




Bisher habe ich mich auf die Perl-Elemente beschränkt, die sich überall gleich verhalten, unabhängig davon, ob Sie Ihr Skript auf einem Unix-System, unter Windows oder auf einem Mac ausführen (zumindest habe ich Sie auf Unterschiede, soweit vorhanden, hingewiesen). Zum Glück gibt es, soweit es den Kern der Sprache betrifft, nicht allzu viele Punkte, die eine plattformübergreifende Skripterstellung schwermachen: Ein Hash ist ein Hash ist ein Hash, egal in welcher Sprache Sie ihn betrachten.
Perl enthält aber auch Elemente, die nicht portierbar sind. Bei manchen Elementen hat die Bindung an bestimmte Plattformen einen geschichtlichen Hintergrund. Da Perl ursprünglich für Unix entwickelt wurde, gründen viele vordefinierten Elemente auf Besonderheiten von Unix, die es auf anderen Plattformen nicht gibt. Andere Elemente sind in plattformspezifischen Modulen untergebracht und beziehen sich dann natürlich ausschließlich auf diese Plattform (zum Beispiel die Windows-Registrierdatenbank oder die Mac Toolbox). Wenn Sie sicher sind, dass Ihre Skripts nur auf einer bestimmten Plattform ausgeführt werden, können Sie diese Module nutzen, um plattformspezifische Probleme zu lösen. Aber auch wenn Sie ein Skript erhalten haben, das von einer Plattform auf eine andere portiert werden soll, ist es hilfreich, wenn Sie wissen, welche Elemente welcher Plattform eigen sind.
Heute wollen wir uns einige der plattformspezifischen Elemente von Perl anschauen, die in die Sprache oder die Module Eingang gefunden haben. Insbesondere wollen wir heute folgendes untersuchen:
system
fork und exec erzeugt
Win32::Process und Win32::Registry
Das Unix-Erbe zeigt sich in vielen der vordefinierten Elemente, die direkt von Unix- Tools wie zum Beispiel den Shells entlehnt sind oder sich speziell auf die Verwaltung bestimmter Unix-Dateien beziehen. Deshalb wollen wir in diesem Abschnitt die Elemente von Perl untersuchen, die auf Unix-Systemen nützlich sind:
system, um andere Programme auszuführen
fork, wait und exec neue Prozesse erzeugen und verwalten
Beachten Sie, daß mit Ausnahme der Prozesse viele dieser Elemente auch in Perl- Versionen für andere Systeme verfügbar sein können, unter Umständen aber mit etwas anderem oder begrenzterem Funktionsumfang. Also auch, wenn Sie unter Windows oder auf einem Mac arbeiten, empfehle ich Ihnen, diesen Abschnitt zumindest zu überfliegen, bevor Sie mit dem Teil fortfahren, der sich mit Ihrer Plattform beschäftigt.
Perl-Skripts erben wie Shell-Skripts ihre Umgebung (das heißt den aktuellen Ausführungspfad, den Benutzernamen, die Shell und so weiter) von der Shell, in der sie gestartet wurden (oder von der Benutzer-ID, von der sie ausgeführt werden). Und wenn Sie von Ihrem Perl-Skript aus andere Programme ausführen oder Prozesse starten, erhalten diese ihre Umgebung wiederum von Ihrem Skript. Wenn Sie Perl- Skripts von der Befehlszeile aus ausführen, dürften diese Variablen nicht von großem Interesse für Sie sein. Aber Perl-Skripts, die in anderen Umgebungen ausgeführt werden, können über zusätzliche Variablen verfügen, die sich auf diese Umgebung beziehen, oder weisen für diese Variablen andere Werte auf, als Sie es erwarten. CGI- Skripts verfügen zum Beispiel, wie Sie in Kapitel 16, »Perl für CGI-Skripts«, gelernt haben, über eine Reihe von Umgebungsvariablen, die mit verschiedenen CGI- spezifischen Konzepten verbunden sind.
Perl speichert alle seine Umgebungsvariablen in einem speziellen Hash namens %ENV,
in dem die Namen der Variablen die Schlüssel und die Werte dieser Variablen die
Werte zu den Schlüsseln sind. Umgebungsvariablen werden in der Regel in
Großbuchstaben geschrieben. Um zum Beispiel den Ausführungspfad für Ihr Skript
auszugeben, würden Sie folgende Zeile verwenden:
print "Pfad: $ENV{PATH}\n";
Sie können alle Umgebungsvariablen mit einer regulären foreach-Schleife ausgeben:
foreach $key (keys %ENV) {
print "$key -> $ENV{$key}\n";
}
Wollen Sie von Ihrem Perl-Skript aus Unix-Befehle ausführen? Kein Problem. Rufen
Sie dazu die Funktion system wie folgt auf:
system('ls');
In diesem Fall führt system einfach den Unix-Befehl ls aus, mit dem der Inhalt des
aktuellen Verzeichnisses auf der Standardausgabe ausgegeben wird. Die
auszuführenden Befehle lassen sich auch um Optionen ergänzen, die dann jedoch in
dem String-Argument eingeschlossen sein müssen. Alles, was Sie zusammen mit
einem Shell-Befehl eingeben können (und was für den aktuellen Ausführungspfad
verfügbar ist), können Sie als Argument für system mit aufnehmen.
system("find t -name '*.t' -print | xargs chmod +x &");
system('ls -l *.pl');
Wenn Sie als Argument zu system einen String in doppelten Anführungszeichen
verwenden, wird Perl Variablen interpolieren, bevor es den String an die Shell
übergibt:
system("grep $thing $file | sort | uniq >neueDatei.txt");

Seien Sie recht vorsichtig damit, Daten an die Shell zu übergeben, die Sie nicht persönlich verifiziert haben (zum Beispiel Daten, die irgendein Benutzer über die Tastatur eingegeben hat). Bösartige Benutzer könnten Ihnen so Daten zuspielen, die - bei ungeprüfter Übergabe an die Shell - Ihrem Sys-tem großen Schaden zufügen oder irgend jemandem unberechtigten Zugriff auf Ihr System einräumen könnten. Deshalb sollten Sie zumindest die eingehenden Daten überprüfen, bevor Sie sie an die Shell übergeben. Alternativ gibt es in Perl einen Mechanismus, den sogenannten Taint-Modus, der es Ihnen erlaubt, potentiell unsichere (tainted = vergiftet, befleckt) Daten zu kontrollieren und zu verwalten. Weitere Informationen sind in der perlsec-Manpage enthalten.
Der Rückgabewert der system-Funktion entspricht dem Rückgabewert des Shell-
Befehls: im Erfolgsfall 0 und andernfalls 1 oder größer. Beachten Sie, daß dies genau
umgekehrt ist wie bei den Standardwerten, die Perl für wahr und falsch verwendet.
Wenn Sie also testen wollen, ob bei dem Aufruf von system Fehler aufgetreten sind,
werden Sie ein logisches and anstatt or verwenden müssen:
system('who') and die "who konnte nicht ausgeführt werden\n";
Wenn der Befehl system ausgeführt wird, übergibt Perl das String-Argument einer
Shell (in der Regel /bin/sh), wo die Shell-Metazeichen erweitert werden (zum Beispiel
Variablen oder Dateinamen-Globs) und der Befehl anschließend ausgeführt wird.
Wenn Sie keine Shell-Metazeichen verwenden, können Sie den Prozeß dadurch
beschleunigen, daß Sie system eine Liste von Argumenten anstelle eines einzelnen
Strings übergeben. Das erste Element der Liste sollte der Name des auszuführenden
Befehls sein und alle weiteren Elemente die verschiedenen Argumente zu diesem
Befehl:
system("grep $thing $file"); # startet eine Shell
system("grep", "$thing", "$file");
# umgeht die Shell, ist etwas effizienter
Perl nimmt Ihnen diese Optimierung ab, wenn Ihr String-Argument einfach genug ist - das heißt, wenn es nicht irgendwelche Sonderzeichen enthält, die die Shell bearbeiten muß, bevor das Programm ausgeführt werden kann (zum Beispiel Shell- Variablen oder Dateinamen-Globs).
Unabhängig davon, ob Sie nun ein einfaches String-Argument oder eine Liste von
Argumenten übergeben, löst die system-Funktion am Ende neue Unterprozesse für
jeden der Befehle in ihrem Argument aus. Jeder neue Prozeß erbt seine aktuellen
Umgebungsvariablen von den Werten in %ENV und teilt die Standardeingabe, -ausgabe
und -fehlerausgabe mit dem Perl-Skript. Perl wartet, bis der Befehl zu Ende ausgeführt
ist, bevor es mit dem Skript fortfährt (es sei denn, der Befehl endet auf ein &, so daß
der Befehl im Hintergrund ausgeführt wird - ganz wie das auch in der Shell der Fall
wäre).
Überlegen Sie genau, bevor Sie die
system-Funktion verwenden. Dasystemfür jeden auszuführenden Befehl einen eigenen Prozeß startet (und manchmal auch für die Shell, die diese Befehle ausführt), können diese ganzen zusätzlichen Prozesse Ihr Perl-Skript überlasten. Normalerweise ist es besser, eine Aufgabe mit etwas Code innerhalb Ihres Perl-Skripts zu lösen, als für die gleiche Aufgabe eine Unix-Shell zu starten. Und außerdem ist Perl-Code besser portierbar.
Sie haben bereits gelernt, wie Sie Eingaben über die Standardeingabe oder Datei-
Handles in ein Perl-Skript einlesen. Die dritte Möglichkeit besteht in der Verwendung
von schrägen Anführungszeichen ``, einem geläufigen Paradigma in Unix-Shells.
