




Neben Arrays und Listen gibt es in Perl eine weitere Datenstruktur, in der Sie Daten auflisten können: die assoziativen Arrays, kurz Hashes genannt. In vielen Situationen - abhängig von der Art der Daten und ihrer Verwendung - eignen sich Hashes weit besser als Arrays, um Daten zu speichern und auf sie zuzugreifen.
Heute befassen wir uns mit Hashes. Die Themen sind heute:
split einen String in eine Liste (oder einen Hash) konvertieren
Sie haben gestern gelernt, dass eine Liste ein Satz von Skalaren und ein Array eine (nach Elementposition) geordnete Liste ist. Mit einem Hash kann man ebenfalls eine Sammlung von Daten darstellen, jedoch werden die Daten auf eine andere Art organisiert.
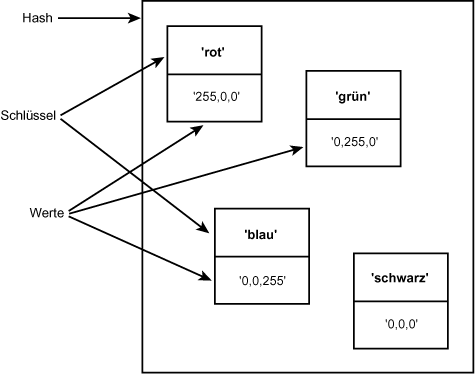
Ein Hash ist ein ungeordneter Satz von Paaren aus Schlüsseln und Werten. Jedem Schlüssel ist ein Wert zugeordnet, wobei sowohl Schlüssel als auch Wert eine beliebige Art von skalarem Wert sein können (siehe Abbildung 5.1). Sie können auf ein Element (sprich ein Paar) in einem Hash zugreifen, indem Sie sich auf den Schlüssel beziehen.
Weder die Schlüssel noch die Werte stehen in irgendeiner Ordnung - Sie können nicht auf das erste oder letzte Element in einem Hash verweisen.
Hashes sind in vieler Hinsicht nützlicher als Arrays, vor allem wenn man auf ein Element lieber mit einer expliziten Bezeichnung (einem Hash-Schlüssel) als mit einer bloßen Nummer (einem Array-Index) zugreifen möchte.

Hashes werden auch assoziative Arrays genannt. »Assoziatives Array« ist sogar die ursprüngliche, korrekte Bezeichnung, die im Grunde besser beschreibt, was Hashes eigentlich sind (die Schlüssel werden mit ihren Werten assoziiert). Doch mittlerweile bevorzugen viele Perl-Programmierer (wie ich auch) den viel kürzeren und weniger zungenbrecherischen Namen Hash.
Wie Arrays haben Hashes ihre eigenen, als solche gekennzeichneten Variablen: Diese
beginnen mit einem Prozentzeichen (%) und folgen denselben Regeln wie
Arrayvariablen. Wie bei allen Variablen ist die Hash-Variable %x etwas anderes als die
Arrayvariable @x oder die Skalarvariable $x.
Hashes sind Listen und den Arrays in Erstellung und Gebrauch sehr ähnlich. Doch weil Hashes ihre Daten anders speichern, haben sie ein paar Besonderheiten. Wenn Sie zum Beispiel Daten in ein Hash packen, müssen Sie bei jedem Element auf zwei Skalare achten (den Schlüssel und den Wert). Und weil Hashes nicht geordnet sind, ist das Sortiern von Hash-Elementen etwas aufwendiger. Außerdem verhalten sich Hashes in skalarem Kontext anders als Arrays. Lesen Sie weiter, ich werde Ihnen all dies jetzt erklären.
Die Listensyntax (Klammer auf, durch Kommata getrennte Elemente, Klammer zu) kann zum Erstellen von Hashes ebenso verwendet werden wie für Arrays. Alles was Sie tun müssen, ist, Ihre Daten innerhalb von Klammern aufzulisten und dann eine Hash-Variable auf die linke Seite der Zuweisung zu stellen:
%paare = ('rot', 255, 'grün', 150, 'blau', 0);
Mit einer Arrayvariablen ergäbe dies ein Array von sechs Elementen. Mit einer
HashVariablen (%paare) werden die Elemente dem Hash paarweise zugewiesen: Das
erste Element ist ein Schlüssel, das zweite sein Wert, das dritte Element ist der zweite
Schlüssel und das vierte dessen Wert und so weiter und so fort. Wenn die Anzahl der
Elemente ungerade ist, wird das letzte ignoriert.
Nun kann man bei dieser Schreibweise kaum auf den ersten Blick erkennen, was in der Liste ein Schlüssel und was ein Wert ist (und je länger die Liste ist, mit der Sie den Hash initialisieren, desto schwieriger wird es). Viele Perl-Programmierer setzen deswegen in ihrer Listensyntax für Hashes die Schlüssel/Wert-Paare jeweils in eigene Zeilen:
%temps = (
'Boston', 22,
'New York', 18,
'Miami', 32,
'Portland', 25,
# und so weiter...
);
Noch besser als diese Formatierung ist der =>-Operator, der sich exakt genauso
verhält wie das Komma zwischen Schlüssel und Wert. Die Verbindung zwischen den
Schlüsseln und Werten wird durch den =>-Operator noch deutlicher. Das erste
Beispiel mit den Farben sieht dann wie folgt aus:
%paare = ('rot'=>255, 'grün'=>150, 'blau'=>0);
Und das zweite mit den Städten:
%temps = (
'Boston' => 22,
'New York' => 18,
'Miami' => 32,
'Portland' => 25,
# und so weiter...
);
Und noch etwas: Perl geht bei jedem Schlüssel eines Hash-Elements davon aus, dass es sich um Strings handelt. Und weil der Schlüssel ohnehin ein String sein muss, können Sie sich etwas Tipparbeit sparen und die Anführungszeichen auch weglassen:
%paare = (rot=>255, grün=>150, blau=>0);
Wenn der Schlüssel allerdings ein Leerzeichen enthält, müssen Sie die Anführungszeichen setzen (so smart ist Perl auch wieder nicht).
