




Ebenso wie die ersten beiden Wochen dieses Buches werden wir auch die dritte Woche mit einem Beispielkapitel abschließen. Die beiden Beispielskripts, die ich in diesem Kapitel besprechen werde, decken so ziemlich alle Aspekte von Perl ab, die Sie in den letzten 20 Tagen kennengelernt haben. Nachdem Sie diese beiden Beispielskripts durchgearbeitet und verstanden haben, sollten Sie in der Lage sein, Ihren eigenen Weg mit Perl zu gehen.
Heute untersuchen wir zwei Beispiele, beides CGI-Skripts:
Beide Beispiele sind länger als die bisherigen, das letzte sogar mehr als doppelt so
lang. Zur Erinnerung: Alle Beispiele dieses Buches sind auch auf der Buch-CD und
online auf der »Sams Teach Yourself Perl«-Website unter http://www.typerl.com/
verfügbar. Damit Sie nicht meinen, Sie müßten 350 Zeilen Code von Hand abtippen.
Nutzen Sie dieses Kapitel, um den Code sorgfältig zu studieren, und wenn Sie dann
noch weiter damit experimentieren wollen, kopieren Sie das Skript von der CD oder
aus dem Internet.
Beide Beispiele werden als CGI-Skripts ausgeführt. Wie schon bei den CGI-Skripts,
die wir in Kapitel 16, »Perl für CGI-Skripts«, untersucht haben, sind die Installation
und die Anwendung dieser Skripts von Plattform zu Plattform und von Webserver zu
Webserver unterschiedlich. Einige Server verlangen, dass die Skripts in einem
speziellen Verzeichnis (cgi-bin) installiert werden, dass die Dateinamen der Skripts
besondere Extensionen (.cgi statt .pl) haben oder dass spezielle Zugriffsrechte
gesetzt werden. Unter Umständen müssen Sie auch die Zugriffsrechte für die
Konfigurations- und Datendateien der Skripts setzen. Weitere Informationen zum
Installieren und Verwenden von CGI-Skripts finden Sie in der Dokumentation zu
Ihrem Webserver, oder wenden Sie sich an Ihren Systemverwalter.
Viele Websites verfügen heutzutage über Eintrittsseiten, deren Inhalt Sie anpassen und selbst zusammenstellen können (nach dem Motto »Mein Portal« oder ähnlich), so dass Sie beim Ansteuern dieser Websites schnell die Informationen finden, die Sie interessieren. Diese Seiten sind ein hervorragendes Mittel, um den Inhalt einer Website darzustellen. Ich dachte, es wäre ganz nett, wenn man jetzt noch einen Schritt weiter ginge und sich selbst eine eigene Seite anlegen würde, auf der man die verschiedensten Dinge von mehreren Websites kombinieren könnte - und damit meine ich nicht nur Links zu diesen Seiten, wie eine Textmarken- und Favoritenliste, sondern direkt den Inhalt der Seiten. Börsenkurse von einer Site, Wetterdaten oder Nachrichten von einer anderen, eine Sammlung von Informationen aus den verschiedensten Websites - und das alles auf einer Seite.
Und das ist genau das, was meinehomepage.pl macht. Das Skript nutzt das LWP-
Modul, mit dem es Perl möglich ist, ausgewählte Webseiten von Websites über ein
Netzwerk anzufordern (dies ist eines der Skriptbeispiele, in dem Sie eine ganze Reihe
von Modulen einsetzen, um den Großteil der Arbeit zu erledigen, und ein wenig
eigenen Perl-Code aufsetzen, um diese Module zusammenzubinden). Für jede
Information, die auf der selbstgebauten Seite erscheinen soll, wird der HTML-Code
der betreffenden Webseiten aus dem Internet herangezogen. Der relevante Code wird
extrahiert und daraus die eigene Webseite mit den interessanten Teilen aufgebaut
(plus einige weitere Links, die ich jedoch nicht jeden Tag besuchen möchte). Wie das
Ergebnis von MeineHomepage aussehen kann, zeigt Ihnen Abbildung 21.1. Diese
spezielle Version enthält die wichtigsten Börsendaten, das Wetter und den aktuellen
Dilbert-Cartoon von United Media (Dilbert ist leider nicht zu sehen, da nicht genug
Raum vorhanden ist und es außerdem Probleme mit dem Copyright gäbe; doch
glauben Sie mir, er ist vorhanden.)
Ich hätte das Skript so schreiben können, dass ich alle Websites und deren Verarbeitung hart-kodiert hätte - man nehme eine Seite für Börsenkurse, extrahiere die Daten, schreibe den HTML-Code und wiederhole das gleich für das Wetter und den Comic-Strip. Und wenn ich mehr Daten aufnehmen oder weitere Links oder neue Inhalte einfügen wollte, müßte ich das Skript selbst modifizieren (siehe Abbildung 21.1).
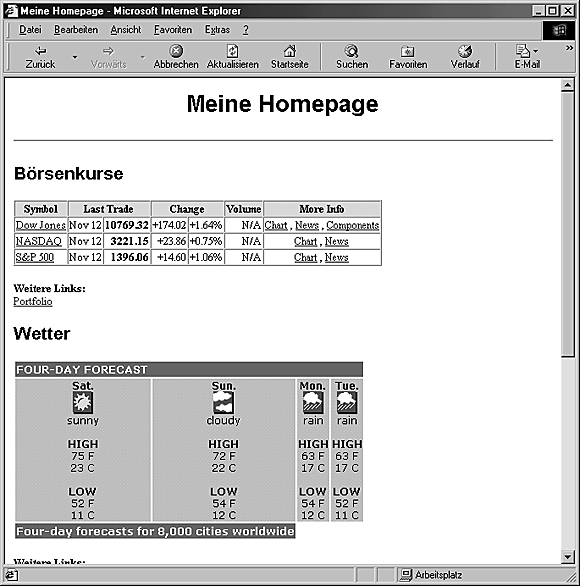
Abbildung 21.1: Meine Homepage, Endergebnis
Auf den ersten Blick mag das zwar praktisch erscheinen, aber letztlich ist es sinnvoller, die Daten - das heißt, das was auf der Homepage erscheinen soll - von dem Skript, das alles herunterlädt und verarbeitet, zu trennen. Deshalb besteht dieses Skript auch aus zwei Teilen: einer Konfigurationsdatei und einem Perl-Skript, das die Daten aus der Konfigurationsdatei einliest und verarbeitet.
Die Konfigurationsdatei entspricht dem Adreßbuch aus Kapitel 14: Es ist eine Datei
mit mehreren »Datensätzen«, die jeweils durch drei Bindestriche getrennt sind (---).
Jeder Datensatz entspricht einem Abschnitt der Homepage und enthält vier Felder:
Listing 21.1 zeigt einen Mustereintrag aus meiner config-Datei.
Listing 21.1: Meine Homepage-Konfigurationsdatei (Muster)
title=Dilbert
url=http://www.unitedmedia.com/comics/dilbert/
code={
if ($content =~ /src=\"(.*dilbert\d+.gif)\"/i) {
print "<P><IMG SRC=\"";
print url($1,$data{'url'})->abs->as_string, "\">\n";
}
}
other=( 'United Media Comics' => 'http://www.unitedmedia.com/comics/',
'San Jose Mercury news Comics' =>
'http://comics.mercurycenter.com/comics/',
'Tom Tommorow (mondays only)' =>
'http://www.salonmagazine.com/comics/tomo/',
)
---
Das Skript zu Meine Homepage ist ein CGI-Skript, das Sie wie jedes andere CGI-
Skript installieren müssen. Im Gegensatz zu den in Kapitel 14 betrachteten CGI-
Skripts gibt es zu diesem Skript kein Formular, durch das es aufgerufen wird, und es
müssen auch keine Formularparameter verarbeitet werden. Das Skript wird direkt wie
ein URL (http://www.ihresite.com/cgi-bin/meinehomepage.pl oder so ähnlich)
aufgerufen und liest dann die Konfigurationsdatei ein und verarbeitet sie (installieren
Sie die Konfigurationsdatei dort, wo das Skript sie finden kann). Der Rückgabewert ist
der für die Homepage generierte HTML-Code.