Schräge Anführungszeichen entsprechen in ihrer Funktionsweise in etwa dem system-
Befehl - beide führen einen Unix-Befehl innerhalb eines Perl-Skripts aus. Der
Unterschied liegt in der Ausgabe. Befehle, die mit system ausgeführt werden, leiten
ihre Ausgabe an die Standardausgabe. Wenn Sie jedoch schräge Anführungszeichen
verwenden, um einen Unix-Befehl auszuführen, wird die Ausgabe des Befehls je nach
Kontext, in dem die schrägen Anführungszeichen verwendet wurden, entweder als
String oder als eine Liste von Strings aufgefangen.
Betrachten wir zum Beispiel den Befehl ls, der eine Liste des aktuellen Verzeichnisses
ausgibt:
$ls = `ls`;
Hier führen die schrägen Anführungszeichen den Befehl ls in einer Unix-Shell aus,
und die Ausgabe des Befehls (die Standardausgabe) wird der Skalarvariablen $ls
zugewiesen. In einem skalaren Kontext (wie bei diesem Beispiel) wird die resultierende
Ausgabe in einem einzigen String gespeichert, in einem Listenkontext wird jede Zeile
der Ausgabe ein eigenes Listenelement.
Wie schon bei system, können Sie jeden Befehl, den Sie in einer Unix-Shell ausführen
können, auch in schräge Anführungszeichen setzen. Der Befehl wird dann in seinem
eigenen Prozeß ausgeführt, erbt seine Umgebungsvariablen von %ENV und teilt auch
Standardeingabe, -ausgabe und -fehlerausgabe. Der Inhalt des Strings in den schrägen
Anführungszeichen wird wie die Strings in doppelten Anführungszeichen von Perl
variableninterpoliert. Der Rückgabestatus des Befehls wird in der Sondervariablen $?
gespeichert. Und wie bei system lautet der Rückgabestatus im Erfolgsfall 0 und
andernfalls 1 oder größer.
Wenn Sie ein Perl-Skript ausführen, läuft es als sein eigener Unix-Prozeß. Für viele
einfache Skripts benötigen Sie unter Umständen nur einen einzigen Prozeß, vor allem
wenn Ihr Skript vornehmlich linear, das heißt Schritt für Schritt vom Anfang bis zum
Ende, abgearbeitet wird. Wenn Sie jedoch beginnen, komplexere Skripts zu erstellen,
in denen verschiedene Teile des Skripts gleichzeitig verschiedene Aufgaben lösen
müssen, werden Sie daran interessiert sein, weitere Prozesse zu erzeugen, die
unabhängig vom Rest des Skripts ausgeführt werden. Hierfür wird die fork-Funktion
verwendet. Nachdem Sie einen neuen Prozeß erzeugt haben, können Sie seine
Prozeß-ID (PID) verfolgen, das Ende des Prozesses abwarten oder ein anderes
Programm in diesem Prozeß ausführen. All dies möchte ich Ihnen in diesem Abschnitt
zeigen.
Neue Prozesse zu erzeugen und deren Verhalten zu steuern, ist eines der Konzepte von Perl für Unix, das sich nur schlecht auf anderen Systemen nachvollziehen läßt. So können Sie zwar mit der Erzeugung neuer Prozesse die Leistung Ihrer Perl-Skripts beträchtlich steigern, aber wenn Ihre Skripts portierbar sein sollen, werden Sie diese Besonderheiten eher vermeiden oder sich überlegen, wie Sie das Problem auf anderen Plattformen umgehen können.
Interessant sind in dieser Hinsicht die sogenannten Threads, eine experimentelle Neueinführung in Perl 5.005, die Hilfe bei der Portierung prozeßbasierter Skripts auf andere Plattformen versprechen. Threads bieten fast den gleichen Leistungsumfang wie Unix-Prozesse, sind jedoch effizienter und lassen sich auf alle Plattformen portieren. Zum Zeitpunkt der Drucklegung dieses Buches sind die Threads jedoch noch absolut neues Terrain, auf dem noch viel experimentiert wird. Ich werde in Kapitel 21, »Ein paar längere Beispiele«, noch einmal kurz darauf eingehen.
Prozesse werden eingesetzt, um verschiedene Teile Ihres Skripts gleichzeitig auszuführen. Wenn Sie in einem Skript einen neuen Prozeß erzeugen, läuft dieser Prozeß unabhängig in einem eigenen Speicherbereich weiter, bis er zu Ende ist oder Sie den Prozeß abbrechen. Sie können von Ihrem Skript aus so viele Prozesse starten, wie Sie benötigen. Grenzen sind Ihnen nur durch Ihr System gesetzt.
Wozu benötigen Sie mehrere Prozesse? Zum Beispiel, wenn Sie verschiedene Teile Ihres Programms gleichzeitig ausführen wollen oder mehrere Kopien Ihres Programms gleichzeitig ausgeführt werden sollen. Häufig werden Prozesse zum Einrichten von netzwerkbasierten Servern eingesetzt, die darauf warten, daß ein Client eine Verbindung herstellt und diese Verbindung dann in irgendeiner Weise bearbeitet. Wenn ein solcher Server nur einen einzigen Prozeß verwendet und es wird eine Verbindung hergestellt, dann »erwacht« der Server und bearbeitet die Verbindung (parst die Eingabe, holt Werte aus einer Datenbank, liefert Dateien zurück - was auch immer). Solange der Server seine Verbindung bearbeitet, muss jede zweite Verbindung, die gerade ankommt, warten. Bei einem sehr stark frequentierten Server kann das bedeuten, daß eine ganze Menge von Verbindungen in der Warteschleife hängen und darauf warten, daß der Server bald fertig ist und zur Bearbeitung der nächsten Verbindung schreitet.
Wenn Sie Ihren Server so einrichten, daß er mit Prozessen arbeitet, kann Ihr Skript aus einem Hauptteil bestehen, der nur auf die Verbindungen wartet, und aus einem zweiten Teil, der diese Verbindungen bearbeitet. Erhält der Hauptserver dann eine Verbindung, löst er einen neuen Prozeß aus, reicht die Verbindung an diesen neuen Prozeß zur Bearbeitung weiter und ist dann wieder frei, um auf neue eingehende Verbindungen zu warten. Der zweite Prozeß verarbeitet die Eingaben aus der Verbindung und stirbt, wenn er seine Aufgabe erledigt hat. Diese Vorgehensweise kann für jede neue Verbindung wiederholt werden, so daß die Verbindungen parallel abgearbeitet werden und nicht seriell.
Am Beispiel der Netzwerk-Server läßt sich gut darlegen, warum Prozesse so nützlich sind. Sie brauchen aber nicht unbedingt ein Netzwerk für den Einsatz von Prozessen. Immer, wenn Sie verschiedene Teile Ihres Skripts parallel ausführen oder einen bearbeitungsintensiven Teil Ihres Skripts vom Hauptteil trennen wollen, bieten sich Prozesse als Lösung an.
Wenn Sie Threads bereits von Sprachen wie Java her kennen, könnten Sie dem Glauben erliegen, Sie verstünden auch schon, was Prozesse sind. Doch seien Sie vorsichtig. Im Gegensatz zu Threads sind laufende Prozesse völlig unabhängig voneinander. Die Eltern- und Kindprozesse laufen unabhängig voneinander ab. Es werden kein Speicherplatz und auch keine Variablen geteilt, und es ist ziemlich schwierig, Informationen zwischen den Prozessen auszutauschen. Für die Kommunikation zwischen den Prozessen müssen Sie einen besonderen Mechanismus einrichten, den sogenannten IPC (Interprocess Communication). Im Rahmen dieses Buches ist kein Platz, um näher auf IPC einzugehen, aber im Vertiefungsabschnitt am Ende dieses Kapitels werde ich Ihnen einige Hinweise geben.
Um in einem Perl-Skript einen neuen Prozeß zu erzeugen, verwendet man die fork-
Funktion. fork, das keine Argumente übernimmt, erzeugt einen neuen zweiten
Prozeß zusätzlich zu dem Prozeß für das Originalskript. Jeder neue Prozeß ist ein Klon
des ersten, mit den gleichen Werten für die gleichen Variablen (auch wenn er diese
nicht mit dem Elternprozeß teilt, denn sie befinden sich in unterschiedlichen
Speicherbereichen). Der Kindprozess führt parallel das gleiche Skript bis zum Ende
aus und verwendet dabei die gleiche Umgebung sowie die gleiche Standardein- und -
ausgabe wie der Elternprozeß. Ab der fork-Funktion ist es, als ob Sie zwei Kopien des
gleichen Prozesses gestartet hätten.
Das gleiche Skript zweimal auszuführen, ist normalerweise jedoch nicht der Grund,
einen neuen Prozeß zu erzeugen. In der Regel setzen Sie einen neuen Prozeß (auch
Kind genannt) ein, um etwas anderes als den ersten Prozeß (auch Eltern genannt)
auszuführen. Am häufigsten wird fork deshalb in if-Bedingungen verwendet, die den
Rückgabewert von fork abfragen. Je nachdem ob der aktuelle Prozeß ein Eltern- oder
ein Kindprozeß ist, liefert fork unterschiedliche Werte zurück. Für den Elternprozeß
wird die Prozeß-ID (PID) des neuen Prozesses zurückgeliefert, und für den Kindprozeß
lautet der Rückgabewert 0 (wenn, aus was für Gründen auch immer, fork nicht
ausgeführt wird, lautet der Rückgabewert undef). Durch Testen dieses
Rückgabewertes können Sie im Kindprozeß anderen Code ausführen als im
Elternprozeß.
