahme von Standardsicherheitsmechanismen wie beispielsweise Authentizierung, Meldungsübersichten und digitale Unterschriften in ihre eigenen Anwendungen ermöglicht. Diese Werkzeuge dienen der Sicherstellung, daß eine Anwendung oder ihre Daten zuverlässig sind, daß die Daten nicht modifiziert wurden und sie von dem richtigen Personenkreis benutzt werden. Allerdings bietet das Java-API keinen Mechanismus zur Datenverschlüsselung, wie beispielsweise von SSL bereitgestellt.
Digitale Signaturen stellen vom Standpunkt zukünftiger Applets her gesehen wahrscheinlich den interessantesten Teil des Java-Security-API dar, da digitale Signaturen es den Applets letztendlich ermöglichen, den Sicherheits-»Kindergarten« zu verlassen. In Kapitel 8, »Java-Applets-Grundlagen«, hatten Sie bereits Gelegenheit, einen kurzen Blick auf das Thema digitale Signaturen zu werfen. Als Bestandteil des Java-Security-API bietet Java 1.1 die Möglichkeit der Erstellung von plublic- und private-Schlüsseln, um JAR-Dateien digital zu unterschreiben und zu verifizieren, so daß eine digitale Signaturen dem Schlüssel, der sie unterzeichnet hat, entspricht. Das Security-API in Java 1.1 stellt keine Infrastruktur zur Verteilung solcher Schlüssel zur Verfügung (derzeit müssen sie manuell runtergeladen werden); um den Prozeß einfacher anwendbar zu gestalten, muß dieser Mechanismus in Browser und Werkzeuge eingebaut werden.
Eine zweites Merkmal des Security-API ist die Meldungsübersicht, die prüft, daß der ursprüngliche Status von Daten in einer Klasse oder einer anderen Datei nicht geändert wurde. Meldungsübersichten, die auch manchmal als digitale Fingerabdrücke bezeichnet werden, können dazu benutzt werden zu verhindern, daß Daten von anderen, nicht autorisierten Benutzern ohne die Genehmigung des ursprünglichen Autors modifiziert werden (oder zumindest dazu, Sie darüber zu informieren, daß jemand die Daten modifiziert hat). Das Security-API bietet Meldungsübersichten im Format MD2, MD5 und SHA.
Und die Access Control Lists (ACLs) (Zugriffskontrollisten) können schließlich dazu benutzt werden, zu kontrollieren, wem Zugriff auf eine bestimmte Klasse oder Dokument gewährt wurde und auf welcher Zugriffsebene. Ein ACL für ein bestimmtes Dokument beschreibt, welche Benutzer oder Gruppen Zugriff auf ein spezielles Dokument haben und die exakte Art der Genehmigung, die sie haben (eine Benutzergruppe kann beispielsweise die Genehmigung haben, ein Dokument zu lesen, Schreibgenehmigung kann allerdings nur einzelnen zugeteilt worden sein).
Das Java-Security-API besteht aus drei Paketen, alle unter dem java.security-Paket:
RMI wird zur Erstellung von Java-Anwendungen benutzt, die mit anderen Java-Anwendungen über ein Netz kommunizieren können. Oder, um es genauer auszudrücken, ermöglicht RMI einer Java-Anwendung, Methoden und Zugriffsvariablen innerhalb anderer Java-Anwendungen, die in unterschiedlichen Java-Umgebungen oder auf unterschiedlichen Systemen laufen können, aufzurufen und über die Netzverbindung Objekte weiter- und zurückzugeben. RMI ist ein höher entwickelter Mechanismus zur Kommunikation zwischen verteilten Java-Objekten als eine einfache Socket-Verbindung es sein könnte, da der Mechanismus und die Protokolle, durch die Sie zwischen den Objekten kommunizieren, definiert und standardisiert sind. Sie können mit einem anderen Java-Programm mit RMI kommunizieren, ohne vorher das Protokoll zu kennen.