Kommen wir jetzt zum Perl-Teil. Gehen Sie den Code in Listing 21.2 einfach mal nur
durch, und versuchen Sie einen Gesamteindruck von dem Ablauf des Skripts zu
bekommen. Achten Sie dabei besonders auf die Subroutine &procsection(), denn
hier fängt es an, interessant zu werden.
Listing 21.2: Der Code für meinehomepage.pl
1: #!/usr/bin/perl -w
2: use strict;
3: use LWP::Simple;
4: use URI::URL;
5: use CGI qw(header start_html end_html);
6:
7: my $config = 'config';
8:
9: print header;
10: print start_html('Meine Homepage');
11: print "<H1 ALIGN=CENTER><FONT FACE=\"Helvetica,Arial\" SIZE+2>";
12: print "Meine Homepage</FONT></H1>\n";
13: print "<HR>\n";
14:
15: open(CONFIG, $config) or &quitnow();
16:
17: while () {
18: my %rec = &readrec();
19:
20: if (%rec) {
21: &procsection(%rec);
22: } else { last; }
23: }
24:
25: print end_html;
26:
27: sub readrec {
28: my %curr = ();
29: my $key = '';
30: my $val = '';
31:
32: while (<CONFIG>) {
33: chomp;
34: if ($_ ne '---' and $_ ne '') { # Trennsymbol für Datensätze
35: if ($_ =~ /^\#/) { next;} # Kommentare
36:
37: ($key, $val) = split(/=/,$_,2);
38:
39: # mehrzeilige Einträge verarbeiten
40: if ($key eq 'code' or $key eq 'other' ) {
41: my $in = '';
42: while () {
43: ($in = <CONFIG>);
44: $val .= $in;
45: if ($in =~ /^[})]/) { last; }
46: }
47: }
48:
49: $curr{$key} = $val;
50: }
51: else { last; }
52: }
53: return %curr;
54: }
55:
56: sub procsection {
57: my %data = @_;
58:
59: print "<H2><FONT FACE=\"Helvetica,Arial\">";
60: print "$data{'title'}</FONT></H2>\n";
61:
62: my $content = get($data{'url'});
63: if (defined $content) {
64: eval $data{'code'};
65: } else {
66: print "<P><B>Hoppla!</B> Kann nicht auf die Daten zugreifen\n ";
67: exit;
68: }
69:
70: if (defined $data{'other'}) {
71: my %others = eval $data{'other'};
72:
73: print "<P><B>Weitere Links:</B> <BR>\n";
74: foreach (keys %others) {
75: print "<A HREF=\"$others{$_}\">$_</A><BR> ";
76: }
77: print "\n";
78: }
79:
80: }
81:
82: sub quitnow {
83: print "<H2>Hoppla! Fehler:</H2><P><TT> Konfigurationsdatei konnte nicht geöffnet werden: $!</TT>\n";
84: print "<P>Überprüfen Sie Ihre Installation oder kontaktieren ";
85: print "Sie Ihren Systemadministrator\n";
86: print end_html;
87: die "Konfigurationsdatei konnte nicht geöffnet werden: $!\n";
88: }
Das Skript meinehomepage.pl geht in vier Schritten vor:
Das Skript wiederholt diese Schritte für jeden Eintrag in der Konfigurationsdatei.
Das meiste in diesem Skript sollte Ihnen bekannt vorkommen. Um ehrlich zu sein, ich
habe das Skript adressen.pl aus Kapitel 14 als Grundlage für dieses Skript
genommen, da sich die Konfigurationsdateien ähneln. Was Ihnen fremd erscheinen
dürfte, ist die Verwendung der zwei Module LWP::Simple und URI::URL (und die damit
verbundenen Subroutinen: get, url, abs und as_string) sowie die Verwendung der
Funktion eval, um den Code der Konfigurationsdatei in den Rumpf des Skripts zu
holen.
Wenn man sich nicht sicher ist, wie eine bestimmte Aufgabe zu lösen ist, verwendet
man einfach den Code von anderen Programmierern. Oder noch besser: Anstatt viel
Zeit damit zu verschwenden, Skripts für komplizierte Aufgaben zu schreiben (zum
Beispiel Netzwerkcode zu schreiben, um eine Datei von einer Website anzufordern),
schauen Sie erst einmal im CPAN nach. In diesem Fall waren die LWP-Module
(Bibliothek für WWW-Zugriff in Perl) genau das, was ich benötigte. Da ich gerade im
CPAN war, habe ich gleich das gesamte libwww-Paket heruntergeladen, das alle Arten
von Modulen für die Handhabung von Webseiten und Webdaten enthält.
Um dieses Skript auszuführen, müssen Sie diese Dateien vom CPAN herunterladen
(siehe www.perl.com für weitere Details) und dort auf ihrem System installieren, wo
Sie das Skript ausführen. Lesen Sie im Kapitel 13, »Gültigkeitsbereiche, Module und
das Installieren von Code«, nach, wie man Module in Perl installiert und verwendet,
wenn Sie sich nicht mehr genau erinnern können, wie dies geht.

Die Bibliothek
libwwwallein wird Ihnen nicht ausreichen. Darüber hinaus gibt es noch eine ganze Reihe von weiteren Modulen, die Sie installieren müssen, einschließlichlibnet,HTML-Parserund einige andere. All die Module, die wiederum von anderen Modulen benötigt werden, zu installieren, kann einem manchmal endlos vorkommen (Modul A benötigt Modul B, das wiederum Modul C benötigt und so weiter). Sie sollten sich aber die Zeit dafür nehmen, denn diese Module sind wichtig und sehr nützlich. Die README-Datei zu der Bibliotheklibwwwteilt Ihnen genau mit, welche Module Sie herunterladen und installieren müssen.
Das LWP-Paket enthält eine Reihe von Modulen für den Umgang mit dem Web und
seinen Webseiten. Die meisten dieser Module sind objektorientiert und bieten eine
große Bandbreite an Möglichkeiten. Wenn Sie interessiert sind, empfehle ich Ihnen,
die POD-Dokumentation zu diesen Modulen zu lesen. Für unser spezielles Skript
benötigen wir allerdings nur eine einfache Lösung, um eine Webseite von einem
Webserver in das Skript zu holen, und dafür reicht das Modul LWP::Simple fraglos
aus.
LWP::Simple ist, wie der Name schon verrät, ein simpler Satz an Subroutinen zur
Bewältigung einfacher Aufgaben. Aus diesem Satz haben wir die Subroutine get
gewählt, die bei Übergabe eines URL als Argument die zugehörige Website über das
Internet ansteuert, die Datei hinter dem URL abruft und als einen großen String
zurückliefert. In Zeile 62 des Skripts meinehomepage.pl wird die Funktion wie folgt
aufgerufen:
my $content = get($data{'url'});
Diese Zeile ist schnell erklärt: Der Hash %data enthält den Datensatz für diesen
Abschnitt der Homepage, wobei der URL in dem URL-Schlüssel gespeichert ist. Den
URL übergeben wir als Argument an die Subroutine get und speichern das Ergebnis
in der Skalarvariable $content. Weiter hinten, im Abschnitt über eval, zeige ich
Ihnen, wie Sie die wichtigen Teile aus dem Inhalt von $content herausziehen.
Das andere Modul, das wir in diesem Skript verwenden, lautet URI::URL. URI leitet
sich von Uniform Resource Identifier ab und ist eine Art generische Version von
URL (Uniform Resource Locator). Das URL-Modul ist ebenfalls objektorientiert und
bietet verschiedene Möglichkeiten, um URLs aller Art zu erzeugen, zu ändern oder zu
analysieren. Wir benötigen es in den Code-Abschnitten der config-Datei. Lassen Sie
uns eine Zeile aus der config-Datei betrachten, die ich Ihnen oben bereits vorgestellt
habe:
print url($1,$data{'url'})->abs->as_string, "\">\n";
Dieses kleine Codefragment verwendet drei Subroutinen (eigentlich Methoden, wenn
wir uns in Erinnerung zurückrufen, dass dies ein objektorientiertes Modul ist): url, abs
und as_string. Durch die Zusammenarbeit dieser drei Methoden, kann man einen
relativen URL - wie Sie ihn in Webseiten vorfinden, die Sie gerade aus ihrem Home-
Verzeichnis ihres Webservers herausgelöst haben - in einen vollständigen, absoluten
URL konvertieren. Mit diesem Code stellen wir sicher, dass alle Links in dem Code
unserer Homepage auch tatsächlich auf die korrekten Websites verweisen. Wenn Sie
an weiteren Informationen zu diesem Thema interessiert sind, lesen Sie die POD-
Dokumentation zu der URI::URL-Manpage.