Das Codegerüst zum Erzeugen von Prozessen sieht meist folgendermaßen aus:
if (defined($pid = fork)) { # fork funktionierte
if ($pid) { # pid ist eine Zahl, dies ist der Elternprozess
&parent();
} else { # pid ist 0, dies ist der Kindprozess.
&child();
}
} else { # fork funktionierte nicht, neuer Versuch oder Abbruch
die "Fork funktionierte nicht...\n";
}
In diesem Beispiel ruft die erste Zeile fork auf und speichert das Ergebnis in der
Variablen $pid (die Variable für die Prozeß-IDs wird fast immer $pid genannt, Sie
können aber auch einen beliebigen anderen Namen vergeben). Es gibt drei mögliche
Ergebnisse: eine Prozeß-ID, 0 oder undef. Der Aufruf von define in der ersten Zeile
prüft, ob die Funktion erfolgreich ausgeführt wurde. Sollte dies nicht der Fall sein,
springt die Skriptausführung zu dem äußeren else und bricht mit einer Fehlermeldung
ab.
Wenn
forkaufgrund eines Fehlers nicht ausgeführt wird, wird die aktuelle Fehlermeldung (oder Fehlernummer, je nachdem, was Sie verwenden) in der globalen Systemvariablen$!gespeichert. Da vielefork-Fehler dazu neigen, vorübergehender Art zu sein (ein überladenes System hat unter Umständen im Moment keine neuen Prozesse zur Verfügung), testen einige Perl-Programmierer, ob$!den String »No more Processes« enthält, warten dann einen Augenblick und versuchen später erneut, mitforkzu verzweigen.
Ein erfolgreiches Ergebnis ist entweder eine 0 oder eine Zahl für die Prozeß-ID des
neuen Prozesses. Das Ergebnis teilt dem Skript mit, welcher Prozeß es ist. In obigem
Codefragment habe ich zwei fiktive Subroutinen, &parent() und &child(),
aufgerufen, die unterschiedliche Teile des Skripts ausführen, je nachdem ob das Skript
als Elternprozeß oder als Kindprozeß ausgeführt wird.
Sehen Sie im folgenden ein einfaches Beispiel für ein Skript, das in drei Kindprozesse
verzweigt und im Elternprozeß sowie den drei Kindprozessen entsprechende
Meldungen ausgibt. Am Ende des Skripts wird die Meldung »Ende« ausgegeben.
1: #!/usr/bin/perl -w
2: use strict;
3:
4: my $pid = undef;
5:
6: foreach my $i (1..3) {
7: if (defined($pid = fork)) {
8: if ($pid) { #Eltern
9: print "Eltern: Kind $i ($pid) gestartet \n";
10: } else { #Kind
11: print "Kind $i: wird ausgeführt\n";
12: last;
13: }
14: }
15: }
16:
17: print "Ende...\n";
Die Ausgabe dieses Skripts wird in etwa folgendermaßen aussehen (vielleicht variiert die Ausgabe auf Ihrem System etwas):
% prozesse.pl
Eltern: Kind 1 (8577) gestartet
Eltern: Kind 2 (8578) gestartet
Eltern: Kind 3 (8579) gestartet
Ende...
%
Kind 1: wird ausgeführt
Ende...
Kind 2: wird ausgeführt
Kind 3: wird ausgeführt
Ende...
Ende...
Diese Ausgabe ist vielleicht etwas überraschend. Die Ausgaben der Prozesse sind
vermischt, und wo kommt der zusätzliche Prompt in der Mitte her? Warum gibt es vier
Ende...-Meldungen?
Die Antwort auf all diese Fragen liegt darin, wie die Prozesse ausgeführt werden und was zu welcher Zeit ausgegeben wird. Beginnen wir unsere Betrachtungen mit dem, was in dem Elternprozeß passiert:
$pid die Prozeß-ID des neuen Prozesses abgelegt.
$pid einen Wert ungleich Null hat. Wenn ja, wird für jeden
verzweigten Prozeß eine Meldung ausgegeben (Zeilen 8 und 9).
foreach-Schleife (noch zweimal)
wiederholt.
Ende... ausgegeben.
All dies geschieht ziemlich schnell, so daß die Ausgabe des Elternprozesses sehr
schnell erfolgt. Kommen wir jetzt zu den drei Kindprozessen, deren Ausführung direkt
nach der fork-Funktion beginnt:
$pid ab. Da $pid für jeden der drei Kindprozesse 0 ist,
ergibt der Test in Zeile 8 falsch, und die Ausführung wird in Zeile 10 fortgesetzt.
Anschließend wird die Meldung in Zeile 11 ausgegeben.
foreach-Schleife wird direkt mit last verlassen. Ohne ein last an dieser
Stelle würde der Kindprozeß fortfahren, die Schleife zu wiederholen (denken Sie
daran, daß der Kindprozeß genau dort einsetzt, wo fork aufhört. Er ist ein Klon
des Elternprozesses).
Ende... ausgegeben.
Die Ausgaben der Prozesse mischen sich beim Schreiben an die Standardausgabe. Da
die Kindprozesse einige Zeit benötigen, bevor sie mit der Ausführung beginnen, ist der
Elternprozeß bereits beendet, und seine Ausgaben sind auf dem Bildschirm, noch
bevor überhaupt einer der Kindprozesse begonnen hat. Beachten Sie, daß die Zeile,
die »Ende...« ausgibt, sowohl für den Eltern- als auch den Kindprozeß ausgeführt
wird; da der Kindprozeß den gleichen Code abarbeitet wie der Elternprozeß, wird er
über seinen else-Block hinaus mit der Ausführung des Codes fortfahren.
Unter Umständen ist dieses Verhalten jedoch unerwünscht. Vielleicht soll der Elternprozeß erst nach dem Kindprozeß beendet werden, oder der Kindprozeß soll gestoppt werden, wenn ein spezieller Codeblock ausgeführt worden ist. Oder Sie wollen, daß der Elternprozeß wartet, bis der letzte Kindprozeß beendet ist, bevor der nächste Kindprozeß gestartet wird. Hierzu müssen Sie in die Prozeßverwaltung einsteigen, die ich im nächsten Abschnitt besprechen werde.
Einen Kindprozeß mit fork zu starten und dann die Ausführung dieses Prozesses
einfach laufen lassen, ist wie wenn man ein vierjähriges Kind frei in einer öffentlichen
Anlage herumlaufen ließe. Sie erhalten zwar Ergebnisse, aber diese werden nicht
unbedingt Ihren Erwartungen (oder denen anderer Anwender) entsprechen. Hier
kommt die Prozeßsteuerung ins Spiel. Die zwei Funktionen, exit und wait, helfen
Ihnen, Ihre Prozesse zu kontrollieren und zu steuern.
Beginnen wir mit der exit-Funktion. Die exit-Funktion bricht ganz einfach die
Ausführung des aktuellen Skripts an der Stelle ab, wo die Funktion steht. Sie
entspricht in dieser Hinsicht in etwa der Funktion die. Während die Funktion die das
Skript jedoch mit einem Fehlerstatus (unter Unix) abbricht und eine Fehlermeldung
ausgibt, beendet exit das Programm mit einem normalen Statusargument (0 für
Erfolg, andernfalls 1).
exit wird meistens dazu verwendet, einen Kindprozeß daran zu hindern, mehr vom
Code des Elternprozesses auszuführen, als erwünscht ist. Wenn Sie exit an das Ende
des Codeblocks für den Kindprozeß setzen, wird der Kindprozeß nur bis zu diesem
Punkt ausgeführt und bricht dort ab. Lassen Sie uns deshalb in dem kleinen Skript
prozesse.pl aus dem letzten Abschnitt den Aufruf von last durch einen Aufruf von
exit ersetzen:
# ...
} else { #child
print "Kind $i: wird ausgeführt\n";
exit;
}
Mit dieser Änderung wird der Kindprozeß seine Nachricht ausgeben und dann
abbrechen. Er wird die foreach-Schleife nicht erneut starten und auch nicht die
»Ende...«-Anweisung ausgeben. Der Elternprozeß dagegen, der den anderen Teil der
if-Anweisung ausführt, führt die »Ende...«-Anweisung aus, nachdem die Schleife
beendet ist. Die Ausgabe dieser Version des Skripts sieht folgendermaßen aus:
% procexit.pl
Eltern: Kind 1 (11828) gestartet
Eltern: Kind 2 (11829) gestartet
Eltern: Kind 3 (11830) gestartet
Ende...
%
Kind 1: wird ausgeführt
Kind 2: wird ausgeführt
Kind 3: wird ausgeführt
Wie schon im vorigen Beispiel sind die Ausgaben der Eltern- und Kindprozesse vermischt, und der Elternprozeß wird vor den Kindprozessen abgeschlossen.
Wenn Sie noch mehr Einfluß darauf nehmen wollen, wann die Kindprozesse
ausgeführt werden und wann der Elternprozeß beendet wird, verwenden Sie die
Funktionen wait und waitpid. Beide Funktionen bewirken das gleiche: Die
Ausführung des aktuellen Prozesses (meist der Elternprozeß) wird so lange angehalten,
bis der Kindprozeß zu Ende ist. Damit wird der vermischten Ausgabe ein Ende bereitet
und der Elternprozeß erst nach den Kindprozessen beendet. In komplizierteren Skripts
als unserem Beispiel kann man auf diese Weise verhindern, daß das Skript
sogenannte »Zombie«-Prozesse zurückläßt (das sind Kindprozesse, deren Ausführung
beendet ist, die aber immer noch im System herumhängen und Ressourcen belegen).