Wie bei Arrays erzeugt das Zuweisen einer leeren Liste () an eine Hash-Variable
einen leeren Hash:
%hash = (); #keine Schlüssel und keine Werte
Eine zweite Möglichkeit, einen Hash zu erzeugen, ist die Initialisierung mit einem Array oder einer Liste. Weil die »Rohform« der Inhalte von Hashes und Arrays jeweils Listen sind, können Sie ohne Probleme zwischen den beiden hin- und herkopieren:
@zeug = ('eins', 1, 'zwei', 2);
%paarweises_zeug = @zeug
In diesem Beispiel werden durch die Zuweisung des Arrays @zeug an den Hash
%paarweises_zeug die Array-Elemente in eine Liste expandiert, dann in zwei
Schlüssel/Wert-Paare zerlegt und im Hash gespeichert. Das Ergebnis wäre das
gleiche, wenn Sie alle Elemente in Listenform eingetippt hätten. Passen Sie aber auf
die Anzahl der Elemente auf - ist sie ungerade, wird das letzte Element ignoriert und
nicht in den Hash übernommen (Perl-Warnungen geben Ihnen Bescheid, wenn das
passiert).
Und wie ist es mit der Rückwandlung von einem Hash in eine Liste? Im folgenden Beispiel weisen Sie einen Hash einem Array zu:
@zeug = %paarweises_zeug;
Wenn Sie einen Hash auf die rechte Seite einer Listenzuweisung stellen oder vielmehr
wann immer Sie einen Hash in einer Situation verwenden, in der eine rohe Liste
erwartet wird, »dröselt« Perl den Hash in seine einzelnen Elemente auf (Schlüssel,
Wert, Schlüssel, Wert und so fort). Diese Liste wird dann dem Array @zeug
zugewiesen.
Dieses schöne Aufschlüsselungsverhalten hat einen Haken: Weil Hashes nicht geordnet sind, stehen die Schlüssel/Wert-Paare, die Sie aus einem Hash herausziehen, höchstwahrscheinlich weder in derselben Reihenfolge, in der Sie sie eingefügt haben, noch sind sie nach einem anderen augenscheinlich sinnvollen Kriterium sortiert. Hash-Elemente werden in einem internen Format gespeichert, das den Zugriff sehr schnell vornimmt (die Geschwindigkeit ist sozusagen Perls einziges Anordnungskriterium), und in dieser internen, so gut wie unvorhersagbaren Reihenfolge werden sie auch wieder hervorgeholt. Wenn Sie eine Liste aus einem Hash in einer bestimmten Reihenfolge brauchen, müssen Sie eine Schleife bauen, die die Elemente nach Ihren Vorgaben gezielt aus dem Hash zieht (mehr darüber später).
Anders als Arrays, die lediglich Werte in einer bestimmten Reihenfolge enthalten, bestehen Hashes wie gesagt aus Schlüssel/Wert-Paaren. Um auf einen Wert in einem Hash zuzugreifen, müssen Sie seinen Schlüssel (auch Key genannt) kennen. Mit dem Schlüssel in geschweiften Klammern ({}) können Sie folgendermaßen auf einen Hash- Wert zugreifen:
print $temps{'Portland'};
$temps{'Portland'} = 50;
Sie sehen, dass diese Syntax der Array-Zugriffssyntax $array[] sehr ähnlich ist - Sie
greifen mit einer Skalarvariablen ($temps) und geschweiften Klammern um den
Schlüsselnamen (anstatt eckiger um einen Array-Index) auf einen skalaren Wert
innerhalb des Hash zu. Der Schlüssel innerhalb der Klammern sollte ein String sein
(hier haben wir einen single-quoted String genommen), Ziffern werden
gegebenenfalls in Strings umgewandelt. Außerdem können Sie, wenn der Schlüssel
nur ein einziges Wort enthält, die Anführungszeichen weglassen, Perl versteht auch
so, was Sie meinen:
$temps{Portland} = 50; # ist das gleiche wie $temps{'Portland'} = 50;
Wie bei den Arrays kommt der Variablenname in der Zugriffssyntax nicht mit gleichnamigen Skalarvariablen in Konflikt. Jede der folgenden Variablen verweist auf etwas anderes, obwohl der Variablenname immer derselbe ist:
$name # ein Skalar
@name # ein ganzes Array
%name # ein ganzer Hash
$name[$index] # der Skalar im Array @name an der Stelle $index
$name{'key'} # der Skalar im Hash %name mit dem Schlüssel 'key'
Mit der eben besprochenen Elementzugriffssyntax können Sie ein Hash-Element
hinzufügen, darauf zugreifen und es ändern. Aber wie werden Sie Elemente, die Sie
nicht mehr brauchen, wieder los? Dafür stellt Perl die Funktion delete zur Verfügung.