Das RMI-Konzept könnte Visionen von auf der ganzen Welt fröhlich miteinander kommunizierenden Objekten aufkommen lassen, normalerweise wird RMI jedoch in einer traditionelleren Client-Server-Situation benutzt: Eine Einzel-Server-Anwendung erhält Verbindungen und Anfragen von einer Anzahl Clients. RMI ist einfach ein Mechanismus, der es Client und Server ermöglicht, miteinander zu kommunizieren.
Die für RMI gesteckten Ziele waren, ein verteiltes Objektmodell in Java zu integrieren, ohne dabei die Sprache oder das bestehende Objektmodell auseinander zu reißen und das Eintreten in eine Wechselbeziehung mit einem Remote-Objekt so einfach wie mit einem lokalen zu gestalten. Beispielsweise sollte es Ihnen möglich sein, Remote-Objekte auf exakt dieselbe Weise wie lokale zu verwenden (sie Variablen zuweisen, sie als Argumente an Methoden weitergeben, usw.), und Remote-Objekte in Methoden aufzurufen, sollte auf dieselbe Weise erreichbar sein, wie für entsprechende lokale Aufrufe. Darüber hinaus beinhaltete RMI einen höher entwickelten Mechanismus, um Methoden bei Remote-Objekten aufzurufen, um ganze Objekte oder Teile von Objekten entweder mit Referenz oder mit Wert weiterzugeben sowie zusätzliche Ausnahmen für die Bearbeitung von Netzfehlern, die beim Durchführen von Remote-Operationen vorkommen können.
Zum Erreichen dieser Ziele besitzt RMI mehrere Ebenen und ein einzelner Methodenaufruf durchläuft viele dieser Ebenen, um an seinen Bestimmungsort zu gelangen (siehe Abbildung 14.4). Es gibt drei Ebenen:
Die Transportebene, die eigentliche Netzverbindung von einem System zu einem anderen.
|
Abbildung 14.4:
|
Die Verfügbarkeit von drei RMI-Ebenen ermöglicht die unabhängige Kontrolle und Implementierung jeder Ebene. Stubs und Skeletons ermöglichen es Client- und Server-Klassen, sich so zu verhalten, als ob die vorliegenden Objekte lokale seien, und genau dieselben Java-Spracheigenschaften zum Zugriff auf diese Objekte zu verwenden. Die Ebene Remote Reference Layer stellt die Verarbeitung des Remote-Objekts in seine eigene Ebene, die dann unabhängig von den Anwendungen, die von ihr abhängig sind, optimiert und reimplementiert werden kann. Schließlich wird die Ebene Network Transport Layer unabhängig von den beiden anderen benutzt, so daß Sie unterschiedliche Typen von Socket-Verbindungen für RMI benutzen können (TCP/IP, UDP oder TCP mit einem anderen Protokoll wie beispielsweise SSL).
Wenn eine Client-Anwendung einen Remote Methode Call durchführt, gelangt der Aufruf über Stub zu der Referenzebene, die die Argumente, falls erforderlich, zusammenstellt und gibt ihn dann über die Netzebene an den Server, wo die Serverseitige Referenzebene die Argumente auseinandernimmt und sie an Skeleton und dann an die Server-Implementierung weiterleitet. Die Ausgabewerte für den Aufruf der Methode machen dann den Weg in umgekehrter Reihenfolge zurück zur Client-Seite.
Das Zusammenstellen und Weitergeben von Methodenargumenten ist einer der interessanteren Aspekte von RMI, da Objekte in etwas konvertiert werden müssen, das über das Netz weitergegeben werden kann. Diese Konvertierung nennt man Serialisation; am Tag 19, »Java-Datenstreams«, werden Sie mehr darüber lernen. So lange ein Objekt serialisiert werden kann, kann RMI es als einen Methodenparameter oder Ausgabewert benutzen. Serialisierbare Objekte beinhalten alle Java-Primitiv-Typen, Java-Remote-Objekte und jedes beliebige andere Objekt, das die Serializeable-Schnittstelle (die viele der Klassen in der Standard-1.1-JDK, wie beispielsweise alle AWT-Komponenten, beinhaltet) implementiert.