Der Unterschied zwischen wait und waitpid liegt darin, daß wait keine Argumente
übernimmt und darauf wartet, daß irgendeiner der Kindprozesse zurückkehrt. Wenn
Sie fünf Prozesse auslösen und dann wait aufrufen, wird wait ein erfolgreiches
Ergebnis zurückliefern, wenn einer der fünf Kindprozesse beendet wird. Waitpid
hingegen übernimmt als Argument eine bestimmte Prozeß-ID und wartet dann darauf,
daß dieser bestimmte Kindprozeß beendet wird (denken Sie daran, daß der
Elternprozeß die PID des Kindprozesses als Rückgabewert der fork-Funktion erhält).
Sowohl wait als auch waitpid liefern die PID des Kindprozesses zurück, der beendet
wurde, oder -1, wenn im Moment keine Kindprozesse ausgeführt werden.
Kehren wir noch einmal zu unserem Prozeßbeispiel zurück, das drei Kindprozesse in
einer foreach-Schleife auslöst. Mit exit haben wir das Verhalten der Kindprozesse
modifiziert, jetzt wollen wir das Verhalten des Elternprozesses ändern. Dazu fügen wir
innerhalb des Elternteils der Bedingung einen Aufruf an wait und eine weitere
Meldung ein:
if ($pid) { #Eltern
print "Eltern: Kind $i ($pid) gestartet \n";
wait;
print "Eltern: Kind $i ($pid) beendet \n";
} else { ....
In der letzten Version des Beispiels gab der Eltern-Code lediglich die erste Meldung
aus. Dann wiederholte sich die foreach-Schleife und löste in rascher Folge drei
Kindprozesse aus. In dieser Version wird der Kindprozeß erzeugt, der Elterncode gibt
die erste Meldung aus und wartet dann, bis der Kindprozeß zu Ende ist. Dann gibt er
die zweite Meldung aus. Der nächste Durchlauf der Schleife erfolgt erst, wenn der
aktuelle Kindprozeß abgeschlossen und beendet wurde. Die Ausgabe dieser
Skriptversion lautet:
% procwait.pl
Eltern: Kind 1 (11876) gestartet
Kind 1: wird ausgeführt
Eltern: Kind 1 (11876) beendet
Eltern: Kind 2 (11877) gestartet
Kind 2: wird ausgeführt
Eltern: Kind 2 (11877) beendet
Eltern: Kind 3 (11878) gestartet
Kind 3: wird ausgeführt
Eltern: Kind 3 (11878) beendet
Ende...
%
Auffällig hieran ist, daß die Ausführung sehr regelmäßig ist. Jeder Kindprozeß wird verzweigt, ausgeführt und beendet, bevor der nächste Prozeß startet. Und der Elternprozeß endet erst, nachdem der dritte Kindprozeß abgeschlossen ist.
Wenn aber wie in obigem Beispiel alle Kindprozesse hintereinander ausgeführt
werden, stellt sich die Frage, wozu man überhaupt Prozesse einsetzt (zumal jeder
Prozeß Zeit benötigt, um in Gang zu kommen, und zusätzliche Prozessorressourcen
belegt). Nun, die wait-Funktion ist so flexibel, daß man ja nicht unbedingt warten
muss, bis der zuletzt ausgelöste Kindprozeß beendet ist, bevor man einen neuen
Prozeß startet - Sie können auch fünf Prozesse starten und dann später in Ihrem
Skript wait fünfmal aufrufen, um alle Prozesse aufzuräumen. Ein Beispiel dazu werde
ich Ihnen weiter hinten in dieser Lektion zeigen, wo wir uns an einem größeren Skript
versuchen werden.
Eine letzte Funktion, die im Zusammenhang mit der Steuerung von Prozessen noch
genannt werden sollte, ist die Funktion kill, die ein Kill-Signal an einen Prozeß
sendet. Um kill zu verwenden, müssen Sie etwas über Signale verstehen. Aus
Platzgründen möchte ich hier auf eine Beschreibung der Signale wissen. Sie finden
aber einige Hinweise im Vertiefungsabschnitt und der perlfunc-Manpage.
Wenn Sie mit fork einen neuen Prozeß starten, erzeugt dieser Prozeß einen Klon des
aktuellen Skripts und führt dieses von der aktuellen Position aus fort. Manchmal
möchte man jedoch, daß der aktuelle Prozeß mit dem, was er gerade macht, aufhört
und statt dessen ein anderes Programm ausführt. Hierfür gibt es die Funktion exec.
Die exec-Funktion bewirkt, daß der aktuelle Prozeß die Ausführung des aktuellen
Skripts abbricht und statt dessen etwas anderes ausführt. Dieses »etwas anderes« ist in
der Regel ein anderes Programm oder Skript, das exec als Argument übergegeben
wird:
exec("grep $who /etc/passwd");
Für die Argumente zu exec gelten die gleichen Regeln wie bei system. Wenn Sie ein
einfaches String-Argument verwenden, übergibt Perl dieses Argument zuerst an die
Shell. Mit einer Liste von Argumenten können Sie den Shell-Prozeß umgehen. Genau
genommen, sind die Ähnlichkeiten zwischen exec und system kein Zufall - die
Funktion system ist vielmehr eine Kombination aus fork und exec.
Sobald Perl auf ein exec trifft, bedeutet dies das Ende für das Skript. exec überträgt
die Kontrolle an das neue auszuführende Programm; von dem alten Skript werden
keine weiteren Zeilen ausgeführt.
Zusätzlich zu den bisher in diesem Kapitel beschriebenen Funktionen gibt es in Perl unter den vordefinierten Funktionen noch eine ganze Reihe weiterer prozeßbezogener Funktionen und kleinerer Hilfsfunktionen, die Informationen über verschiedene Teile des Systems liefern. Da sich diese Funktionen ausschließlich auf Unix-Systemdateien und -Elemente beziehen, sind die meisten von ihnen auf anderen Systemen nicht verfügbar (wenn auch die Entwickler, die Perl auf diese Systeme portieren, immer mal wieder versuchen, rudimentäre Entsprechungen für das Verhalten dieser Funktionen zu erzeugen).
Tabelle 18.1 gibt Ihnen einen Überblick über die meisten dieser Funktionen. Weitere Informationen zu den einzelnen Funktionen finden Sie in Anhang A, »Perl- Funktionen«, oder der perlfunc-Manpage.
Tabelle 18.1: Unix-bezogene Funktionen
Perl für Windows unterstützt die meisten der grundlegenden Unix-Features und
enthält eine Reihe von Erweiterungen für Win32. Wenn Sie die ActiveState-Version
von Perl für Windows installiert haben, stehen Ihnen die Win32-Module als Teil des
Pakets zur Verfügung. Wenn Sie Perl für Windows selbst kompilieren, benötigen Sie
das Paket libwin32 von CPAN (siehe http://www.perl.com/CPAN-local/modules/
by-module/Win32/ wegen der neuesten Version). Ansonsten ist die Funktionalität die
gleiche.
Frühere Versionen von Perl für Windows waren wesentlich unübersichtlicher hinsichtlich der Frage, welche Module und Elemente in welchem Paket zur Verfügung stehen. Ist Ihre Version von Perl für Windows älter als 5.005 (oder die ActiveState-Version von Perl älter als Build 500), sollten Sie Ihre Software aktualisieren, um sicherzustellen, daß Sie die neueste und beste Version haben.
Wenn Sie mit irgendeinem der Aspekte von Perl unter Win32 Probleme haben, gibt
es eine Reihe von hilfreichen Quellen. Beginnen Sie mit den von mir bereits
erwähnten »Häufig gestellten Fragen« (FAQs) für Perl für Win32 (zu finden unter
http://www.activestate.com/support/faqs/win32/).
Bis auf einige wenige Ausnahmen lassen sich die meisten Unix-bezogenen Perl-
Features auf Windows übertragen, wobei die Anwendung allerdings meist etwas vom
Unix-Original abweicht. Die größte nennenswerte Ausnahmen sind fork und seine
verwandten Funktionen, die nicht unterstützt werden. Dennoch können Sie mit
system, exec, schrägen Anführungszeichen oder einer der Win32-Erweiterungen ein
anderes Programm von einem Perl-Skript aus ausführen (mehr dazu später).
Die system-Funktion, exec und die schrägen Anführungszeichen funktionieren auch in
Perl für Windows. Die »Shell« für diese Befehle ist cmd.exe für Windows NT oder
command.com für Windows 95. Befehle und Argumentlisten für diese Befehle müssen
den Windows-Konventionen folgen, einschließlich der Pfadnamen und des Datei-
Globbings.
Wenn Sie ein Unix-Skript, das mit Hilfe von
systemoder den schrägen Anführungszeichen Unix-Hilfsprogramme aufruft, nach Windows portieren wollen, genügt es nicht, daß Ihre Perl-Versionsystemund schräge Anführungszeichen unterstützt. Sie müssen auch Windows-Entsprechungen für die augerufenen Unix-Hilfsprogramme finden.
Funktionen, die sich auf ganz spezielle Unix-Features beziehen (wie die in Tabelle
18.1) lassen sich mit großer Wahrscheinlichkeit mit Perl für Windows nicht ausführen.