Diese Funktion nimmt den Verweis auf ein Hash-Element entgegen (im allgemeinen
einen Hash-Zugriffsausdruck wie $hashname{'key'}), löscht sowohl den Schlüssel als
auch den ihm zugeordneten Wert und gibt den gelöschten Wert zurück. Das bedeutet,
dass Sie mit delete ein Element nicht nur löschen, sondern auch von einem Hash zu
einem anderen verschieben können (es also aus dem einen löschen und dem anderen
hinzufügen), wie in folgendem Beispiel:
$hash2{$key} = delete $hash{$key};
Sie können auch überprüfen, ob ein bestimmtes Schlüssel/Wert-Paar in einem Hash
existiert: Die Funktion exists durchsucht einen Hash nach einem ihr übergebenen
Schlüssel und gibt wahr zurück, wenn sie ihn findet. Beachten Sie, dass der zu dem
gefundenen Schlüssel zugehörige Wert sehr wohl undefiniert sein könnte - exists
prüft wirklich nur, ob der Schlüssel vorhanden ist. Verwenden Sie exists
folgendermaßen.
if (exists $hashname{$key}) { $hashname{$key}++; }
Dieser Ausdruck prüft, ob der Schlüssel $key vorhanden ist, und wenn ja,
inkrementiert er den diesem Schlüssel zugeordneten Wert (vorausgesetzt natürlich,
dieser Wert ist eine Zahl).
Angenommen, Sie möchten alle Werte in einem Array oder einer Liste durchgehen,
jeden einzelnen auf eine bestimmte Eigenschaft überprüfen und unter bestimmten
Bedingungen verwenden. Bei einem Array würden Sie mit Element 0 anfangen und
den Vorgang so lange wiederholen, bis Sie beim letzten Element der Liste angelangt
sind (oder eine foreach-Schleife verwenden). Aber wie geht das mit Hashes? Eine
Reihenfolge gibt es nicht, und die Schlüssel können irgendwelche skalaren Werte sein.
Was Sie brauchen, ist eine Methode, ein paar Informationen aus dem Hash zu ziehen,
mit denen Sie die Struktur dann durchlaufen können.
Für dieses Problem stehen die Funktionen keys und values zur Verfügung. Diese
Funktionen nehmen beide einen Hash als Argument entgegen und geben eine Liste
zurück - keys eine Liste der Schlüssel und values eine Liste der Werte im
angegebenen Hash. Wenn Sie dann mit dieser Liste und foreach oder einer anderen
Schleife auf jedes einzelne Hash-Element zugreifen, kommen Sie an wirklich alle
Elemente - auch die, die Sie vielleicht längst vergessen haben.
Nehmen wir zum Beispiel einen Hash mit einer nach Städtenamen aufgeschlüsselten
Liste von Temperaturen (wie wir es bereits vorhin in einem Beispiel hatten). Diese
Liste möchten wir jetzt alphabetisch nach Städten sortiert ausgeben. Dafür erstellen
wir mit keys eine Liste aller Schlüssel, sortieren diese Liste mit sort und geben die
sortierten Schlüssel und ihre Werte dann in einer foreach-Schleife aus, etwa so:
foreach $stadt (sort keys %temps) {
print "$stadt: $temps{$stadt} grad\n";
}
Diese Schleife durchläuft nacheinander jedes Element der sortierten Schlüsselliste und
weist es der Variablen $stadt zu. Im Schleifenkörper können Sie sich dann mit dieser
Variablen auf das aktuelle Element beziehen.
Lassen Sie uns auf den Kontext zurückkommen und betrachten, wie Hashes sich in den verschiedenen Kontexten verhalten. Zumeist gelten dieselben Regeln wie für Listen, doch es gibt ein paar Ausnahmen.
Ich habe Ihnen gezeigt, wie man mit Listensyntax einen Hash erstellt, wobei der Hash die Elemente dann als Schlüssel/Wert-Paare speichert wie hier:
%paare = (rot=>255, grün=>150, blau=>0);
Im umgekehrten Fall, wenn Sie einen Hash verwenden, wo eine Liste erwartet wird, wird der Hash (in beliebiger Reihenfolge) zurück in seine Einzelteile zerlegt und folgt dann den gleichen Regeln wie alle anderen Listen.
@farben = %paare; # ergibt ein Array aus allen Elementen
($x, $y, $z) = %paare; # die ersten drei Elemente des aufgelösten
# Hash werden Variablen zugewiesen,
# verbleibende Elemente werden ignoriert
print %paare; # zerlegt den Hash in seine Elemente und
# gibt sie aus
Immer wenn Sie einen Hash in einem Listenkontext verwenden - zum Beispiel auf der rechten Seite einer Zuweisung an ein Array -, wird der Hash in eine Liste seiner Einzelteile »aufgedröselt«, und diese Liste benimmt sich dann wie in jedem anderen Listen- oder skalaren Kontext auch. Es gib allerdings einen Sonderfall:
$x = %paare;
Auf den ersten Blick könnte man meinen, dies sei das Hash-Äquivalent zu $x =
@array (Sie erinnern sich, damit ermitteln Sie die Anzahl der Elemente in einem
Array). Aber Perl verhält sich hier anders als bei Arrays - das Ergebnis $x ist hier
nämlich eine Beschreibung des internen Zustands der Hash-Tabelle, was in 99 % der
Fälle wahrscheinlich nicht das ist, was Sie wollen. Um die Anzahl der Elemente
(Schlüssel/Wert-Paare) in einem Hash zu erhalten, verwenden Sie statt dessen die
keys-Funktion und weisen die Schlüsselliste einer Skalarvariablen zu:
$x = keys %paare;
Die Funktion keys gibt eine Liste der Schlüssel im Hash zurück, die dann in skalarem
Kontext ausgewertet die Anzahl der Elemente liefert.