Um ehrlich zu sein: Ich habe diesen Code einem großartigen Dokument, dem
LWPcookbook, entnommen, das mit demLWP-Modul erhältlich ist. Es enthält eine Fülle von Beispielen für die Lösung von häufigen Aufgaben mitLWP. Wenn Sie dieses Skript ausbauen oder einfach nur mehr mit dem Web und Perl arbeiten wollen, konsultieren Sie erst einmal dieses Kochbuch. Vielleicht finden Sie dort ja eine Lösung zu Ihrem Problem.
Hier kommt die Quizfrage: Wie kann man generischen Code aufsetzen, der wichtige Daten aus einer HTML-Datei extrahiert, wenn sich die wichtigen Teile von Datei zu Datei unterscheiden. Die Antwort lautet: Es geht nicht generisch, aber halten Sie den Code vom Hauptskript getrennt. In meinehomepage.pl finden Sie keinen Code zum Extrahieren der uns interessierenden Teile einer HTML-Datei. Dieser Code - normalerweise eine ganze Reihe von regulären Ausdrücken - befindet sich in der Konfigurationsdatei, zusammen mit den Titeln und den URLs, und unterscheidet sich je nach Seite.
Und nun die nächste Frage: Wie bekommen Sie den Code in Ihr Skript? Der erste
Schritt besteht einfach darin, den Code aus der Konfigurationsdatei auszulesen. Der
Teil des Skripts, der die Konfigurationsdatei einliest, legt den ganzen Codeabschnitt
als ein einziges Element in einem Hash mit dem Schlüssel 'code' ab.
Das letzte Teil in unserem Puzzle ist die eval-Funktion. Diese Funktion übernimmt,
wie ich gestern erklärt habe, einen String und führt diesen String aus, als handele es
sich um Perl-Code. In diesem Fall besteht unser String aus Perl-Code, so dass eval
gleichbedeutend mit Kopieren und Einfügen an dieser Stelle ist. Der Code, der mit
eval ausgeführt wird, hat Zugriff auf alle Variablen, die im Vorfeld definiert wurden,
so dass wir den Hash %data und den String $content dazu nutzen können, den
HTML-Code zu verarbeiten und auszugeben.
Sehen Sie hier noch einmal das Beispiel aus der config-Datei. Es extrahiert den URL
der Comic-Strip-Grafik (bestehend aus dem Namen dilbert, einer Reihe von Zahlen
und der Extension .gif) und erzeugt ein neues IMG-Tag in unserer Homepage (wobei
der URL zu seinem absoluten Namen expandiert wird).
code={
if ($content =~ /src=\"(.*dilbert\d+.gif)\"/i) {
print "<P><IMG SRC=\"";
print url($1,$data{'url'})->abs->as_string, "\">\n";
}
}
Der HTML-Code, der durch dieses bißchen Code erzeugt wird, sieht ungefähr folgendermaßen aus:
<P><IMG SRC="http://www.unitedmedia.com/comics/dilbert/archive/images/
dilbert973012490104.gif">
Die eval-Funktion wird auch für den 'other'-Teil der config-Datei benötigt, der
einen Hash mit den zusätzlichen Links enthält. Ich hätte diese Schlüssel und URLs
auch anders formatieren und in einem Hash des Skripts verarbeiten können, aber so
war es einfacher. Die Zeilen 70 bis 78 in dem Skript meinehomepage.pl zeigen, wie
die anderen Links ausgewertet und auf der HTML-Seite angezeigt werden.
Die Musterkonfigurationsdatei war ziemlich einfach. Deshalb möchte ich noch eine
weitere, etwas komplexere besprechen, allerdings vom Standpunkt des Skript
meinehomepage.pl aus. Konzentrieren wir uns auf die Subroutine procsection aus
meinehomepage.pl, wie sie in Listing 21.3 wiedergegeben wird:
Listing 21.3: Die Subroutine procsection
1: sub procsection {
2: my %data = @_;
3:
4: print "<H2><FONT FACE=\"Helvetica,Arial\">";
5: print "$data{'title'}</FONT></H2>\n";
6:
7: my $content = get($data{'url'});
8: if (defined $content) {
9: eval $data{'code'};
10: } else {
11: print "<P><B> Hoppla!</B> Kann nicht auf die Daten zugreifen \n";
12: exit;
13: }
14:
15: if (defined $data{'other'}) {
16: my %others = eval $data{'other'};
17:
18: print "<P><B>Weitere Links:</B> <BR>\n";
19: foreach (keys %others) {
20: print "<A HREF=\"$others{$_}\">$_</A><BR> ";
21: }
22: print "\n";
23: }
24: }
Beginnen wir oben, wo wir das Datensatz-Hash-Argument in einer lokalen Variablen speichern und den obersten Teil des Abschnitts ausgeben (indem wir von dem Titel- Teil aus der Konfigurationsdatei in Zeile 5 Gebrauch machen).
In Zeile 7 wird mit Hilfe der LWP-Subroutine get die HTML-Datei angefordert. Im
Erfolgsfall (Zeile 9) werten wir den Codeabschnitt der Konfigurationsdatei aus. Im
anderen Fall geben wir einen Fehler aus und gehen zum nächsten Abschnitt über.
Lassen Sie uns einen Blick auf den Code aus der Konfigurationsdatei werfen (Listing 21.4). Dieser Code beschreibt den Wetterteil der Seite und zeichnet eine ganze Reihe von Tabellenzellen in die Mitte der Seite.
Listing 21.4: Konfigurationscode für den Wetterabschnitt
1: {
2: my $table = "<table>\n";
3: while ($content =~ /(<tr.*?<\/tr>)/gis) {
4: my $row = $1;
5: if ($row =~ /FOUR-DAY/is) { # Überschriftenzeile
6: $table .= $row;
7: }
8: if ($row =~ /<strong>(Fri|Sat|Sun|Mon|Tue|Wed|Thu)\./is) {
9: $table .= $row;
10: }
11: }
12: $table =~ s/src="([^\"]+)"/'src="' .
13: url($1,$data{'url'})->abs->as_string . '"'/eisg;
14: $table =~ s/"#FF[9C]+66"/"#8FCDFF"/g; # #FF9966 oder #FFCC66
15:
16: $table .= "</table>";
17: print "$table\n";
18: }
Der größte Teil dieses Codes besteht aus regulären Ausdrücken, doch wenn Sie eine Vorstellung davon haben, wonach wir suchen, ist das Entziffern des Codes einfacher. In Abbildung 21.2 sehen Sie das, was wir als Ergebnis anstreben: Dazu gehören eine oberste Zeile (»Four-Day Forecast«) und vier lange Zellen mit den Wettergrafiken und den Temperaturangaben.
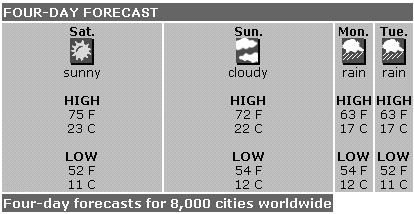
Abbildung 21.2: Der Wetterteil meiner Homepage
Jedes dieser Elemente wird in der Webseite durch Tabellenreihen repräsentiert.
Deshalb sucht der erste reguläre Ausdruck in Zeile 3 nach Code für Tabellenreihen -
das heißt Text, der von den Tags <TR> und </TR> umgeben ist. In einer Hinsicht ist
dieser reguläre Ausdruck allerdings etwas tükkisch - er verwendet ein Muster, das Sie
in den Kapiteln 9 und 10 nicht direkt gelernt haben (es wurde zwar im
Vertiefungsabschnitt angesprochen, aber fand im Hauptteil keine Erwähnung).