Als Methodenparameter oder Ausgabewerte benutzte Java-Remote-Objekte werden so wie lokale Objekte nach Referenz übergeben. Andere Objekte werden allerdings kopiert. Beachten Sie, daß dieses Verhalten die Art und Weise, in der Sie Ihre Java-Programme schreiben, wenn diese Programme Remote Method Calls benutzen, beeinflußt – Sie können beispielsweise ein Array nicht als ein Argument an eine Remote-Methode weitergeben, das Array von dem Remote-Objekt ändern lassen und erwarten, daß die lokale Kopie modifiziert wird. Dies stellt einen Unterschied zur Verhaltensweise von lokalen Kopien dar, wo alle Objekte als Referenzen weitergegeben werden.
Um eine Anwendung zu erstellen, die RMI einsetzt, benutzen Sie die Klassen und Schnittstellen, die im Paket java.rmi definiert sind, das java.rmi.server für Serverseitige Klassen, java.rmi.registry, das die Klassen zur Lokalisierung und Registrierung der RMI-Server auf dem lokalen System enthält, und java.rmi.dgc für Garbage-Collection von verteilten Objekten beinhaltet. Das java.rmi-Paket selbst enthält die allgemeinen RMI-Schnittstellen, -Klassen und -Ausnahmen.
Um eine RMI-basierte Client-Server-Anwendung zu implementieren, definieren Sie zuerst eine Schnittstelle, die alle Methoden, die Ihr Remote-Objekt unterstützen wird, enthält. Die Methoden in dieser Schnittstelle müssen alle ein throws-RemoteException-Statement beinhalten, das etwaige Netzprobleme behandelt, die zur Verhinderung der Kommunikation zwischen Client und Server führen können.
Der nächste Schritt besteht in der Implementierung der Remote-Schnittstelle in einer Server-seitigen Anwendung, die in der Regel die UnicastRemoteObject-Klasse erweitern. Innerhalb dieser Klasse können Sie die Methoden in der Remote-Schnittstelle implementieren und auch einen Security-Manager für diesen Server erstellen und installieren (um die Verbindungsherstellung von Ramdom-Clients und die Durchführung nicht autorisierter Aufrufe von Methoden zu verhindern). Sie können natürlich den Security-Manager derart konfigurieren, daß er verschiedene Operationen genehmigt oder nicht genehmigt. In der Server-Anwendung »registrieren« Sie auch die Remote-Anwendung, die diese an einen Host und einen Port anbindet.
Auf der Client-Seite implementieren Sie eine einfache Anwendung, die die Remote-Schnittstelle benutzt und Methoden in dieser Schnittstelle aufruft. Eine Klasse namens Naming (in java.rmi) ermöglicht dem Client eine transparente Verbindungsherstellung zum Server.
Wenn der Code geschrieben ist, können Sie ihn mit dem Standard-Compiler von Java kompilieren, allerdings gibt es noch einen weiteren Schritt auszuführen: benutzen Sie das Programm rmic zur Erzeugung der Ebenen Stubs und Skeletons, damit RMI effektiv zwischen den beiden Seiten des Prozesses arbeiten kann.
Das Programm rmiregistry wird schließlich dazu benutzt, die Server-Anwendung an das Netz selbst anzuschließen und es an einen Port anzubinden, so daß Remote-Verbindungen hergestellt werden können.