Sind Sie neugierig, was ich mit »eine Beschreibung des internen Zustands der Hash-Tabelle« meine? Okay, dann werde ich es kurz erklären. Die Zuweisung einer Hash-Variablen in skalarem Kontext liefert Ihnen zwei Zahlen, getrennt durch einen Schrägstrich. Die zweite Zahl ist die Summe der zur Verfügung stehenden Slots, das heißt Speicherstellen, die für die interne Hashtabelle reserviert wurden (oft auch »buckets« genannt). Die erste Zahl ist die Anzahl der tatsächlich von den Daten genutzten Slots. Sinnvoll werden diese beiden Zahlen, wenn Sie wissen möchten, wie effizient eine Hash-Tabelle ist: Eine Hash-Beschreibung von 4/100 würde bedeuten, dass der Hash nur 4 von 100 bereitgestellten Buckets verwendet: schlechte Nachricht über die Effizienz Ihres Skripts. Den Aufbau fortgeschrittener - und effizienter - Datenstrukturen werden wir an Tag 19 behandeln.
Ändern wir noch einmal unser Statistikskript. Erweitern wir es diesmal dahin, dass es sich merkt, wie oft jede Zahl jeweils eingegeben wurde, und das Ergebnis schließlich als Balkendiagramm darstellt. Hier ein Beispiel, wie das Diagramm aussehen könnte (abgesehen von diesem Histogramm ist die Ausgabe dieselbe wie vorher; deswegen werde ich das hier nicht noch einmal alles aufführen):
Häufigkeit der einzelnen Zahlen:
1 | *****
2 | *************
3 | *******************
4 | ****************
5 | ***********
6 | ****
43 | *
62 | *
Um das Vorkommen jeder Zahl in unserem Skript zu verfolgen, verwenden wir einen Hash mit den neu eingegebenen Zahlen als Schlüssel und den Häufigkeiten, mit denen die Zahlen auftauchen, als Werte. Der Diagrammabschnitt des Skripts durchläuft dann alle Elemente dieses Hash und gibt in einer grafischen Darstellung aus, wie oft jede Zahl eingegeben wurde.
Listing 5.1 zeigt den Perl-Code für unser neues Skript:
Listing 5.1: nochmehrstats.pl.
1: #!/usr/bin/perl -w
2:
3: $input = ''; # Benutzereingabe: Zahl
4: @nums = (); # Array: Zahlen;
5: %freq = (); # Hash: Zahl-Haeufigkeit
6: $count = 0; # Anzahl aller Zahlen
7: $sum = 0; # Summe
8: $avg = 0; # Durchschnitt
9: $med = 0; # Median
10: $maxspace = 0;# maximaler Platz für die Schluessel
11:
12: while () {
13: print 'Geben Sie eine Zahl ein: ';
14: chomp ($input = <STDIN>);
15: if ($input ne '') {
16: $nums[$count] = $input;
17: $freq{$input}++;
18: $count++;
19: $sum += $input;
20: }
21: else { last; }
22: }
23:
24: @nums = sort { $a <=> $b } @nums;
25: $avg = $sum / $count;
26: $med = $nums[$count /2];
27:
28: print "\n Anzahl der eingegebenen Zahlen: $count\n";
29: print "Summe der Zahlen: $sum\n";
30: print "Kleinste Zahl: $nums[0]\n";
31: print "Groesste Zahl: $nums[$#nums]\n";
32: printf("Durchschnitt: %.2f\n", $avg);
33: print "Mittelwert: $med\n\n";
34: print "Haeufigkeit der einzelnen Zahlen:\n";
35:
36: $maxspace = (length $nums[$#nums]) + 1;
37:
38: foreach $key (sort { $a <=> $b } keys %freq) {
39: print $key;
40: print ' ' x ($maxspace - length $key);
41: print '| ', '*' x $freq{$key}, "\n";
42: }
Dieses Skript unterscheidet sich nicht sehr vom vorigen; die einzigen Änderungen stehen in den Zeilen 5, 10, 17 und im letzten Abschnitt von Zeile 36 bis 42. Betrachten Sie diese Zeilen einmal etwas genauer, und beachten Sie auch, wo und wie sie sich in das Skript fügen, das wir bereits geschrieben haben.
Die Zeilen 5 und 10 sind ganz einfach; sie definieren lediglich neue Variablen, die wir
später im Skript verwenden: Der Hash %freq speichert die Häufigkeit der
eingegebenen Zahlen, und die Variable $maxspace enthält einen Zwischenwert zur
Formatierung des Diagramms (mehr dazu, wenn wir zum Erstellen des Diagramms
kommen).
Zeile 17 ist da viel interessanter. Sie steht innerhalb der Schleife, mit der wir die Daten einlesen. In der Zeile davor haben wir die zuletzt eingegebene Zahl dem Zahlenarray hinzugefügt. Die Zahl selbst ist der Schlüssel, und wie oft sie bis jetzt eingegeben wurde, ist der Wert. In Zeile 17 verwenden wir die eingegebene Zahl als Schlüssel des Häufigkeits-Hash. Wenn die Zahl bereits als Schlüssel vorhanden ist, erhöhen wir den ihr zugeordneten Wert um 1 (mit dem ++-Operator). Wenn kein solcher Schlüssel existiert, unsere Zahl also noch nicht im Hash enthalten ist, fügen wir sie damit hinzu und erhöhen den Wert auf 1.