Vielleicht erinnern Sie sich, dass .* ein gieriger Quantifizierer ist, der mit Freude alles
bis ans Ende der Reihe »aufsaugt«. Das ist zwar nicht gerade eine glückliche Lösung,
aber leider hier nicht zu vermeiden, da wir eine Übereinstimmung bis </TR> und nicht
bloß für ein einziges Zeichen benötigen. Aus diesem Grunde verwenden wir .*?, eine
spezielle nichtgierige Version des Musters .* - es führt den Abgleich bis zum ersten
Vorkommen von </TR> durch und hält dann an, anstatt alles abzugleichen und danach
von hinten zu prüfen.
Das einzige, was an dem Ausdruck in Zeile 3 noch bemerkenswert ist, sind die
Optionen: g für global, um der while-Schleife die Gelegenheit zu geben alles
abzugleichen, i für eine Suche, die nicht zwischen Groß- und Kleinschreibung
unterscheidet, und s, damit der Punkt (.) zeilenübergreifend abgleicht (zur Erinnerung:
die gesamte HTML-Datei ist mitsamt seinen Neue-Zeile-Zeichen als ein String in
$content gespeichert).
Sind wir auf Tabellenreihen gestoßen, besteht der nächste Schritt darin, nach den
gewünschten Tabellenreihen Ausschau zu halten. Die erste ist die dunkle oberste
Reihe in Zeile 5, die einfach nur Textzeichen enthält. Darauf folgen die eigentlichen
Wetterreihen, die durch Abgleich mit den Tagesnamen (Zeile 8) ermittelt werden,
wobei das Muster mit einem <strong>-Tag beginnt und mit einem Punkt endet. Bei
jedem Abgleich hängen wir den übereinstimmenden Code an den String $table an
und bauen so die HTML-Tabelle für unsere Webseite auf.
In den Zeilen 12 bis 14 polieren wir die so aufgebaute Tabelle noch etwas auf. Zeile 12 bedient sich des URL-Codes, den Sie im vorigen Abschnitt kennengelernt haben, und expandiert die URLs der Grafikdateien, so dass sie auch wirklich auf die zugehörigen Websites zeigen. Zeile 14 ist eher persönlicher Art: Hier habe ich die Hintergrundfarben der Wetterreihen, die verschiedene Orangetöne aufweisen, in Blau geändert (ich mag einfach kein Orange).
In den Zeilen 16 und 17 wird die Tabelle nur noch mit einem schließenden </table>-
Tag abgeschlossen; anschließend wird das Ergebnis ausgegeben. Von hier aus
springen wir zurück zu unserem Skript meinehomepage.pl, geben die verschiedenen
Links in dem other-Hash aus und erhalten als Ergebnis eine individuelle Webseite, die
nur das enthält, was Sie sehen wollen.
Dieses System ist natürlich nicht unfehlbar. Werden die Quellseiten überarbeitet oder zu anderen URLs verschoben, müssen Sie Ihre Konfigurationen ändern. Wenn Sie Glück haben und Ihren Code so allgemein wie möglich halten, müssen Sie nicht allzu oft Änderungen vornehmen - dies ist einer der Nachteile, wenn man sich auf die Webseiten dritter verlassen muss.
Unser zweites - und letztes - Beispiel ist eine einfache Aufgabenlisten-Anwendung namens Aufgabenliste.pl, die im Web ausgeführt werden kann. Sie können Listeneinträge hinzufügen, löschen und ändern, nach Datum, Priorität oder Beschreibungen sortieren und Einträge als fertig markieren. In Abbildung 21.3 sehen Sie ein Beispiel für eine Aufgabenliste.
Die Aufgabenlisten-Anwendung besteht aus einer großen Tabelle, in der die einzelnen Aufgaben eingetragen sind. Jeder Eintrag besteht aus einem Markierungskästchen, das anzeigt, ob die Aufgabe erledigt ist oder nicht, sowie Feldern für die Priorität, die Fälligkeit und die Beschreibung. Die Daten dieser Tabelle können über die Formularelemente, aus denen die Tabelle aufgebaut ist, bearbeitet werden. Die Änderungen werden gültig, wenn der Benutzer den Schalter Aktualisieren drückt. Auch das Entfernen eines Elements (die Markierungskästchen in der ganz rechten Spalte der Tabelle), das Sortieren nach einem Feld (Auswahlfeld Sortieren nach unter der Tabelle) und die Entscheidung, ob erledigte Aufgaben angezeigt werden sollen oder nicht (das Markierungskästchen Erledigte Einträge anzeigen ebenfalls unter der Tabelle) werden erst nach Betätigen von Aktualisieren gültig.
Außer der Tabelle und den Anzeigeoptionen gibt es noch einen Bereich zum Einfügen neuer Einträge in die Liste. Nachdem Sie die Felder in diesem Teil der Anwendung ausgefüllt und Neuer Eintrag ausgewählt haben, werden diese Eingaben als neuer Eintrag mit aufgenommen (und alle anderen Änderungen werden ebenfalls gültig).
Wie schon bei Meine Homepage ist das der Aufgabenliste zugrundeliegende Skript ein CGI-Skript, das direkt als URL ausgeführt wird und kein Formular benötigt. Das Skript erzeugt seinen eigenen Inhalt, einschließlich der Formulare, mit denen Sie die Elemente in der Liste oder deren Anzeige ändern können. Alles geschieht in einem Skript. Der einzige zusätzliche Teil ist eine Datendatei - listdaten.txt -, die die Daten der Aufgaben speichert und von dem Aufgabenskript gelesen und beschrieben werden kann.
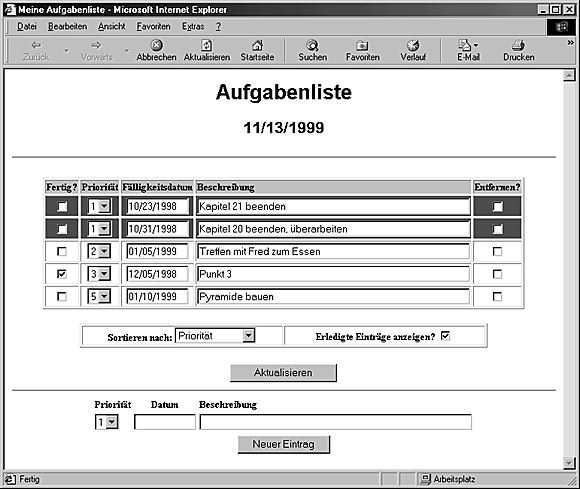
Abbildung 21.3: Die Web-Anwendung einer Aufgabenliste
Dieses Skript ist doppelt so lang wie alles, was wir bisher in diesem Buch behandelt haben. Deshalb werde ich, wie schon im Beispiel zuvor, nicht jede Zeile einzeln besprechen. Das vollständige Skript befindet sich am Ende dieses Abschnitts in Listing 21.5 und ist darüber hinaus auf der CD und der Website zu diesem Buch erhältlich. In diesem Abschnitt beschreibe ich den Fluß und die allgemeine Struktur dieses Skripts. Sollten Sie über das Besprochene hinaus noch Fragen dazu haben, gehen Sie den Code ruhig einmal selbst durch.
Wie die meisten Beispiele, die wir diese Woche betrachtet haben, hat auch dieses Skript eine Datendatei, aus der es liest und in die es schreibt, um die Daten auf dem aktuellen Stand zu halten. Die Datendatei zu diesem Skript, genannt listdata.txt, speichert die Daten der einzelnen Aufgaben. Das Skript Aufgabenliste.pl liest diese Datei bei jeder Iteration und schreibt bei jeder Änderung die neuen Daten zurück. Diese Datei ähnelt stark den Datendateien, die Sie bereits in anderen Beispielen kennengelernt haben:
desc=Kapitel 21 beenden
date=23.10.1998
prior=1
done=0
---
desc=Punkt 3
date=05.12.1998
prior=3
done=1
---
desc=Pyramide bauen
date=10.01.1999
prior=5
done=0
---
desc=Kapitel 20 beenden, überarbeiten
date=31.10.1998
prior=1
done=0
---
desc=Treffen mit Fred zum Essen
date=05.01.1999
prior=2
done=0
---
Wie schon in der Datendatei für das Meine Homepage-Skript werden die einzelnen
Datensätze in der Datei durch drei Bindestriche (---) getrennt. Jedes Feld in dem
Datensatz hat einen Schlüssel und einen Wert, die durch ein Gleichheitszeichen
voneinander getrennt sind. Im Gegensatz zu den Daten für Meine Homepage gibt es
hier keine mehrzeiligen Datensätze, sondern nur Schlüssel und Werte.