Es gibt noch eine Reihe spezialisierter Funktionen, auf deren Beschreibung ich in
diesem Buch verzichtet habe und die ebenfalls unter Windows nicht ausgeführt
werden können (beispielsweise Funktionen für die Kommunikation zwischen den
Prozessen (interprocess communication) oder Low-Level-Netzwerkfunktionen).
Allgemein kann man jedoch sagen, daß die meisten Perl-Funktionen, die Sie
verwenden, auch in Perl für Windows verfügbar sind. Eine komplette Liste der nicht
implementierten Funktionen findet sich in den häufig gestellten Fragen (FAQs) für Perl
für Win32 unter http://www.activestate.com/support/faqs/win32/ (schauen Sie
auch im Abschnitt »Implementation Quirks« (Implementierungstricks) nach).
Die Perl-Erweiterungen für Windows bestehen aus zwei Teilen: einem Satz von
vordefinierten Win32-Subroutinen und einer Reihe zusätzlicher Win32-Module für
fortgeschrittene Techniken (zum Beispiel Win32::Registry oder Win32::Process).
Die Win32-Subroutinen bestehen vornehmlich aus Routinen zur Abfrage von
Systeminformationen sowie aus einer Reihe von kleineren Hilfsroutinen. Wenn Sie
Perl für Windows laufen haben, müssen Sie zur Verwendung dieser Subroutinen
keines der Win32-Module importieren. In Tabelle 18.2 sind einige der Win32-
Subroutinen aufgelistet, die in Perl für Windows zur Verfügung stehen.
Weitere Informationen zu diesen Subroutinen finden Sie in den häufig gestellten
Fragen zu Perl für Win32. Besonders hilfreich fand ich persönlich auch die Seiten von
Philippe Le Berre unter http://www.inforoute.cgs.fr/leberre1/main.htm.
Tabelle 18.2: Vordefinierte Win32-Subroutinen
Mit Hilfe der grundlegenden Win32-Subroutinen können Sie von Perl aus auf die
grundlegenden Windows-Features und Systeminformationen zugreifen. Durch
Installation des libwin32-Moduls (oder durch Verwendung der ActiveState-Version
von Perl für Windows) erhalten Sie darüber hinaus Zugriff auf Win32-Module, die
Ihnen eine Vielzahl fortgeschrittener Windows-Features erschließen1. Ein äußerst
praktisches Element der Win32-Module ist die Subroutine Win32::MsgBox, mit der
man einfache modale Dialogfenster von einem Perl-Skript aus aufspringen lassen
kann. Win32::MsgBox übernimmt bis zu drei Argumente: den Text, der im
Dialogfenster angezeigt werden soll, einen Code für das Symbol im Dialogfenster und
für die Kombination von Schaltern sowie den Text für die Titelleiste des
Dialogfensters. Der folgende Code wird Ihnen das Dialogfenster zur linken von
Abbildung 18.1 liefern:
Win32::MsgBox("Ich kann das nicht tun!");

Der folgende Code erzeugt ein Dialogfenster mit zwei Schaltern, OK und Abbrechen und einem Fragezeichensymbol (zu sehen auf der rechten Seite von Abbildung 18.1):
Win32::MsgBox("Sind Sie sicher, daß Sie das Objekt löschen wollen?", 33);
Das zweite Argument ist der Code für die Anzahl der Schalter und den Typ des Symbols. In Tabelle 18.3 sind die verschiedenen Kombinationsmöglichkeiten für die Schalter zusammengestellt.
Tabelle 18.4 enthält die Codes für die verschiedenen Symbole.
Das zweite Argument für Win32::MsgBox erhalten Sie, indem Sie sich in beiden
Tabellen für je eine Option entscheiden und die Codewerte aus beiden Tabellen
addieren. So ergibt zum Beispiel das Symbol für Ausrufezeichen (48) zusammen mit
den Schaltern Ja und Nein (4) die Codezahl 52.
Der Rückgabewert von Win32::MsgBox hängt von den Schaltern ab, die Sie im
Dialogfenster verwendet haben und die der Benutzer angeklickt hat. Tabelle 18.5
zeigt die möglichen Rückgabewerte.
Perl für Windows enthält keine Unterstützung für fork. Diese Funktion basiert zu stark
auf Unix-spezifischen Eigenheiten. Es ist jedoch möglich, neue Prozesse zu starten,
die andere Programme ausführen (entspricht einem fork gefolgt von einer exec-
Funktion). Am einfachsten geschieht dies mit Hilfe von system oder den schrägen
Anführungszeichen oder indem man das aktuelle Skript mit exec anhält. Alternativ
kann aber auch eines der Module Win32::Spawn oder Win32::Process eingesetzt
werden.
Win32::Spawn ist Teil der grundlegenden Subroutinen für Win32 und stellt eine
wirklich einfache Möglichkeit dar, einen anderen Prozeß zu starten. Das Modul
Win32::Process ist neueren Datums, robuster und hält sich an die
Modulkonventionen, es ist jedoch auch schwieriger zu verstehen und einzusetzen.
Um mit Win32::Spawn einen neuen Prozeß zu erzeugen, benötigen Sie drei
Argumente: den vollen Pfadnamen für den Befehl, der in dem neuen Prozeß
ausgeführt werden soll, die Argumente für diesen Befehl (einschließlich des
Befehlsnamens) und eine Variable, die die Prozeß-ID für den neuen Prozeß enthält. Im
folgenden sehen Sie ein Beispiel, das Notepad auf Windows 95 mit einer temporären
Datei in C:\tempfile.txt startet. Sie fängt auch Fehler ab:
my $command = "c:\\windows\\notepad.exe";
my $args = "notepad.exe c:\\tempfile";
my $pid = 0;
Win32::Spawn($command, $args, $pid) || &error();
print "Gestartet! Die neue PID lautet $pid.";
sub error {
my $errmsg = Win32::FormatMessage(Win32::GetLastError());
die "Fehler: $errmsg\n";
}
Ärgerlich an Win32::Spawn ist jedoch, daß der neue Prozeß - in diesem Fall Notepad
- minimiert angezeigt wird, so daß es den Anschein hat, als ob nichts passiert.
Außerdem fährt das Perl-Skript in der Ausführung fort, während der neue Prozeß
läuft.
Das Win32::Process-Modul handhabt Prozesse wesentlich vernünftiger. Dafür ist es
jedoch auch wesentlich komplexer und objektorientiert ausgelegt, was bedeutet, daß
die Syntax etwas abweicht (da Sie die Grundlagen bereits in Kapitel 13,
»Gültigkeitsbereiche, Module und das Importieren von Code«, kennengelernt haben,
sollten Sie damit keine Schwierigkeiten haben).
Die Erzeugung eines Win32::Process-Objekts ähnelt in etwa der Verwendung von
Win32::Spawn. Wie bei Spawn benötigen Sie einen Befehl und eine Liste von
Argumenten, doch ist dies nicht alles. Um ein Win32::Process-Objekt zu erzeugen,
müssen Sie zuerst sicherstellen, daß Sie Win32::Process importiert haben:
use Win32::Process;
Rufen Sie anschließend die Methode Create auf, um Ihr neues Prozeßobjekt zu
erzeugen (Sie benötigen eine Variable, die das Objekt aufnimmt):
my $command = "c:\\windows\\notepad.exe";
my $args = "notepad.exe c:\\tempfile";
my $process; # Prozess-Objekt
Win32::Process::Create($process,
$command,
$args,
0,
DETACHED_PROCESS,
'.') || &error();
(Ich habe hier die Definition für die Fehlersubroutine fortgelassen, um Platz zu sparen).
Win32::Process erwartet folgende Argumente:
DETACHED_PROCESS ist die geläufigste, CREATE_
NEW_CONSOLE ist manchmal auch ganz hilfreich
Wenn Sie Ihren neuen Prozeß auf diese Weise starten, wird Notepad im
Vollbildmodus zur Bearbeitung der Datei in C:\tempfile gestartet. Das ursprüngliche
Perl-Skript wird immer noch ausgeführt.
Damit der Elternprozeß wartet, bis der Kindprozeß zu Ende ausgeführt ist, müssen Sie
die Wait-Methode verwenden (beachten Sie das große W, denn es ist nicht die wait-
Funktion von Perl gemeint). Sie müssen Wait als eine objektorientierte Methode des
Prozeßobjekts aufrufen:
$process->Wait(INFINITE);
In diesem Fall wartet der Elternprozeß, bis der Kindprozeß beendet ist. Sie können
Wait aber auch als Argument eine Anzahl an Millisekunden mitgeben, die der
Elternprozeß warten soll, bis er mit der Ausführung fortfährt.
Das Win32::Process-Modul verfügt neben Wait auch noch über folgende Methoden:
Kill, um den neuen Prozeß zu beenden
Suspend, um den Prozeß vorübergehend anzuhalten
Resume, um einen mit Suspend angehaltenen Prozeß wieder aufzunehmen
GetPriorityClass und SetPriorityClass, um die Priorität eines Prozesses zu
ermitteln und zu ändern
GetExitCode, um herauszufinden, warum ein Prozeß abgebrochen wurde
Weitere Informationen über Win32:Process finden Sie in der Dokumentation, die den
Win32-Modulen beiliegt, oder in der Online-Dokumentation unter http://
www.activestate.com/activeperl/docs.
Die Windows-Registrierdatenbank ist ein großes Archiv mit Informationen über Ihr
System, seine Konfiguration und die darauf installierten Programme. Mit dem
objektorientierten Modul Win32::Registry können Sie von einem Perl-Skript aus in
dieser Windows-Registrierdatenbank Werte auslesen, ändern und hinzufügen.