Bei jedem weiteren Durchlauf inkrementieren wir nur dann den Wert (sprich die Häufigkeit), wenn genau diese Zahl wieder in den Benutzereingaben auftaucht.
So haben wir nach Beendigung der Eingabeschleife schließlich einen Hash, der jede eingegebene Zahl genau einmal als Schlüssel und ihre jeweilige Häufigkeit als Werte enthält. Jetzt muss nur noch ein Diagramm mit diesen Daten ausgegeben werden.
Anstatt wie in den bisherigen Beispielen Schritt für Schritt die Zeilen 36 bis 42 durchzugehen, möchte ich Ihnen nun zeigen, in welchen Schritten ich diese Schleife geschrieben habe. So bekommen Sie einen Einblick in meine Denkweise und die Entstehung dieser Schleife. Damit wird deutlicher, warum sie ist, wie sie ist.
Als erstes möchte ich die Werte in die richtige Reihenfolge bringen. Also fange ich mit
einer foreach-Schleife an, ähnlich der, die ich heute im Abschnitt »Auf alle Werte in
einem Hash zugreifen« beschrieben habe.
foreach $key (sort { $a <=> $b } keys %freq) {
print "Schluessel: $key Wert: $freq{$key}\n";
}
In dieser Schleife verwende ich foreach, um auf jeden Hash-Schlüssel zuzugreifen. In
welcher Reihenfolge das geschieht, wird jedoch von dem eingeklammerten Ausdruck
in der ersten Zeile kontrolliert. Der keys %freq-Teil erstellt eine Liste aller Schlüssel
des Hash, sort sortiert sie (Sie erinnern sich, sort sortiert standardmäßig in ASCII-
Reihenfolge, erst das Hinzufügen von {$a <=> $b} erzwingt eine numerische
Sortierung). Das Ergebnis ist, dass der Hash vom kleinsten zum größten Schlüssel
durchgegangen wird.
Innerhalb der Schleife muss ich dann nur noch die Schlüssel und die Werte ausgeben. Mit ein paar einfachen Daten erhielte ich dann eine Ausgabe wie diese:
Schluessel: 2 Wert: 4
Schluessel: 3 Wert: 5
Schluessel: 4 Wert: 3
Schluessel: 5 Wert: 1
Das ist zwar eine gute Darstellung der Werte im %freq-Hash, aber kein Histogramm.
Mein zweiter Schritt ist die Veränderung der print-Anweisung. Ich verwende den
wunderbaren String-Wiederholungsoperator (x), um die der Häufigkeit der Zahlen
entsprechende Anzahl Sternchen auszugeben:
foreach $key (sort { $a <=> $b } keys %freq) {
print '$key |', '*' x $freq{$key}, "\n";
}
Damit komme ich der Sache schon näher. Die Ausgabe sähe jetzt etwas so aus:
2 | ****
3 | *****
4 | ***
5 | *
Problematisch wird es aber, wenn die eingegebenen Zahlen größer als 9 sind. Wenn nicht alle Schlüssel gleich viele Stellen haben, würde mein schönes Diagramm geradezu aufgeschraubt. Wenn ich zufällig eine vierstellige Zahl zwischen meinen ein- und zweistelligen Zahlen hätte, sähe das Histogramm wie folgt aus:
2 | ****
3 | *****
4 | ***
5 | *
13 | **
24 | *
45 | ***
2345 | *
Was also tun? Ich muss dafür sorgen, dass vor dem Pipe-Zeichen (|) immer die
richtige Anzahl Leerzeichen steht, damit die Sternchen im Histogramm in derselben
Spalte beginnen. Ich habe dieses Problem mit der Funktion length gelöst, die die
Anzahl der Zeichen (genaugenommen der Bytes) in einem skalaren Wert liefert.
Zunächst muss ich herausfinden, wie breit die Schlüsselspalte überhaupt sein soll, das
heißt wie viele Stellen der »breiteste« Schlüssel hat. Ich nehme dafür die Länge der
größten Zahl im Array @zahlen und addiere eine 1, um ein Leerzeichen am Ende
anzuhängen:
$maxspace = (length $nums[$#nums]) + 1;
Innerhalb der Schleife verändere ich noch einmal meine Print-Anweisungen. Diesmal teile ich dem String-Wiederholungsoperator mit, wie viele Leerzeichen nach einem Schlüssel ausgegeben werden sollen - Spaltenbreite minus Schlüssellänge. So wird der Unterschied zwischen kleineren und der größten Zahl stets korrekt mit Leerzeichen aufgefüllt, und ich kann mit der Ausgabe der Pipes und Sternchen weitermachen:
foreach $key (sort { $a <=> $b } keys %freq) {
print $key; # den Schluessel ausgeben
print ' ' x ($max_breite - length $key); # bis zur max.-Breite mit
# Leerzeichen auffuellen
print '| ', '*' x $freq{$key}, "\n"; # die Sternchen ausgeben
}
Jetzt sieht das Histogramm aus, wie ich es Ihnen ganz am Anfang gezeigt habe. Ich bin fertig. Den kompletten Code haben Sie in Listing 5.1 bereits gesehen.