Wenn das CGI-Skript für die Aufgabenliste installiert wird, muss auch eine Datendatei angelegt werden, die der Webserver lesen und beschreiben kann. Diese Datendatei kann leer sein - das Skript wird dann eine Webseite ohne Einträge erzeugen -, muss aber vorhanden sein, damit das Skript funktioniert.
Das Skript Aufgabenliste.pl ist zwar groß, aber nicht sonderlich kompliziert. Es gibt
nur wenige verwirrende reguläre Ausdrücke, und der Fluß von Funktion zu Funktion
ist auch ziemlich überschaubar. Genau genommen besteht ein Großteil des Skripts aus
print-Anweisungen, um den HTML-Code für die Aufgabenliste und ihre
verschiedenen Formularelemente zu erzeugen - und diese Elemente so anzupassen,
dass sie sich in verschiedenen Situationen unterschiedlich verhalten.
Die ersten Subroutinen für das Skript Aufgabenliste.pl lauten &init() und
&process(). &init() legt das aktuelle Datum fest, ruft die Subroutine &read_data()
auf und gibt den obersten Teil der HTML-Datei aus, die von dem Skript erzeugt
werden soll. An diesem Punkt wollen wir mit der Besprechung beginnen und uns von
dort nach unten vorarbeiten.
Die Hauptaufgabe der Initialisierungs-Subroutine besteht darin, dass &read_data()
aufgerufen wird, so dass die Datendatei geöffnet und die einzelnen Einträge in eine
Datenstruktur eingelesen werden. Bei dieser Datenstruktur handelt es sich um ein
Array von Hashes, wobei die einzelnen Hashes die Daten für die verschiedenen
Aufgaben der Liste enthalten. Die Schlüssel in dem Hash lauten:
desc - die Beschreibung des Eintrags
date - das Fälligkeitsdatum für das Element. Das Datum hat das Format MM/TT/
JJJJ (dieses Format wird vom Skript verlangt)
prior - die Priorität des Elements von 1 (höchste Priorität) bis 5
done - zeigt an, ob die Aufgabe erledigt ist oder nicht
Zusätzlich zu diesen Schlüsseln, die aus der Datendatei kommen, bekommt jeder Eintrag in der Liste noch eine ID-Nummer. Dieser ID werden während des Einlesens Werte von 0 bis »Anzahl der Einträge« zugewiesen. Die ID wird später benötigt, um die verschiedenen Formularelemente für die Listenelemente auseinanderzuhalten.
Die Routine &process() erledigt den wesentlichen Teil der Arbeit in dem Skript. In
dieser Subroutine gibt es zwei Hauptzweige, die auf der param()-Funktion aus dem
Modul CGI.pl basieren. Am Tag 16 habe ich Ihnen param() vorgestellt, und Sie
haben gelernt, wie man diese Funktion dazu nutzt, um Werte aus Formularelementen
auszulesen. Die Funktion param() läßt sich allerdings auch ohne Argumente
anwenden, in welchem Falle sie die Namen aller vorhandenen Formularelemente oder
- falls das Skript nicht für ein Formular aufgerufen wurde - den undefinierten Wert
(undef) zurückliefert. Dieses Verhalten machen wir uns in der Subroutine &process()
zunutze, um zwei verschiedene Ergebnisse zu erhalten:
&display_all()) angezeigt.
&remove_selected()), alle Daten aktualisiert (mit der Subroutine
&update_data()), die Daten zurück in die Datei geschrieben (mit der Subroutine
&write_data()) und diese dann wieder angezeigt (mit der Subroutine
&display_all()).
&add_item() eine
weitere Aufgabe der Aufgabenliste als neuer Eintrag hinzugefügt wird.
Während der ganzen Aktualisierungs- und Hinzufügeoperationen prüfen wir gleichzeitig auf Formatierungsfehler in den Daten. Doch mehr dazu später, wenn ich auf die Aktualisierung der Daten und das Hinzufügen von neuen Listenelementen zu sprechen komme.
Der größte Teil des Aufgabenlisten-Skripts steckt allerdings in den Subroutinen
&display_all() und &display_data(). Diese Subroutinen erzeugen nicht nur den
HTML-Code für die Daten; die Datentabelle ist auch ein Formular, und alle Elemente
in diesem Formular müssen automatisch erzeugt werden. Außerdem ist ein Großteil
des HTML-Codes einer Reihe von Bedingungen unterworfen, die sich aus den
Zuständen der Tabelle ergeben. So werden zum Beispiel Aufgaben mit der Priorität 1
in Rot ausgegeben, und die Auswahlfelder für die Prioritäten müssen so initialisiert
werden, dass sie die aktuellen Werte der Datensätze widerspiegeln. Anstatt also für
diesen Teil des Skripts ein riesiges Hier-Dokument zu verwenden, müssen wir Zeile für
Zeile durchgehen, um es zu erzeugen.
Die Subroutine &display_all() ist die Hauptroutine, die als erstes aufgerufen wird.
Sie startet die Tabelle, gibt die Header aus, sortiert das Hauptarray nach der aktuell
vorgegebenen Sortierreihenfolge und ruft dann innerhalb einer for-Schleife
&display_data() auf, um die einzelnen Einträge in der Aufgabenliste auszugeben.
Außerdem erzeugt es die Elemente unter den Daten: das Auswahlfeld Sortieren
nach, das Markierungskästchen Erledigte Einträge anzeigen, die
Formularelemente zum Hinzufügen eines neues Eintrags und die beiden Schalter zum
Abschicken des Formulars. Nebenbei kontrolliert die Subroutine, ob ein Fehler bei der
Verarbeitung der Datumsangaben aufgetreten ist, und gibt entsprechende Warnungen
aus. Für all dieses benötigen Sie eine Menge von bedingten Befehlen und print-
Anweisungen sowie eine Menge Zeilen HTML-Code.
Der Subroutine &display_data() obliegt die Aufgabe, die einzelnen Einträge in der
Aufgabenliste zu verarbeiten. Jede Reihe der Tabelle besteht aus fünf Spalten, die
jeweils ein Formularelement enthalten. Jedes Element bedarf eines eindeutigen
Namens, und viele Formularelemente ändern ihre Erscheinung, je nachdem welche
Daten sie widerspiegeln (so muss zum Beispiel das Markierungskästchen am Beginn
der Reihe markiert sein, wenn eine Aufgabe erledigt ist). Die Subroutine
&display_data() sorgt auch dafür, dass Einträge NICHT angezeigt werden - wenn
das Markierungskästchen Erledigte Einträge anzeigen nicht markiert ist, werden
die Aufgaben, die als erledigt markiert wurden, nicht angezeigt. Es wird aber ein
verborgenes Formularelement erzeugt, das einige der Daten der Aufgabe enthält, so
dass die Aktualisierungen ordnungsgemäß durchgeführt werden können.
Wie schon bei &display_all() bedeutet auch dies eine Menge von if-Anweisungen
und viel HTML-Code. Das Ergebnis ist ein gigantisches Formular, bei dem jedes
Formularelement mit einer Aufgabe verbunden ist; es zeigt stets die aktuellen Daten
der Aufgabenliste an. Wenn Sie irgend etwas an diesen Daten ändern, werden die
Änderungen beim Abschicken des Formulars in die Originaldatensammlung
übernommen.