Wenn Sie nicht mit der Windows-Registrierdatenbank vertraut sind, sollten Sie von Ihren Perl-Skripts aus nicht damit herumspielen. Sie können Ihr System lahmlegen, wenn Sie in der Registrierdatenbank etwas ändern, was nicht geändert werden darf. Sie können auch das Windows-Programm
regeditdazu verwenden, um die Windows-Registrierdatenbank einzusehen und zu ändern.
Die Windows-Registrierdatenbank besteht aus einer baumartigen Hierarchie von
Schlüsseln und Werten. Auf oberster Ebene enthält die Registrierdatenbank mehrere
Teilbäume, beispielsweise HKEY_LOCAL_MACHINE für Informationen über die
Konfiguration des lokalen Rechners oder HKEY_CURRENT_USER für Informationen über
den gerade eingeloggten Benutzer. Welche Teilbäume im Detail vorhanden sind,
hängt davon ab, ob Sie Windows NT oder Windows 95 verwenden. Unter jedem
Teilbaum gibt es eine Vielzahl von Schlüssel/Werte-Sätzen - ähnlich wie bei einem
Hash, nur daß diese auch verschachtelt sein können (ein Schlüssel kann auf einen
ganzen anderen Hash-Baum verweisen).
Wenn Sie das Modul Win32::Registry importieren (mit use Win32::Registry),
erhalten Sie für jeden obersten Teilbaum ein Schlüsselobjekt, zum Beispiel
$HKEY_LOCAL_MACHINE. Mit Hilfe der verschiedenen Methoden von Win32::Registry
können Sie jeden Teil der Windows-Registrierdatenbank öffnen, sichten und
verwalten.
Um das Win32::Registry-Modul optimal nutzen und die verschachtelte Hash-Struktur
der Registrierdatenbank-Schlüssel bearbeiten zu können, sind Kenntnisse über
Referenzen unerläßlich. In Tabelle 18.6 finden sie einige der Win32::Registry-
Methoden und deren Argumente. Wenn Sie das Kapitel zu den Referenzen gelesen
haben, werden Sie diese Methoden besser verstehen.
Bevor Sie mit irgendeinem Teil der Registrierdatenbank arbeiten können, müssen Sie
zuerst die Methode Open für eines der obersten Unterschlüsselobjekte aufrufen
(vergessen Sie nicht, use Win32::Registry oben in Ihr Skript aufzunehmen):
use Win32::Registry;
my $reg = "SOFTWARE";
my ($regobj, @keys);
$HKEY_LOCAL_MACHINE->Open($reg,$regobj)||
die "Registrierung kann nicht geöffnet werden\n";
Dann können Sie die verschiedenen Methoden der Registrierdatenbank für das neue
Registry-Objekt aufrufen:
$regobj->GetKeys(\@keys);
$regobj->Close();
Tabelle 18.6: Win32:-Registrierdatenbank-Methoden
Für weitere Informationen über Win32:Process ist die Dokumentation, die den
Win32-Modulen beiliegt, sehr hilfreich. Empfehlen kann ich auch die Seiten von
Philippe Le Berre unter http://www.inforoute.cgs.fr/leberre1/main.htm. in
denen viele Beispiele und Hinweise auf die Verwendung von Win32::Registry zu
finden sind.
Die Win32-Module, die mit der ActiveState-Version von Perl ausgeliefert werden und
in libwin32 zusammengefaßt sind, umfassen eine Unzahl von Modulen zur
Bewältigung der verschiedenen Aspekte von Windows-Operationen. Mein kurzer
Exkurs in Win32::Process und Win32::Registry hat dabei nur die Oberfläche
gestreift. Und zusätzlich zu diesen »Standard«-Modulen für Win32 wurden und werden
immer noch weitere Module geschrieben, die unter CPAN zur Verfügung gestellt
werden. Wenn Sie viel mit Windows arbeiten und beabsichtigen, verstärkt Perl auf
dieser Plattform zu nutzen, sollten Sie ein Blick in diese Module werfen und sich einen
Überblick über die vielen dahinter verborgenen Möglichkeiten verschaffen. In Tabelle
18.7 finden Sie eine Zusammenfassung der Standard-Win32-Module. Weitere Module
finden Sie im CPAN.
Viele Perl-Elemente sind auch in MacPerl verfügbar, vor allem wenn Sie die MPW (Macintosh Programmer's Workbench) installiert haben. Darüber hinaus bietet MacPerl Schnittstellen zur Macintosh Toolbox, so daß Sie über Perl Zugriff auf die MacOS-Features haben - vorausgesetzt Sie sind bereits ein wenig mit der sehr komplexen Macintosh Toolbox vertraut. Aber auch wenn Sie nicht allzu tief in die Mac-Programmierung mit Perl einsteigen wollen, bietet Ihnen MacPerl diverse, leicht zu erzeugende und einzusetzende Optionen (beispielsweise die Verwendung von Dialogen), mit denen Sie Ihren Skripts eine Mac-typische Benutzeroberfläche verleihen können.
Für Ihre tägliche Arbeit mit MacPerl finden Sie - neben den Tipps aus den häufig
gestellten Fragen zu Standard-Perl - eine Fülle an hilfreichen Informationen in den
»Häufig gestellten Fragen« zu MacPerl unter http://www.perl.com/CPAN/doc/FAQs/
mac/MacPerlFAQ.html. Außerdem gibt es eine Mailing-Liste für Perl-Benutzer und -
Entwickler, die an noch mehr Informationen über MacPerl selbst interessiert sind. In
den FAQs können Sie nachlesen, wie man sich auf die Mailing-Liste setzen läßt.
Ebenso wie ich es für die Windows-Versionen von Perl getan habe, so habe ich mich im ganzen Buch auch bemüht, Sie auf Unterschiede im Verhalten von MacPerl gegenüber Unix-Perl hinzuweisen. Und wie bei Windows, gibt es in der Unix-Version von Perl eine Reihe von Elementen, die nur schwer auf dem Mac nachzuvollziehen sind, besonders in der Einzelrechnerversion von MacPerl. Folgender Kompatibilitätsprobleme sollten Sie sich bewußt sein:
system, exec, schräge
Anführungszeichen), funktionieren nicht in MacPerl. Wenn Sie den MPW
ToolServer installiert haben, lassen sich Elemente wie schräge
Anführungszeichen, Dateinamen-Globbing und die system-Funktion mit Mac-
basierten Befehlen ausführen. Perl kann außerdem AppleScript aufrufen, das
seinerseits externe Programme ausführen kann.
`pwd` oder
`Directory` für das aktuelle Verzeichnis und `stty -raw` und `stty -cooked`
für den Umgang mit reinen Eingaben von der Tastatur.
fork oder Prozesse à la Unix. Mit der
MacToolbox haben Sie Zugriff auf Macintosh-Prozesse über das Mac::Processes-
Modul. Doch dazu bedarf es einiger Kenntnisse der Low-Level-Macintosh-
Prozesse.
%ENV existiert und
enthält standardmäßig einige wenige Basiswerte (wie in den MacPerl Preferences
definiert) sowie Angaben über die Position von MacPerl und seinen Bibliotheken.
:) als Verzeichnistrennzeichen
sowie : und :: als Äquivalent zu . und ...
MacPerl verfügt über eine Reihe von einfachen Subroutinen zum Erzeugen und Verwalten einfacher Dialogfenster von einem Perl-Skript aus. Mit diesen Subroutinen können Sie Dialogfenster mit bis zu drei Schaltflächen, ein Textfeld zur Aufnahme von Eingaben, ein Dialogfenster mit mehreren Optionen oder die Standarddialoge zum Öffnen und Speichern von Dateien erzeugen.
Um ein Dialogfenster mit einer oder mehreren Schaltflächen zu erzeugen, verwenden
Sie MacPerl::Answer mit bis zu vier Argumenten (je nach der Anzahl der
gewünschten Schaltflächen). Das erste Argument ist der Text im Dialogfenster, alle
darauf folgenden Argumente geben die Titel der Schaltflächen an. Maximal sind drei
Schaltflächen erlaubt.
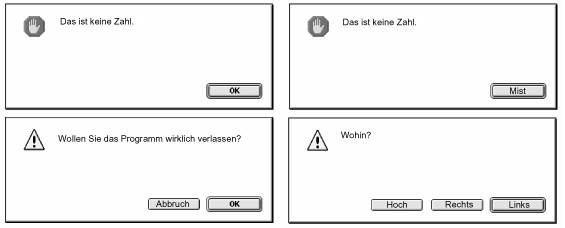
MacPerl::Answer("Das ist keine Zahl."); # Standardschalter (OK)
MacPerl::Answer("Das ist keine Zahl.", "Mist"); # ein Schalter
MacPerl::Answer("Wollen Sie das Programm wirklich verlassen?",
"OK", "Abbruch"); # zwei Schalter
MacPerl::Answer("Wohin?", "Links", "Rechts", "Hoch");
In Abbildung 18.2 sehen Sie, wie die hier beschriebenen vier Dialogfenster aussehen.