Die Art, wie ich hier das Diagramm formatiert habe, ist nicht gerade elegant. Sie sollten sich diese Methode nicht zum Vorbild nehmen, wenn Sie das Ausgabeformat Ihrer Daten festlegen, insbesondere wenn Sie dabei mit mehr als den paar Zeichen in diesem Beispiel zu tun haben. Perl (Sie erinnern sich, die praktische Extraktions- und Report-Sprache) hat einen Satz spezieller Datenformatierungs-Prozeduren, mit denen sich solche Reports viel einfacher erstellen lassen. Im HTML-Zeitalter wird mit Perl-Formatierungen nicht mehr viel gearbeitet, doch an Tag 20 gebe ich Ihnen zumindest eine kleine Kostprobe.
Über die Tastatur eingegebene Daten sind meist recht unkompliziert zu verarbeiten - Sie brauchen sie nur einer Variablen zuweisen und können dann damit anstellen, was immer Sie wollen. Aber in vielen Fällen sind - insbesondere aus Dateien eingelesene - Eingabedaten nicht so einfach zu handhaben. Was ist, wenn Sie Daten mit nicht einer, sondern gleich zehn Zahlen pro Zeile bekommen? Was ist, wenn Sie sich für einen Teil in der Mitte der Zeile interessieren, sich aus dem Rest aber überhaupt nichts machen?
Normalerweise erhalten Sie Ihre Daten in irgendeiner rohen Form, aus der Sie die
interessanten Dinge selbst »herauspicken« und speichern müssen. Dafür stellt Perl
Ihnen die Funktion split zur Verfügung, die einen gegebenen String nach Ihren
Vorgaben in eine Liste von Teilstrings aufteilt (splittet).
Ihre Vorgaben sind dabei insbesondere die Zeichen oder Zeichenfolgen, bei denen
split sozusagen »die Schere ansetzen« und den String aufteilen soll. Sie können hier
(mit regulären Ausdrücken) die raffiniertesten Suchmuster festlegen. Heute allerdings
betrachten wir nur das einfachste aller Trennzeichen: das Leerzeichen, das nicht nur
bei Leerzeichen, sondern allen Leerstellen (auch Whitespace, »weißer Raum« genannt
und als Sammelbegriff für Leerzeichen, Tabulator, Zeilenvorschub, Wagenrücklauf,
Seitenvorschub und vertikalen Tabulator gebraucht) trennt.
Sie übergeben der split-Funktion zwei Strings als Argumente - der erste enthält das
Trennzeichen, und der zweite ist der String, den Sie bei jedem Vorkommen des
Trennzeichens splitten möchten. Die split-Funktion teilt den String entsprechend auf
und gibt Ihnen eine Liste der Teilstrings zurück, die Sie beispielsweise einer
Arrayvariablen zuweisen und dann weiterarbeiten können. Der folgende Perl-Code
zum Beispiel zerlegt die Zahlenfolge im String $zahlenfolge in ein Array von Zahlen:
$zahlenfolge = '34 23 56 34 78 38 90';
@zahlen = split(' ', $zahlenfolge);
So! Jetzt können Sie mit den Zahlen im Array @zahlen nach Belieben herumspielen.
Zum Abschluß dieser Lektion wollen wir Hashes und split zusammen in einem
kleinen Beispiel einsetzen, das eine Namensliste einliest, diese Namen in einen nach
Nachnamen aufgeschlüsselten Hash packt und sie dann mit dem Nachnamen zuerst
und in alphabetischer Reihenfolge ausgibt. Das Ganze könnte zum Beispiel so
aussehen:
Geben Sie einen Namen ein (Vor- und Nachname): Umberto Eco
Geben Sie einen Namen ein (Vor- und Nachname): Kurt Vonnegut
Geben Sie einen Namen ein (Vor- und Nachname): Fjodor Dostojewski
Geben Sie einen Namen ein (Vor- und Nachname): Albert Camus
Geben Sie einen Namen ein (Vor- und Nachname): Paul Auster
Geben Sie einen Namen ein (Vor- und Nachname): George Orwell
Geben Sie einen Namen ein (Vor- und Nachname):
Auster, Paul
Camus, Albert
Dostojewski, Fjodor
Eco, Umberto
Orwell, George
Vonnegut, Kurt
Listing 5.2 zeigt das zugehörige Skript:
Listing 5.2: Das Skript namen.pl
1: #!/usr/bin/perl -w
2:
3: $in = ''; # temp Input
4: %names = (); # Hash Namen
5: $fn = ''; # temp Vorname
6: $ln = ''; # temp Nachname
7:
8: while () {
9: print 'Geben Sie einen Namen ein (Vor- und Nachname): ';
10: chomp($in = <STDIN>);
11: if ($in ne '') {
12: ($fn, $ln) = split(' ', $in);
13: $names{$ln} = $fn;
14: }
15: else { last; }
16: }
17:
18: foreach $lastname (sort keys %names) {
19: print "$lastname, $names{$lastname}\n";
20: }
Dieses Skript besteht aus drei Abschnitten: die Variablen initialisieren, die Daten
einlesen und sie sortiert wieder ausgeben. Der Initialisierungsteil sollte mittlerweile klar
sein, aber vielleicht fragen Sie sich, was das temp in den Kommentaren bedeutet. Es
steht für temporär. Wie Sie wissen, dient der gesamte Initialisierungsabschnitt im
Grunde nur der Übersichtlichkeit. Mit einem kurzen temp im Kommentar möchte ich
hier auf den ersten Blick klarmachen, dass diese Variablen nur Zwischenspeicher für
die Vor- und Nachnamen sind - die letztlich ja im Hash %names landen.