Da wir inzwischen beim Eintragen der Änderungen angelangt sind, möchte ich auf die
Subroutine &update_data() zu sprechen kommen. Diese Subroutine wird sowohl für
den Schalter Aktualisieren als auch für den Schalter Neuer Eintrag aufgerufen,
denn es soll sichergestellt werden, dass alle Änderungen am Skript in beiden Fällen
übernommen werden. Die Aufgabe von &update_data() besteht darin, alle
Formularelemente der Seite zu durchlaufen - die Element für die Listeneinträge und
die Formularelemente Sortieren nach und Erledigte Einträge anzeigen - und die
Daten oder globalen Einstellungen entsprechend den Änderungen, die auf einer
Webseite vorgenommen wurden, zu aktualisieren.
Doch konzentrieren wir uns auf die Daten selbst. Jedes Element des HTML-
Formulars, das durch &display_data() erzeugt wird, trägt einen eindeutigen Namen,
der aus dem Namen des Feldes (Beschreibung, Priorität und so weiter) und der ID-
Nummer dieses Elements erzeugt wird. Durch Teilen der Liste der
Formularelementnamen, die zurückgeliefert werden, wenn das Formular abgeschickt
wurde, können wir feststellen, welcher Name zu welchem Teil eines Datensatzes
gehört, und die Werte vergleichen. Sollten diese nicht identisch sein, aktualisieren wir
den Datensatz mit dem neuen Wert. Jedesmal, wenn das Formular abgeschickt wird,
werden die Elemente einzeln geprüft. Das ist zwar nicht unbedingt der effizienteste
Weg, Änderungen in den Daten zu verfolgen, aber wir können dadurch alles auf einer
Seite belassen.
Eine andere Aufgabe, die die Subroutine &update_data() noch erfüllt, ist die Prüfung
auf fehlerhafte Datumsangaben in den bestehenden Daten. Wenn Sie versuchen, ein
Datum hinsichtlich seines normalen Formats zu ändern (10/9/1998 oder so ähnlich),
wird dies von &update_data() aufgefangen und ein Fehler generiert, der dann beim
nächsten Aufruf von &display_all() für den Datensatz angezeigt wird.
Um Einträge aus der Liste zu entfernen, markieren Sie die Markierungskästchen in
der Entfernen-Spalte für die betreffenden Daten und klicken auf Aktualisieren. Um
ein Element der Liste hinzuzufügen, geben Sie diese Daten am Ende der Seite in das
Formular ein und klicken auf Neuer Eintrag. In beiden Fällen wird
&remove_selected() aufgerufen, im letzteren Fall darüber hinaus &add_item().
Die Subroutine &remove_selected()aktualisiert die Daten, indem die vom Benutzer
zum Löschen vorgesehenen Datensätze entfernt werden. In diesem Fall ist das
Entfernen der Elemente einfach, da unsere ganzen Daten in einem Array von
Referenzen gespeichert sind. Wir richten einfach ein weiteres Array von Referenzen
ein, abzüglich der, die wir löschen wollen, und legen dieses neue Array in der
Variablen des alten Arrays ab. Da es sich hierbei um ein Array von Referenzen
handelt, bleiben alle Daten, auf die mit den Referenzen verwiesen wird, an ihrer
Position und müssen nicht umkopiert werden.
Die Subroutine &add_item() ist ebenfalls einfach. Wir müssen die Daten aus den
Formularelementen nur in einem Hash ablegen und in dem Datenarray eine Referenz
auf diesen Hash einrichten. Wir weisen dem neuen Eintrag außerdem eine neue ID zu,
die um eins höher liegt als die momentan größte ID. (Wenn dazwischenliegende
Einträge gelöscht wurden, versuchen wir nicht, deren IDs neu zu vergeben - die
Einträge erhalten ehedem neue IDs, wenn die Datei bei der nächsten Iteration des
Skripts wieder eingelesen wird).
Übriggeblieben sind jetzt nur noch ein paar kleine, aber wichtige Subroutinen:
&write_data(), um die Daten zurück in die Datei listdaten.txt zu schreiben, und zwei
Subroutinen für die Datenformate und die Vergleiche.
Die Subroutine &write_data ist einfach: Ihre einzige Aufgabe besteht darin, die Datei
listdaten.txt zum Schreiben zu öffnen und dann die Datensätze durchzugehen und in
die Datei zu schreiben. Da diese Subroutine jedesmal, wenn das Skript ausgeführt wird
und nachdem irgendwelche Änderungen an den Daten vorgenommen wurden,
aufgerufen wird, können wir fast absolut sicher sein, dass die Daten nie korrumpiert
werden oder Einträge verlorengehen. Beachten Sie, dass die IDs der Einträge nicht
mit dem Rest der Daten in die Datendatei geschrieben werden. Die IDs werden
erzeugt, wenn die Daten anfangs eingelesen werden, und nur dazu benötigt, um die
Formularelemente zuordnen zu können. Darum müssen Sie nicht zwischen den
Skriptaufrufen gespeichert werden.
Die letzten zwei Subroutinesätze beziehen sich auf die Datumsangaben.
Datumsangaben haben, wie ich bereits erwähnt habe, das Format MM/TT/JJJJ. Es ist
wichtig, ein konsistentes Format zu verwenden, da es nur dadurch möglich ist, die
Liste der Elemente nach dem Datum zu sortieren - eine Art von numerischer
Sortierung. Um das Datumsformat in eine Zahl zu verwandeln, die dann mit einer
anderen Zahl verglichen werden kann, muss die Formatierung stimmen. Aus diesem
Grund wird jede geänderte oder mit einem neuen Eintrag hinzukommende
Datumsangabe mit der Subroutine &check_date() auf ihr Format hin geprüft. Liegen
Abweichungen im Format vor, wird ein Fehler ausgegeben (eine große rote Meldung
oben auf der Webseite und Sternchen in dem falschen Datum).
Die Sortierung der Liste nach dem Datum erfolgt in der Subroutine &display_all().
Dazu muss der Wert im Menü Sortieren nach auf Datum eingestellt worden sein.
Um die Datumsangaben in etwas zu konvertieren, das mit etwas anderem verglichen
werden kann, verwenden wir das Modul Time::Local. Dabei handelt es sich um ein
vorgegebenes Modul, das dazu verwendet werden kann, verschiedene Teile einer
Datums- oder Zeitangabe in ein time-Format zu konvertieren - das ist die Anzahl der
Sekunden seit 1900 (das ist der Wert, der von der time-Funktion zurückgeliefert wird).
Diesem Zwecke dient die Subroutine &date2time(), die die korrekt formatierte
Datumsangabe in ihre Elemente aufsplittet und den time-Wert zurückliefert. Diese
Routine hält gleichzeitig Ausschau nach falsch formatierten Datumsangaben - mit
führenden Sternchen - und sortiert diese Werte ganz nach oben.
Beachten Sie, dass wir für die Jahresangabe in allen Daten unseres Skripts eine
vierstellige Zahl verwenden. Damit stellt der Jahreswechsel 2000 kein Problem für uns
dar. Time::Local ist eigentlich recht gut darin, festzustellen, ob eine zweiziffrige
Jahresangabe in diese Epoche fällt oder in die nächste. Aber ich fand, dass es besser
sei, sicherzugehen. Denn es kann durchaus sein, dass Sie dieses Buch im Jahr 2000
lesen.
Listing 21.5 enthält den (ziemlich) vollständigen Code für das Skript
Aufgabenliste.pl. Gehen Sie es von vorn nach hinten durch. Kritisch sind nur die
Teile, die mit der Vergabe der IDs an die Formularelemente und mit der Behandlung
von Fehlern in den Datumsangaben zu tun haben (achten Sie auf die Subroutine
&check_date()). Und wie bei allen CGI-Skripts ist es von Vorteil, wenn Sie HTML-
Kenntnisse haben und wissen, wie Formulare und CGI.pm miteinander agieren.