Natürlich stellt dies eine sehr vereinfachte Form des Prozesses zur Erstellung einer RMI-basierten Anwendung dar. Weitere Informationen über RMI und wie man die RMI-Klassen einsetzt finden Sie in den Informationen über die Webseite von JavaSoft unter
http://java.sun.com/products/jdk/1.1/docs/guide/rmi/
JDBC das Java Database Connectivity API, definiert eine strukturierte Schnittstelle zu SQL-Datenbanken (Structured Query Language) – Industriestandard für relationale Datenbanken. Durch die Unterstützung von SQL ermöglicht JDBC Entwicklern die Interaktion und Unterstützung einer breiten Palette von Datenbanken. Dies bedeutet, daß die spezifischen Eigenschaften der zugrundeliegenden Datenbankplattform in bezug auf JDBC ziemlich irrelevant sind. Also gute Nachrichten für Java-Entwickler.
Die API-Methode der JDBC zum Zugriff auf SQL-Datenbanken ist mit bestehenden Entwicklungstechniken für Datenbanken vergleichbar, so daß Interaktion mit einer JDBC benutzenden SQL-Datenbank nicht sehr unterschiedlich zu der Interaktion mit einer traditionelle Datenbankwerkzeuge benutzenden SQL-Datenbank ist. Dies sollte Java-Programmierer, die schon einige Erfahrung mit Datenbanken haben, in bezug auf JDBC zuversichtlich stimmen. Das JDBC-API wurde bereits von vielen Industrieführern angenommen, inklusive einiger Lieferanten von Entwicklungswerkzeugen, die zukünftige Unterstützung von JDBC bei ihren Entwicklungsprodukten angekündigt haben.
Das JDBC-API beinhaltet Klassen für allgemeine Formen von SQL-Datenbanken wie Datenbankverbindungen, SQL-Anweisungen und Ergebnissätze. Java-Programme mit JDBC werden in der Lage sein, das vertraute SQL-Programmierungsmodell der Ausgabe von SQL-Anweisungen und Verarbeitung der Ergebnisdaten zu benutzen. Das JDBC-API hängt weitgehend von einem Treibermanager ab, der mehrere Treiber, die die Verbindung zu verschiedenen Datenbanken herstellen, unterstützt. JDBC-Datenbanktreiber können entweder vollständig in Java geschrieben werden oder durch Verwendung systemeigener Methoden, um eine Brücke zwischen Java-Anwendungen und bestehenden Datenbankzugriffsbibliotheken zu schlagen, implementiert werden.
JDBC beinhaltet ebenso eine Brücke zwischen JDBC und ODBC, der allgemeinen Schnittstelle zum Zugriff auf SQL-Datenbanken von Microsoft. Die JDBC-ODBC-Brücke ermöglicht es, JDBC-Treiber als ODBC-Treiber zu benutzen.
Die JDBC-Klassen sind als Bestandteil von Java 1.1 im java.sql-Paket enthalten und beinhalten Klassen zur Handhabung der Treiber, zum Verbindungsaufbau zwischen Datenbanken, zur Erstellung von SQL-Abfragen und Handhabung der Ergebnisse.
Die Webseite von JavaSoft enthält umfangreiche Informationen und Spezifikationen über JDBC unter
http://java.sun.com/products/jdk/1.1/docs/guide/jdbc/
Herzlichen Glückwunsch! Atmen Sie tief durch – Sie haben die zweite Woche geschafft. Diese Woche war vollgestopft mit nützlichen Informationen bezüglich des Erstellens von Applets und der Verwendung der AWT-Klassen von Java, um in Ihren Applets voll ausgereifte grafische Benutzeroberflächen anzuzeigen, zu zeichnen, zu animieren, Eingaben zu verarbeiten und zu erstellen.
Den Abschluß dieser Woche bildete heute der Lehrstoff über Applets mit einer Reihe verschiedener Themen. Den Anfang machten einige einfache Applet-Tips zur Anzeige von Statuszeilen, zum Aufzeichnen von informationen über ein Applet selbst und zur Erstellung von Web-Verknüpfungen in Applets.