In Zeile 8 bis 16 lesen wir die Daten ein, und zwar wie Sie es bereits aus dem
Statistikskript kennen - mit einer while-Schleife, einem if zum Überprüfen auf eine
Leerzeile und <STDIN> in skalarem Kontext. Anders als im Statistikskript packen wir
die eingegebenen Strings hier nicht in ein Array, sondern splitten sie in Zeile 12 in
zwei temporäre Skalarvariablen, $fn und $ln, auf. In Zeile 13 fügen wir die Inhalte
dieser beiden Variablen dem Hash %names hinzu, den Nachnamen als Schlüssel und
den Vornamen als Wert.
Wenn alle Daten eingegeben sind, ist unser Hash komplett, und wir können ihn
ausgeben. Auch diese Syntax haben Sie bereits gesehen, zuletzt in dem
Histogrammbeispiel weiter oben in dieser Lektion. Diesmal sortieren wir die Schlüssel
aber in alphabetischer Reihenfolge, deswegen genügt hier die einfachere Form von
sort. Die print-Anweisung in Zeile 19 verwendet schließlich die Variable $lastname
(die bei jedem foreach-Durchlauf den aktuellen Schlüssel enthält), um den
Nachnamen und den diesem Schlüssel im Hash zugeordneten Vornamen auszugeben.
Wenn die Schleifen Sie verwirren, versuchen Sie nur die anderen Teile der Beispiele
zu verstehen. Morgen, am Tag 6, befassen wir uns ausführlich mit while und foreach.
Dann erfahren Sie ganz genau, was die Schleifen in den Beispielen eigentlich
machen.
Wie Arrays sind auch Hashes Listen; deswegen brauchen wir in dieser Lektion
eigentlich nicht viel tiefer zu gehen. Doch eine Funktion, die für den Gebrauch mit
Hashes nützlich sein kann, möchte ich hier erwähnen: each.
Die Funktion keys nimmt einen Hash als Argument entgegen und gibt eine Liste der
Schlüssel im Hash zurück; values macht das gleiche mit den Hash-Werten. Übergibt
man der Funktion each einen Hash als Argument, gibt sie ein Schlüssel/Wert-Paar als
zweielementige Liste zurück: Das erste Element ist ein Key und das zweite der Wert.
Das Besondere ist, dass Sie mit mehrmaligem Aufrufen von each den gesamten Hash
durchgehen können. Wie bei allen Hash-Elementen ist die Reihenfolge der Paare
nicht geordnet. Wenn each alle Elemente aus dem Hash gelesen hat, gibt es eine leere
Liste () zurück.
Heute haben wir mit der Behandlung der Hashes Ihr Grundwissen über Listendaten
vervollständigt. Hashes sind Arrays und Listen sehr ähnlich - mit der Ausnahme, dass
sie Daten in Schlüssel/Wert-Paaren anordnen, anstatt sie in einer numerischen
Reihenfolge zu speichern. Wir haben besprochen, wie man einen Hash in einer Hash-
Variablen %hash speichert, auf einen Wert mit $hash{'key'} zugreift, Schlüssel aus
dem Hash löscht und mit einer foreach-Schleife und der keys-Funktion alle Hash-
Elemente durchgehen kann.
Im folgenden noch einmal die Perl-Funktionen, die Sie heute kennengelernt haben:
exists nimmt einen Hash-Schlüssel entgegen und gibt wahr zurück, wenn dieser
im Hash als Schlüssel vorhanden ist (auch wenn der diesem Schlüssel zugeordnete
Wert undefiniert ist).
delete nimmt einen Hash-Schlüssel entgegen und löscht diesen Schlüssel samt
Wert aus dem Hash. Anders als undef, das einem Element in einem Hash oder
Array den undefinierten Wert zuweist, entfernt delete das gesamte Paar
(Schlüssel und Wert).
keys nimmt einen Hash entgegen und gibt eine Liste aller Schlüssel in diesem
Hash zurück.
values nimmt einen Hash entgegen und gibt eine Liste aller Werte in diesem
Hash zurück.
split nimmt zwei Strings entgegen und splittet den zweiten String an den Stellen,
an denen das im ersten String angegebene Trennzeichen auftaucht, in eine Liste
von Teilstrings. Mit einem dritten Argument, einer Zahl, kann man festlegen, wie
viele Elemente die von split erzeugte Liste höchstens enthalten darf.
Mehr Informationen finden Sie in der perlfunc-Manpage bzw. im Anhang A.
Frage:
Diese verschiedenen Variablenzeichen! Wie soll ich die denn auseinanderhalten!
Antwort:
Je öfter Sie sie benutzen, desto einfacher wird es auch, sich zu merken,
welches wofür verwendet wird. Vielleicht hilft es, beim
Skalarvariablenzeichen $ an den Buchstaben S wie Skalar zu denken (oder
wenn Sie in $ nur Dollars sehen - Dollars sind Zahlen und skalar). Das at-
Zeichen @ sieht ein bißchen aus wie ein kleines a. A steht für Array. Und das
Prozentzeichen % für Hashes besteht aus einem Schrägstrich mit zwei
Punkten - einem für den Schlüssel und einem für den Wert. Wenn Sie auf
Arrays oder Hashes zugreifen, denken Sie daran, was Sie haben möchten:
Wollen Sie ein einzelnes Element, nehmen Sie $. Wollen Sie mehrere (eine
Liste), verwenden Sie @.