Listing 21.5: Der Code für Aufgabenliste.pl
1: #!/usr/bin/perl -w
2: use strict;
3: use CGI qw(:standard);
4: use CGI::Carp qw(fatalsToBrowser);
5: use Time::Local;
6:
7: my $listdata = 'listdaten.txt'; # Datendatei
8: my @data = (); # Array von Hashes
9: my $id = 0; # oberste ID
10:
11: # global Standardeinstellungen
12: my $sortby = 'prior'; # Sortierreihenfolge
13: my $showdone = 1; # Bearbeitete Einträge anzeigen? (1 == ja)
14:
15: &init();
16: &process();
17:
18: sub init {
19: # aktuelles Datum ermitteln und im Format MM/TT/YY ausgeben
20: my ($day,$month,$year) = 0;
21: (undef,undef,undef,$day,$month,$year) = localtime(time);
22: $month++; # Monate starten bei 0
23: $year += 1900; # Perl-Jahre sind die Jahre seit 1900;
24:
25: my $date = "$month/$day/$year";
26:
27: # Datendatei öffnen und lesen
28: &read_data();
29:
30: # HTML-Code
31: print header;
32: print start_html('Meine Aufgabenliste');
33: print "<H1 ALIGN=CENTER><FONT FACE=\"Helvetica,Arial\" SIZE+2>";
34: print "Aufgabenliste</FONT></H1>\n";
35: print "<H2 ALIGN=CENTER><FONT FACE=\"Helvetica,Arial\" SIZE+2>";
36: print "$date</FONT></H2>\n";
37: print "<HR>\n";
38: print "<FORM ACTION=\"/cgi-bin/Aufgabenliste.pl\" METHOD=POST>\n";
39: }
40:
41: sub process {
42: my $dateerror = 0; # Fehler im Datumsformat der alten Liste
43: my $newerror = 0; # Fehler im Datumsformat des neuen Eintrags
44:
45: # Hauptverzweigung. Es gibt zwei Möglichkeiten:
46: # keine Parameter, alles anzeigen
47: # irgendwelche Parameter: aktualisieren, Eintrag hinzufügen,
# schreiben und anzeigen
48: if (!param()) { # nur beim ersten Mal
49: &display_all();
50: } else { # Schalter behandeln
51: &remove_selected();
52: $dateerror = &update_data(); # vorhandene Änderungen
# aktualisieren
53:
54: # Elemente hinzufügen
55: if (defined param('additems')) {
56: $newerror = &check_date(param('newdate'));
57: if (!$newerror) {
58: &add_item();
59: }
60: }
61:
62: &write_data();
63: &display_all($dateerror,$newerror);
64: }
65:
66: print end_html;
67: }
68:
69: # Datendatei in ein Array von Hashes einlesen
70: sub read_data {
71: open(DATA, $listdata) or
die " Datendatei kann nicht geöffnet werden: $!";
72: my %rec = ();
73: while (<DATA>) {
74: chomp;
75: if ($_ =~ /^\#/) { next;} # Kommentare
76:
77: if ($_ ne '---' and $_ ne '') { # Datensatz erstellen
78: my ($key, $val) = split(/=/,$_,2);
79: $rec{$key} = $val;
80: } else { # Ende des Datensatzes
81: $rec{'id'} = $id++;
82: push @data, { %rec };
83: %rec = ();
84: }
85: }
86: close(DATA);
87: }
88:
89: # HTML-Ausgabe
90: sub display_all {
91: my $olderror = shift; # ist ein Fehler aufgetreten?
92: my $newerror = shift;
93:
94:
95: print "<TABLE BORDER WIDTH=75% ALIGN=CENTER>\n";
96:
97: if ($olderror or $newerror) {
98: print "<P><FONT COLOR=\"red\">
<B>Fehler: Daten, die mit *** markiert sind";
99: print "haben falsches Format (verwende MM/TT/JJJJ)</B>
</FONT><P>\n";
100: }
101:
102: print "<TR BGCOLOR=\"silver\"><TH>Fertig?<TH>Priorität";
103: print "<TH>Fälligkeitsdatum
<TH ALIGN=LEFT>Beschreibung<TH>Entfernen?</TR>\n";
104:
105: # Sortierreihenfolge festlegen (numerisch oder alphabetisch)
106: my @sdata = ();
107:
108: # Array von Hashes gemäß Wert von $sortby sortieren
109: if ($sortby eq 'date') { # nach Datum sortieren
110: @sdata = sort {&date2time($a->{'date'}) <=>
111: &date2time($b->{'date'})} @data;
112: } else { # Text/Priorität-Sortierung
113: @sdata = sort {$a->{$sortby} cmp $b->{$sortby}} @data;
114: }
115:
116: # Einträge der Reihe nach ausgeben
117: foreach (@sdata) {
118: &display_data(%$_); # Datensatz verarbeiten
119: }
120:
121: print "</TABLE>\n";
122:
123: # Tabelle für Einstellungen
124: print "<P><TABLE BORDER WIDTH=75% ALIGN=CENTER>\n";
125: print "<TR><TD ALIGN=CENTER><B>Sortieren nach:</B> <SELECT
NAME=\"sortby\">\n";
126:
127: # Wert aus sortby abfragen, Auswahlfeld anzeigen
128: print "<OPTION VALUE=\"prior\" ";
129: if ($sortby eq 'prior') { print "SELECTED>"}
130: else { print ">"; }
131: print "Priorität\n";
132: print "<OPTION VALUE=\"date\" ";
133: if ($sortby eq 'date') { print "SELECTED>"}
134: else { print ">"; }
135: print "Datum\n";
136: print "<OPTION VALUE=\"desc\" ";
137: if ($sortby eq 'desc') { print "SELECTED>"}
138: else { print ">"; }
139: print "Beschreibung\n";
140: print "</SELECTED></TD>\n";
141:
142:
143: # Wert von showdone abfragen, Markierungskästchen anzeigen
144: print "<TD ALIGN=CENTER WIDTH=50%><B>
Erledigte Einträge anzeigen?<B>\n";
145: my $checked = '';
146: if ($showdone == 1) { $checked = 'CHECKED'}
147: print "<INPUT TYPE=\"checkbox\" NAME=\"showdone\"
VALUE=\"showdone\"";
148: print " $checked> </TD>\n";
149:
150: # Aktualisieren-Schalter und Tabelle zum Hinzufügen von Einträgen
151: print <<EOF;
152: </TR></TABLE>
153: <P><TABLE ALIGN=CENTER>
154: <TR><TD ALIGN=CENTER VALIGN=CENTER>
155: <INPUT TYPE="submit" VALUE=" Aktualisieren "
NAME="update"></TD></TR>
156: </TABLE><HR>
157: <TABLE ALIGN=CENTER>
158: <TR><TH>Priorität<TH>Datum<TH ALIGN=LEFT>Beschreibung
159: EOF
160: # Prioritäten-Auswahlfeld;
161: print "<TR><TD><SELECT NAME=\"newprior\">\n";
162: my $i;
163: foreach $i (1..5) { # Prioritäten von 1 bis 5
164: if ($newerror and param('newprior') == $i) {
165: $checked = 'SELECTED';
166: }
167: print "<OPTION $checked>$i\n";
168: }
169: print "</SELECT></TD>\n";
170:
171: # Datum und Beschreibung ausgeben;
172: # Fehlerfälle beachten
173: my $newdate = '';
174: my $newdesc = '';
175: print "<TD ALIGN=CENTER><INPUT TYPE=\"text\" NAME=\"newdate\"";
176: if ($newerror) { # Fehler aufgetreten?
177: $newdate = "***" . param('newdate');
178: $newdesc = param('newdesc');
179: }
180: print "VALUE=\"$newdate\" SIZE=10></TD> \n";
181:
182: # Beschreibung; im Fehlerfalle alten Wert beibehalten
183: print "<TD><INPUT TYPE=\"text\" NAME=\"newdesc\"
VALUE=\"$newdesc\"";
184: print "SIZE=50></TD></TR></TABLE><TABLE ALIGN=CENTER>\n";
185:
186: # fertigstellen
187: print <<EOF;
188: <TR><TD ALIGN=CENTER VALIGN=CENTER>
189: <INPUT TYPE="submit" VALUE="Neuer Eintrag"
NAME="additems"></TD></TR>
190: </TABLE></FORM>
191: EOF
192: }
193:
194: # Daten zeilenweise ausgeben. Daten sind bereits sortiert;
195: # einzelnen Datensatz ausgeben
196: sub display_data {
197: my %rec = @_; # auszugebender Datensatz
198:
199: # Keine erledigten Einträge anzeigen, wenn die Option
200: # Erledigte Einträge anzeigen nicht markiert ist.