Anschließend haben wir uns dem Thema Vernetzung in Java gewidmet, und Sie haben die URL-Klasse, die opentStream()-Methode und die Verwendung von Netz-Sockets erlernt. Außerdem haben wir eine Anwendung durchgearbeitet, die eine Client- und Server-Seite erstellt und zwischen ihnen mit TCP-Sockets in Wechselwirkung tritt.
Nach Abschluß des Themas Vernetzung hat sich der letzte Teil dieses Kapitels mit Themen zu Java 1.1 befaßt, einschließlich der Benutzung von Operationen der Zwischenablage (Ausschneiden, Kopieren, Einfügen) und der Internationalisierung Ihres Java-Programms. Den Abschluß bildete ein Überblick über einige höhere Java-APIs einschließlich JavaBeans, RMI, Security und JDBC.
Nächste Woche kommen wir wieder auf Java selbst zurück und befassen uns mit einigen höheren Teilen der Sprache, mit der wir diese Woche nur leicht in Berührung gekommen sind, und den Abschluß bilden, einschließlich der Erstellung von public- und private-Klassen, Methoden und Variablen, Pakete, Schnittstellen, Verwendung von Threads, Ausnahmen und die verschiedenen I/O-Klassen, die Java bietet.
F Wie kann ich eine HTML-Formulareinreichung in einem Java-Applet simulieren?
A Derzeit ist das in Applets schwierig. Die beste (und einfachste) Möglichkeit ist die Verwendung der GET-Notation, um den Browswer zu veranlassen, den Formularinhalt für Sie einzureichen.
HTML-Formulare können auf zwei Arten eingereicht werden: Durch Verwendung der GET-Anfrage oder mit POST. Wenn Sie GET verwenden, werden die Informationen Ihres Formulars im URL codiert. Das kann etwa so aussehen:
http://www.blah.com/cgi-bin/myscript?foo=1&bar=2&name=Laura
Da das Formular im URL codiert ist, können Sie ein Java-Applet schreiben, das ein Formular simuliert, Eingaben vom Benutzer anfordern und dann ein neues URL-Objekt mit den Formulardaten erstellen. Dann geben Sie diesen URL mit getAppletContext(), showDocument(), an den Browser weiter. Der Browser reicht die Formularergebnisse selbst ein. Bei einfachen Formularen genügt das.
F Wie kann ich POST für Formulareinreichungen realisieren?
A Sie müssen simulieren, was ein Browser macht, um Formulare mit POST übersenden zu können. Öffnen Sie einen Socket zum Server und übersenden Sie die Daten. Das sieht etwa so aus (das genaue Format wird vom HTTP bestimmt):
POST /cgi-bin/mailto.cgi HTTP/1.0
Content-type: application/x-www-form-urlencoded
Content-length: 36
{hier stehen Ihre codierten Formulardaten }
Wenn Sie alles richtig gemacht haben, erhalten Sie die CGI-Formularausgabe vom Server zurück. Dann liegt es an Ihrem Applet, diese Ausgabe korrekt zu verarbeiten. Im Fall einer Ausgabe in HTML besteht eigentlich keine Möglichkeit, diese Ausgabe an den Browser, in dem Ihr Applet ausgeführt wird, weiterzugeben. Falls Sie einen URL zurückerhalten, können Sie den Browser auf diesen URL umleiten.
F Ich bekomme das GetRaven-Beispiel nicht zum Laufen. Die Fehlermeldungen zeigen mir ständig Sicherheitsausnahmen an.
A Die einfachste Methode, um mit dem GetRaven-Beispiel arbeiten zu können, ist den Code als korrekt anzunehmen und das Applet auf dem Web unter http://www.lne.com/Web/JavaProf/GetRaven.html zu betrachten. Wenn Sie lieber selbst aktiv werden wollen, müssen Sie vier Dinge tun:
Wenn sich sowohl die raven.txt-Datei als auch das Applet auf demselben Web-Server befinden – und sie auf einem Web-Server und nicht auf der lokalen Diskette installiert sind –, sollte es klappen. Sie können weder getrennte Server für Ihr Applet und die Klassendatei verwenden, noch können Sie Datei-URLs verwenden. Beide Dateien müssen sich auf einem Web-Server befinden.