Die Rückgabewerte von MacPerl::Answer sind:
Um ein Dialogfenster mit einem Eingabefeld darin zu erzeugen, verwenden Sie
MacPerl::Ask mit einer Eingabeaufforderung:
$age = MacPerl::Ask("Geben Sie bitte Ihr Alter an: ");
Sie können für das Eingabefeld auch einen Wert vorgeben:
$url = MacPerl::Ask("Anzuwählender URL: ", "http://");
MacPerl::Ask liefert den vom Benutzer eingegebenen Wert zurück oder undef, wenn
der Dialog ohne Eingabe abgebrochen wurde. Abbildung 18.3 zeigt ein Beispiel:
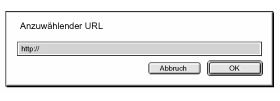
Abbildung 18.3: Eingabefelder in MacPerl
Wollen Sie Ihrem Benutzer mehrere Optionen zur Auswahl anbieten? Dann
verwenden Sie MacPerl::Pick mit einer Eingabeaufforderung und einer Liste der
Optionen:
$food = MacPerl::Pick("Was möchten Sie essen: ",
"Pad Thai", "Burrito", "Pizza");
MacPerl::Pick liefert als Wert die gewählte Option zurück oder undef, wenn der
Dialog abgebrochen wurde. In Abbildung 18.4 sehen Sie dieses Dialogfenster:
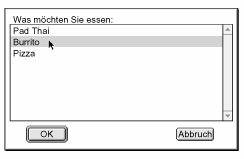
Abbildung 18.4: Dialogfelder mit Optionen in MacPerl
Wenn Sie die Standarddateidialoge nutzen wollen (die Dialogfenster, in denen Sie eine
Datei aus dem Mac-Dateisystem auswählen können), sollten Sie die Datei
StandardFile.pl in Ihre Skripts aufnehmen. Diese Datei stellt Ihnen eine einfach zu
verwendende Schnittstelle zu der Subroutine MacPerl::Choose zur Verfügung.
Verwenden Sie require zur Einbindung des StandardFile-Codes:
require 'StandardFile.pl:
Mit dieser Datei erhalten Sie Zugriff auf die folgenden vier Subroutinen:
StandardFile::GetFile, um den Pfad für eine existierende Datei auszuwählen
StandardFile::GetNewFile und StandardFile::PutFile, um den Pfad und den
Dateinamen einer neuen Datei zu erhalten
StandardFile::GetNewFolder, um den Pfad zu einem Ordner zu erhalten
Die Subroutine GetFile übernimmt drei Argumente: eine Eingabeaufforderung, eine
Liste von Dateitypen, die herausgefiltert werden sollen (verwenden Sie für Textdateien
beispielsweise 'TEXT', 'ttxt', 'ttro') und einen Standarddateinamen. Die
Eingabeaufforderung und der Standarddateiname sind optional (die
Eingabeaufforderung wird in aktuellen MacPerl-Versionen überhaupt nicht angezeigt):
$filename = &StandardFile::GetFile("Wählen Sie eine Datei aus",
'TEXT','ttxt','ttro', "eingabe");
GetNewFile, PutFile und GetNewFolder erwarten zwei Argumente: eine
Eingabeaufforderung und einen Standarddateinamen. Wie bei GetFile wird die
Eingabeaufforderung derzeit ignoriert, ist jedoch als Argument obligatorisch. Der
Standarddateiname ist optional:
$filename = &StandardFile::PutFile("Wählen Sie eine Protokolldatei aus",
"LOG_Datei");
All diese Subroutinen liefern den vollen Macintosh-Pfadnamen für die ausgewählte
Datei, und zwar mit »:« zwischen den Ordnernamen (zum Beispiel Hard
Disk:MyPerlApp:Stored Files:logdatei.txt). Anschließend müssen Sie die E/A-
Routinen von Perl verwenden, um die Datei zu lesen oder in die Datei zu schreiben.
Beachten Sie, daß es allgemein erwartet wird, daß Sie zum Lesen einer Datei die
Subroutine GetFile verwenden, während die Subroutinen GetNewFile und PutFile
sich eher zum Auswählen von Dateien für die Ausgabe anbieten. Durch die Wahl des
falschen Dialogfensters könnten Sie Ihre Benutzer verwirren, die bestimmte
Erwartungen bezüglich des Ablaufs hegen.
Auf der Begleit-CD zu diesem Buch (wie auch unter
www.typerl.com) finden Sie ein Perl-Skript, das Beispiele für alle diese Dialogfenster erzeugt. Es heißtmacperldialoge.pl.
Erfahrenen Mac-Programmierern stellt MacPerl eine Reihe von Schnittstellen zu verschiedenen Teilen des Mac-Betriebssystems zur Verfügung. Dazu gehören unter anderem:
In den MacPerl-Hilfedateien finden Sie Informationen hierzu. Vergessen Sie auch nicht das CPAN, das einige Mac-spezifische Module enthält, und die bereits erwähnten häufig gestellten Fragen (FAQs), die Hilfestellung bei vielen allgemeinen Problemen mit MacPerl bieten.
Ganze Bücher sind darüber geschrieben worden, wie man die verschiedenen plattformspezifischen Aspekte von Perl nutzt (oder vermeidet). Um dieses Kapitel so klein wie möglich zu halten, habe ich etliche Elemente ausgelassen. Einige dieser Elemente, von denen ich annehme, daß Sie sich mit ihnen nach Lektüre dieses Buches noch eingehender beschäftigen möchten, werde ich in diesem Abschnitt kurz vorstellen.
Das wahrscheinlich wichtigste Element, das ich von der Besprechung ausgespart habe, sind die Pipes. Eine Pipe ist eine Art Kanal, aus dem Sie Daten auslesen und an den Sie Daten senden können. Die Pipe kann mit der Standardeingabe und -ausgabe Ihres Skripts und einem anderen Programm verbunden werden. Sie kann aber auch mit einem Gerät wie einem Drucker oder einer Netzwerkverbindung wie einem Socket verbunden werden.
Unter Unix können Sie eine Pipe wie ein Datei-Handle öffnen, und genauso können Sie auch daraus lesen oder dorthin schreiben. Eine Pipe kann eine Verbindung zu einem anderen Programm oder zu einem anderen Prozeß, der das gleiche Programm ausführt, herstellen. Sie können auch benannte Pipes verwenden, die auf Ihrem System existieren. Die perlipc-Manpage enthält weitere Informationen zur Verwendung von Pipes.
Unter Windows können Sie mit open - wie unter Unix - reguläre Pipes zu anderen
Prozessen, die auf dem System ausgeführt werden, herstellen. Für benannte Pipes
bedienen Sie sich des Moduls Win32::Pipe aus dem CPAN.
Mac-Anwender, die den ToolServer installiert haben, können eine eingeschränkte Version der Pipes verwenden.
Signale sind ein Unix-Konzept, mit dem man verschiedene Fehler und Meldungen
abfangen und einer ordnungsgemäßen Behandlung zuführen kann. Der Hash %SIG
enthält Referenzen auf verschiedene Signal-Bearbeitungsroutinen. Signale
funktionieren nur unter Unix. Weitere Informationen finden Sie in der perlipc-
Manpage.
Die Unix-Version von Perl verfügt über eine Reihe von vordefinierten Funktionen zur Bearbeitung von Low-Level-Netzwerk-Befehlen und -Sockets. Die meisten dieser Funktionen finden auf anderen Plattformen keine Unterstützung, sondern sind vielmehr ersetzt durch diverse plattformspezifische Netzwerk-Module. Wenn Sie ein wahrer Netzwerk-Fan sind, dann möchte ich Ihnen die perlipc-Manpage ans Herz legen. Dort finden Sie einen wahren Schatz an Informationen zu Sockets und Netzwerkprogrammierung.
Wenn Sie aber lediglich, sagen wir, eine Webseite vom Internet herunterladen wollen, gibt es Module dafür, die Ihnen diese Arbeit abnehmen, ohne daß Sie irgend etwas über TCP wissen müssen. Darauf werde ich in Kapitel 20 noch näher eingehen.
Eine grafische Benutzerschnittstelle (GUI) in Perl zu erzeugen, ist nicht leicht und trägt nicht gerade zur Plattformunabhängigkeit bei. Aber es ist möglich.
Einer der besten Wege zur Erzeugung von GUIs in Perl führt über das Tk-Paket. Tk ist
ein einfacher Weg zum Erzeugen und Verwalten von Benutzerschnittstellen-Fenstern,
ursprünglich verbunden mit der TCL-Sprache, jetzt aber auch für Perl verfügbar. Tk
gibt es für Unix und Windows in jeweils plattformspezifischer Ausführung. Zu Perl/Tk
gibt es eine Datei mit häufig gestellten Fragen unter http://w4.lns.cornell.edu/
~pvhp/ptk/ptkTOC.html.
Das Modul Win32::OLE ermöglicht es Ihnen, Schnittstellen in Visual Basic zu erstellen
und sie dann via OLE-Automation zu steuern. Siehe dazu Win32::OLE.
Auf dem Mac steht Ihnen so ziemlich alles, was Sie für die Erstellung von Mac- Schnittstellen unter Perl benötigen, zur Verfügung. Voraussetzung ist aber, daß Sie wissen, wie man die zur Verfügung stehenden Möglichkeiten nutzt, und das bedeutet, daß Sie zumindest rudimentäre Kenntnisse der mehr als zehn Bände von »Inside Macintosh« haben sollten.
Eines Tages wird Perl eine plattformunabhängige Sprache aus einem Guß sein, in der Sie Skripts schreiben können, die jede beliebige Aufgabe meistern und die sich auf jeder Plattform ausführen lassen, für die es eine Perl-Umgebung gibt. Aber noch ist es nicht soweit. Und manche mögen der Meinung sein, daß das Ziel einer absoluten plattformübergreifenden Kompatibilität gar nicht so erstrebenswert ist, in Anbetracht all der Unterschiede zwischen den Plattformen und all der coolen plattformspezifischen Dinge, die man machen kann.