201: # Der Einfachheit halber die Einträge aber mit
202: # verarbeiten
203: if ($showdone == 0 and $rec{'done'}) {
204: print "<INPUT TYPE=\"hidden\" NAME=\"Erledigt", $rec{'id'};
205: print "\">\n";
206: next;
207: }
208:
209: # Einträge mit Priorität 1 in Rot ausgeben
210: my $bgcolor = '';
211: if ($rec{'prior'} == 1) {
212: $bgcolor = "BGCOLOR=\"red\"";
213: }
214:
215: # Erledigt oder nicht erledigt?
216: my $checked = ''; # Erledigte Einträge
217: if ($rec{'done'}) {
218: $checked = 'CHECKED';
219: }
220:
221: print "<TR>\n"; # mit Reihe beginnen
222:
223: # Erledigt-Kästchen
224: print "<TD WIDTH=10% ALIGN=CENTER $bgcolor>";
225: print "<INPUT TYPE=\"checkbox\" NAME=\"done", $rec{'id'};
226: print "\" $checked></TD>\n";
227:
228: # Priorität
229: print "<TD WIDTH=10% ALIGN=CENTER $bgcolor>";
230: print "<SELECT NAME=\"prior", $rec{'id'}, "\">\n";
231: my $selected = '';
232: my $i;
233: foreach $i (1..5) { # Prioritäten von 1 bis 5
234: if ($rec{'prior'} == $i) {
235: $selected = 'SELECTED';
236: }
237: print "<OPTION $selected>$i\n";
238: $selected = '';
239: }
240: print "</SELECT></TD>\n";
241:
242: # Datum
243: print "<TD $bgcolor WIDTH=10% ALIGN=CENTER>";
244: print "<INPUT TYPE=\"text\" SIZE=10 NAME=\"date", $rec{'id'}, "\" ";
245: print "VALUE=\"", $rec{'date'}, "\"></TD>\n";
246:
247: # Beschreibung
248: print "<TD $bgcolor><INPUT TYPE=\"text\" NAME=\"desc", $rec{'id'};
249: print "\" SIZE =50 VALUE=\"", $rec{'desc'}, "\"></TD>\n";
250:
251: # Entfernen-Kästchen
252: print "<TD $bgcolor ALIGN=CENTER>";
253: print "<INPUT TYPE=\"checkbox\" NAME=r", $rec{'id'}, "></TD>";
254:
255: # Ende der Reihe
256: print "</TR>\n";
257: }
258:
259: # Alle Werte aktualisieren
260: sub update_data {
261: my $error = 0; # Fehlerbehandlung
262:
263: # wurde showdone ausgewählt?
264: if (defined param('showdone')) {
265: $showdone = 1;
266: } else { $showdone = 0; }
267:
268: # Wert von sortby abfragen
269: $sortby = param('sortby');
270:
271: foreach (@data) {
272: my $id = $_->{'id'}; # nicht das globale $id
273:
274: # Einträge , die als erledigt markiert sind, können nicht
275: # geändert werden. In so einem Fall können wir die
276: # Überprüfung der weiteren Daten dieses Eintrags getrost
277: # übergehen.
278: if ($_->{'done'} == 1 && defined param('done' . $id)) { next; }
279:
280: # Einträge, die als erledigt markiert wurden.
281: if (defined param('done' . $id)) {
282: $_->{'done'} = 1;
283: } else { $_->{'done'} = 0; }
284:
285: # Datum. Auf fehlerhafte Datumsangaben prüfen
286: if (param('date' . $id) ne $_->{'date'}) {
287: $error = check_date(param('date' . $id));
288: if ($error) {
289: $_->{'date'} = "***" . param('date' . $id);
290: } else {
291: $_->{'date'} = param('date' . $id);
292: }
293: }
294:
295: # Priorität, Beschreibung
296: my $thing;
297: foreach $thing ('prior', 'desc') {
298: if (param($thing . $id) ne $_->{$thing}) {
299: $_->{$thing} = param($thing . $id);
300: }
301: }
302: }
303: return $error;
304: }
305:
306: # Einträge löschen
307: sub remove_selected {
308: my @newdata = ();
309:
310: foreach (@data) {
311: my $id = $_->{'id'}; # nicht das globale id
312:
313: if (!defined param('r' . $id)) {
314: push @newdata, $_; # $_ ist die Referenz
315: }
316: }
317: @data = @newdata; # Eintrag löschen
318: }
319:
320: # neues Element hinzufügen. Wird nur aufgerufen, wenn check_date bereits OK ist
321: sub add_item {
322: my %newrec = ();
323:
324: $newrec{'desc'} = param('newdesc');
325: $newrec{'date'} = param('newdate');
326: $newrec{'prior'} = param('newprior');
327: $newrec{'done'} = 0;
328: $newrec{'id'} = $id++; # global ID + 1
329:
330: push @data, { %newrec };
331: }
332:
333: # Datumsangaben müssen das Format XX/XX/XX haben
334: sub check_date {
335: my $date = shift;
336:
337: # MM/TT/JJJJ, MM und TT können 0 oder 1 Zeichen haben, JJJJ müssen
338: # 4 sein. Abschließende Leerzeichen sind okay
339: if ($date !~ /^\d{1,2}\/\d{1,2}\/\d{4}\s*$/) {
340: return 1; # Fehler!
341: }
342: return 0; # OK
343: }
344:
345: # Datendatei überschreiben
346: sub write_data {
347: open(DATA, ">$listdata") or
die "Listendatei konnte nicht geöffnet werden: $!.";
348: foreach (@data) {
349: my %rec = %$_;
350:
351: foreach ('desc', 'date','prior','done') { # keine ids
352: print DATA "$_=$rec{$_}\n";
353: }
354: print DATA "---\n";
355: }
356: close(DATA);
357: }
358:
359: # Ich verwende das Datumsformat MM/TT/JJ. Um nach Datum zu sortieren,
360: # müssen Sie dieses Format in das Perl-Format (Sekunden-seit 1900)
361: # konvertieren. (Modul Time::Local, Funktion timelocal.)
362: sub date2time {
363: my $date = shift;
364: if ($date =~ /^\*\*\*/) { # Formatierungsfehler
365: return 0;
366: } else {
367: my ($m,$d,$y) = split(/\//,$date);
368: $m--; # Monate beginnen in Perls Zeitformat mit 0
369: return timelocal(0,0,0,$d,$m,$y);
370: }
371: }
Wenn jemand, der über keinerlei Perl-Kenntnisse verfügt, dieses Buch aufschlägt und das Skript in Listing 21.5 betrachtet, stünden die Chancen nicht schlecht, dass er ziemliche Schwierigkeiten mit dem Entziffern des Quelltextes hätte - auch wenn er schon einiges über Programmiersprachen wissen sollte (Perl ist in dieser Hinsicht etwas sonderbar). Nachdem Sie jetzt aber 21 Tage tief in die Sprache und ihre Idiosynkrasien eingetaucht sind, sollte Ihnen das Lesen dieses Quelltextes leichtfallen - oder zumindest nicht ganz ratlos zurücklassen.
Heute haben wir die Woche und das Buch mit den üblichen längeren Beispielen (einige länger als andere) beendet. Die beiden Skripts, die wir in diesem Kapitel untersucht haben, den Homepage-Generator und die Aufgabenliste, sind beides CGI- Skripts, die Daten von verschiedenen Quellen (oder mehreren Quellen) verarbeiten und HTML-Code als Ausgabe erzeugen. Das zweite Skript, die Aufgabenliste, erzeugte darüber hinaus sein eigenes Formular, mit dem es seine eigenen Daten verarbeiten kann. Das erste Skript ist ein gutes Beispiel dafür, wie man Code von verschiedenen Modulen aus dem CPAN mit eigenem Code zusammenklebt und allgemein gehaltene Anwendungen den eigenen Bedürfnissen anpaßt. Das letztere Skript demonstrierte den Aufbau eines HTML-Formulars und verwendete eine verschachtelte Datenstruktur zur Aufbewahrung seiner Daten. Mit diesen Skripts und der in den letzten 20 Kapiteln geleisteten Arbeit entlasse ich Sie jetzt, was Perl angeht, in die Welt ...