F showStatus() funktioniert nicht in meinem Browser. Wie kann ich meinen Lesern Statusinformationen ausgeben?
A Wie Sie in dem Abschnitt über showStatus() gelernt haben, liegt es absolut am Browser, ob er showStatus() unterstützt. Wenn Sie in Ihrem Applet ein statusähnliches Verhalten benötigen, können Sie eine Statusbeschriftung (Label) im Applet erstellen, die auf die auszugebenden Informationen aktualisiert wird.
F Ich habe versucht, zwischen zwei Applets in meiner Webseite unter Verwendung der Methoden getAppletContext() und getApplet() zu kommunizieren. Meine Applets stürzen mit NullPointerException Fehlermeldungen ab. Was bedeutet das?
A Der von mir beschriebene Mechanismus bezüglich der Kommunikation zwischen Applets beruht auf den Informationen, die SUN und die Java-Klassenbibliothek als entsprechenden Weg dafür angeben. Es verhält sich wie bei showStatus(): es hängt von dem jeweiligen Browser ab, ob er diesen Mechanismus ausführt oder nicht bzw. ob er ihn korrekt ausführt. Die vorherige Version 3.0 von Netscape und Internet Explorer haben beide eigenartige Probleme mit Inter-Applet-Kommunikation.
F Die Informationen über Ausschneiden/Kopieren/Einfügen in 1.1 sind gut, ich möchte aber »DragandDrop« benutzen, um die Daten von einer Komponente in eine andere zu transportieren. Wie kann ich das tun, ohne daß ich eine viel Code selbst schreiben muß?
A Bei SUN befindet sich eine »DragandDrop«-Methode in Planung, die »DragandDrop« unter Verwendung des gleichen Mechanismus, dem sich Ausschneiden/Kopieren/Einfügen bedient, ausführt. Allerdings sind in Java 1.1 entsprechende »DragandDrop«-Möglichkeiten noch nicht enthalten, Sie müssen also noch ein wenig Geduld haben.
Weitere Informationen finden Sie in der Datenübertragungspezifikation: http://java.sun.com:/products/jdk/1.1/docs/guide/awt/designspec/datatransfer.html.
(c) 1997 SAMS
![]()
![]()
![]()
![]()
![]()
![]()
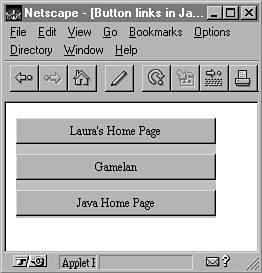{kind=link}
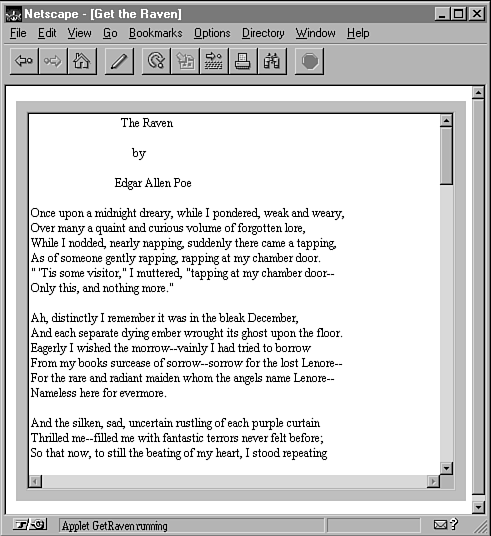{kind=link}
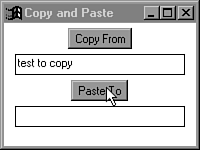{kind=link}
{kind=link}