Heute haben wir aufgehört, Perl als eine Sprache zu betrachten, die auf allen Plattformen die gleiche ist, sondern ein paar der plattformspezifischen Unterschiede untersucht: die Umgebungsvariablen, das Ausführen von Programmen, das Starten von Prozessen unter Unix und Windows, die Arbeit mit der Windows- Registrierdatenbank sowie das Erzeugen von Dialogfenstern und Eingabeaufforderungen unter MacPerl.
Frage:
Ich habe ein Skript, das mit Hilfe des Befehls system mehrere Programme aufruft.
Ich möchte dieses Skript über einen Unix-cron-Job ausführen. Wenn ich es über
die Befehlszeile ausführe, gibt es keine Probleme, aber sobald ich es installiert
habe, erhalte ich Fehlermeldungen, daß dieser und jener Befehl nicht gefunden
werden kann. Was habe ich falsch gemacht?
Antwort:
Wahrscheinlich ein Problem des Ausführungspfades. Denken Sie daran, daß
jedes Perl-Skript seinen Ausführungspfad (das heißt die Umgebungsvariable
PATH) von der Shell oder der Benutzer-ID, die gerade das Skript ausführt,
erbt. Wenn ein Skript von einem anderen Prozeß ausgeführt werden soll -
zum Beispiel einem CGI-Skript oder einem cron-Job -, erhält es einen
anderen Ausführungspfad. In diesem Fall hat die cron-Benutzer-ID
wahrscheinlich einen sehr eingeschränkten Ausführungspfad, und die system-
Funktion findet das von ihr benötigte Programm nicht. Um dieses Problem zu
vermeiden, können Sie für alle ausführbaren Programme, die von system
aufgerufen werden, immer volle Pfadnamen angeben oder aber die PATH-
Variable auf dem Weg über den %ENV-Hash selbst innerhalb des Perl-Skripts
setzen.
Frage:
Ich habe ein Skript, das mit fork in mehrere Prozesse verzweigt. Ich habe eine
einzige globale Variable und möchte diese Variable global in allen Kindprozessen
inkrementieren. Leider funktioniert das nicht. Warum?
Antwort:
Alle Prozesse, die mit fork erzeugt werden, sind völlig unabhängig von den
anderen Prozessen. Dazu gehören auch alle Variablen, die von dem
Elternprozess definiert wurden. Der Kindprozeß erhält eine Kopie all dieser
Variablen und hat keinen Zugriff auf diejenigen des Elternprozesses. Um
zwischen den Prozessen zu kommunizieren, müssen Sie einen speziellen IPC-
Mechanismus (IPC steht für »Interprocess Communication«) einrichten. Im
Vertiefungsabschnitt finden Sie ein paar Hinweise in Richtung Interprozeß-
Kommunikation.
Frage:
Wenn ich in Kindprozesse verzweige, wird die Ausgabe der Kindprozesse mit der
Ausgabe des Elternprozesses vermischt. Wie kann ich die Ausgaben trennen?
Antwort:
Das ist nicht möglich. Es gibt nur eine Standardausgabe, und diese Ausgabe
wird zwischen allen Kindprozessen geteilt. Wenn Sie wirklich die Ausgaben
der einzelnen Prozesse trennen müssen, könnten Sie beispielsweise die
Ausgabe der Prozesse in unterschiedliche temporäre Dateien ablegen und
dann diese Dateien nacheinander ausgeben.
Frage:
Ich habe ein Perl-Skript, das unter Unix geschrieben wurde. Durch das ganze
Skript hindurch werden die Funktion system und das Unix-Programm sendmail
verwendet. Wie kann ich dieses Programm so anpassen, daß es andere Systeme
berücksichtigt?
Antwort:
Post zu senden ist unter Unix sehr bequem. Sie müssen nur das Mail-
Programm aufrufen und die Meldung fortschicken. Leider ist das auf anderen
Plattformen nicht ganz so einfach. Wenn Sie unter Windows arbeiten, finden
Sie in den häufig gestellten Fragen zu Perl für Win32 eine Liste der
Alternativen zum Versenden von Post. Auch das CPAN-Paket Net::SMTP kann
bei der Implementierung plattformunabhängiger Mail-Operationen helfen.
Frage:
Ich möchte herausfinden, auf welcher Plattform ich mich befinde, so daß ich
sicher bin, daß mein Skript nur auf einer Plattform ausgeführt wird.
Antwort:
Hier kann Ihnen das Modul Config helfen. Der Schlüssel 'osname' aus dem
Hash %Config enthält die Plattform, auf der Sie sich befinden. Um
beispielsweise sicherzustellen, daß Sie unter Windows arbeiten, könnten Sie
folgenden Code verwenden:
use Config;
if ( $Config{'osname'} !~ /Win/i ) {
die "Vorsicht! Dieses Skript läuft nur unter Windows. Sie können es nicht von hier ausführen.\n";}
Der Workshop enthält Quizfragen, die Ihnen helfen sollen, Ihr Wissen zu festigen, und Übungen, die Sie anregen sollen, das eben Gelernte umzusetzen und eigene Erfahrungen zu sammeln. Versuchen Sie, das Quiz und die Übungen zu beantworten und zu verstehen, bevor Sie zur Lektion des nächsten Tages übergehen.
%ENV verwendet? Warum ist es nützlich?
system und den schrägen Anführungszeichen?
fork?
system und exec?
Win32::Process im Austausch mit fork verwenden?
fork die gleiche Zahl Kindprozesse, und stellen Sie sicher, daß der
Elternprozeß wartet, bis alle Kindprozesse beendet sind. Jeder Prozeß sollte
img.pl aus Kapitel 10, »Erweiterte
Möglichkeiten regulärer Ausdrücke« (das Skript, das Informationen über die
Grafiken in einer HTML-Datei ausgab), so daß die Ausgabe Ihnen per E-Mail
zugesandt und nicht auf dem Bildschirm ausgegeben wird. HINWEIS: Mit dem
folgenden Befehl können Sie eine Nachricht senden:
mail ihremail@ihresite.com < textderNachricht
dir) und nur die Dateinamen, einen Namen pro Zeile, ausgibt (Sie
müssen die Namen nicht sortieren).
Hier die Antworten auf die Workshop-Fragen aus dem vorigen Abschnitt.
%ENV enthält die Variablennamen und -werte aus der Umgebung des
Skripts. Unter Unix und Windows können die Werte in dem Hash nützlich sein,
um Informationen über die Systemumgebung einzuholen (oder zu ändern und an
andere Prozesse zu übergeben). Auf dem Mac erfüllt %ENV keinen besonderen
Zweck.
system führt ein anderes Programm oder Skript von innerhalb Ihres
Perl-Skripts aus und sendet die Ausgabe an die Standardausgabe. Schräge
Anführungszeichen führen ebenfalls externe Programme aus, fangen aber die
Eingabe in einem Skalar oder in einer Liste ab (je nach Kontext).
fork-Funktion erzeugt einen neuen Prozeß, einen Klon des Originalprozesses.
Beide Prozesse führen das Skript von dem Punkt, an dem fork auftrat, weiter aus.
system und exec sind eng miteinander verwandt. Beide dienen dazu, ein externes
Programm auszuführen. Der Unterschied besteht darin, dass system zuerst die
fork-Funktion ausführt, während exec die Ausführung des aktuellen Skripts im
aktuellen Prozeß unterbricht und statt dessen das externe Programm ausführt.
Win32::Process und fork sind nicht austauschbar. Die fork-Funktion ist eng an
die Unix-Vorstellung von einem Prozeß gekoppelt; Win32::Process entspricht
eher einem fork, auf das direkt ein exec folgt.
#!/usr/bin/perl -w
use strict;
if (@ARGV > 1) {
die "Bitte nur ein Argument.\n";
}
elsif ($ARGV[0] !~ /^\d+/) {
die "Nur Zahlen als Argument zugelassen.\n";
}
my $pid;
my $procs = pop;
foreach my $i (1..$procs) {
if (defined($pid = fork)) {
if ($pid) { #Eltern
print "Eltern: Kind $i gestartet\n";
} else { #Kind
srand;
my $top = int(rand 100000);
my $sum;
for (1..$top) {
$sum += $_;
}
print "Kind $i beendet: Summe der ersten $top Zahlen: $sum\n";
exit;
}
}
}
while ($procs > 0) {
wait;
$procs--;
}
my $tmp = "tempfile.$$"; # temporäre Datei;
open(TMP, ">$tmp") ||
die "Temporäre Datei $tmp kann nicht geöffnet werden\n";
print-Anweisungen in diese Datei schreiben:
if (exists($atts{$key})) {
$atts{$key} =~ s/[\s]*\n/ /g;
print TMP " $key: $atts{$key}\n";
}
use, um die temporäre Datei zu versenden und zu
entfernen:
my $me = "ihreEmail@ihreSite.com";
system("mail $me <$tmp");
unlink $tmp
substr-Funktion mit dem Zeichen
44, wenn Sie mit Windows 95 arbeiten):
#!/usr/bin/perl -w
use strict;
my @list = `dir`;
foreach (@list) {
if (/^\w/) {
print substr($_,39);
}
}
#!/usr/bin/perl -w
use strict;
require 'StandardFile.pl';
my $file = &StandardFile::GetFile("Wählen Sie eine Datei",
'TEXT','ttxt','ttro', "input");
open(FILE, "$file") || die "Datei $file kann nicht geöffnet werden\n";
while (<FILE>) { print };