Frage:
Hashes sind bloß assoziative Arrays, oder nicht? Es sind doch nicht wirklich Hash-
Tabellen?
Antwort:
Doch. »Assoziatives Array« ist eine andere, in früheren Perl-Versionen sogar
»offizielle« Bezeichnung für einen Hash (»Hash« hat sich durchgesetzt, weil es
sich bequemer aussprechen und tippen läßt als »assoziatives Array«,
zumindest fanden das die Perl-Programmierer). Hashes sind intern aber auch
tatsächlich als echte Hash-Tabellen implementiert und haben insbesondere
bei riesigen Datenmengen alle Geschwindigkeitsvorteile eines Hash-
Verfahrens gegenüber einem auf Schlüsselvergleich basierenden Verfahren.
Frage:
Sie verwenden in allen Beispielen einen Hash-Key, um auf einen Wert
zuzugreifen. Gibt es auch einen Weg, mit einem Wert an einen Schlüssel zu
kommen?
Antwort:
Nein. Also, es gibt keine Funktion, die das tut. Sie könnten mit einer foreach-
Schleife und den Hash-Schlüsseln den Hash durchlaufen, auf einen
bestimmten Wert überprüfen und so den entsprechenden Schlüssel
herausfinden. Aber bedenken Sie, dass verschiedene Schlüssel durchaus den
gleichen Wert haben können, die Beziehung von einem Wert zu seinem
Schlüssel also nicht die gleiche ist wie die eines Schlüssels zu seinem Wert.
Der Workshop enthält Quizfragen, die Ihnen helfen sollen, Ihr Wissen zu festigen, und Übungen, die Sie anregen sollen, das eben Gelernte umzusetzen und eigene Erfahrungen zu sammeln. Versuchen Sie, das Quiz und die Übungen zu beantworten und zu verstehen, bevor Sie zur Lektion des nächsten Tages übergehen.
$foo
@foo
%foo
$foo{'key'}
%zeug = qw(1 eins 2 zwei 3 drei 4 vier);
@zahlen = %zeug
$foo = %zeug;
keys, values und each.
split?
length, split und
reverse).
Hier die Antworten auf die Workshop-Fragen aus dem vorigen Abschnitt.
$foo ist eine Skalarvariable.
@foo ist eine Arrayvariable.
%foo ist eine Hash-Variable.
$foo{'key'} ist der dem Schlüssel 'key' zugeordnete Wert im Hash %foo.
%zeug erhält vier Schlüssel/Wert-Paare: '1'/'eins', '2'/'zwei',
'3'/'drei' und '4'/'vier'. Die qw-Funktion setzt die Anführungszeichen vor
und nach jedem Element.
%zeug werden in eine Liste zerlegt und im Array
@zahlen gespeichert (Schlüssel, Wert, Schlüssel, Wert und so weiter)
$foo enthält einen Code, der den internen Zustand des Hash beschreibt.
keys liefert Ihnen eine Liste aller Schlüssel im Hash, die Funktion
values eine Liste aller Werte. Die Funktion each liefert eine Liste von je einem
Schlüssel/Wert-Paar. Mit Hilfe aufeinanderfolgender Aufrufe von each können
Sie alle Paare im Hash durchgehen.
split splittet einen String in eine Liste von Teilstrings. Split wird im allgemeinen
zum Einlesen von Daten verwendet, die man nicht direkt einer Variablen zuweisen
kann, was häufig der Fall ist, wenn man sie aus Dateien liest.
while-Schleife durch
folgenden Code ersetzen, der mit Hilfe von split die eingegebene Zahlenreihe in
eine Liste einzelner Zahlen zerlegt, sie im Array @zahlen speichert und dann mit
foreach durchläuft:
print 'Geben Sie Ihre Zahlen ein, alle in einer Zeile, ';
print "durch Leerzeichen getrennt: \n";
chomp ($input = <STDIN>);
@nums = split(' ', $input);
$count = @nums;
foreach $num (@nums) {
$freq{$num}++;
$sum += $num;
}
#!/usr/bin/perl -w
#
# Satz-Statistik
$in = '' ; # temp Input
@sent = (); # Satz
$words = 0; # Anzahl Woerter
@reversed = 90; # Satz rueckwaerts
print 'Geben Sie einen Satz ein: ';
chomp($in = <STDIN>);
print 'Anzahl der Zeichen: ';
print length $in;
@sent = split(' ', $in);
$words = @sent;
print "\nAnzahl der Woerter: $words\n";
@reversed = reverse @sent;
print "der Satz rueckwaerts: \n";
print "@reversed\n";
#!/usr/bin/perl -w
$in = ''; # temp. Eingabe
%names = (); # Hash: Namen
@raw = (); # temp: rohe Woerter
$fn = ''; # Vorname
while () {
print 'Geben Sie einen Namen ein (Vor- und Nachname): ';
chomp($in = <STDIN>);
if ($in ne '') {
@raw = split(' ', $in);
if ($#raw == 1) { # Normalfall: zwei Woerter
$names{$raw[1]} = $raw[0];
} else { # den Vornamen zusammensetzen
$fn = '';
$i = 0;
while($i < $#raw) {
$fn .= $raw[$i++] . ' ';
}
$names{$raw[$#raw]} = $fn;
}
}
else { last; }
}
foreach $lastname (sort keys %names) {
print "$lastname, $names{$lastname}\n";
}