 | Chapter 1 |  |

| Chapter 1 | |
Contents:
Referring to Existing Variables
Using References
Nested Data Structures
Querying a Reference
Symbolic References
A View of the Internals
References in Other Languages
Resources
If I were meta-agnostic, I'd be confused over whether I'm agnostic or not - but I'm not quite sure if I feel that way; hence I must be meta-meta-agnostic (I guess).
- Douglas R. Hofstadter, Gödel, Escher, Bach
There are two aspects (among many) that distinguish toy programming languages from those used to build truly complex systems. The more robust languages have:
The ability to dynamically allocate data structures without having to associate them with variable names. We refer to these as "anonymous" data structures.
The ability to point to any data structure, independent of whether it is allocated dynamically or statically.
COBOL is the one true exception to this; it has been a huge commercial success in spite of lacking these features. But it is also why you'd balk at developing flight control systems in COBOL.
Consider the following statements that describe a far simpler problem: a family tree.
| Marge is 23 years old and is married to John, 24. |
| Jason, John's brother, is studying computer science at MIT. He is just 19. |
| Their parents, Mary and Robert, are both sixty and live in Florida. |
| Mary and Marge's mother, Agnes, are childhood friends. |
Do you find yourself mentally drawing a network with bubbles representing people and arrows representing relationships between them? Think of how you would conveniently represent this kind of information in your favorite programming language. If you were a C (or Algol, Pascal, or C++) programmer, you would use a dynamically allocated data structure to represent each person's data (name, age, and location) and pointers to represent relationships between people.
A pointer is simply a variable that contains the location of some other piece of data. This location can be a machine address, as it is in C, or a higher-level entity, such as a name or an array offset.
C supports both aspects extremely efficiently: You use malloc(3)[1] to allocate memory dynamically and a pointer to refer to dynamically and statically allocated memory. While this is as efficient as it gets, you tend to spend enormous amounts of time dealing with memory management issues, carefully setting up and modifying complex interrelationships between data, and then debugging fatal errors resulting from "dangling pointers" (pointers referring to pieces of memory that have been freed or are no longer in scope). The program may be efficient; the programmer isn't.
[1] The number in parentheses is the Unix convention of referring to the appropriate section of the documentation (man pages). The number 3 represents the section describing the C API.
Perl supports both concepts, and quite well, too. It allows you to create anonymous data structures, and supports a fundamental data type called a "reference," loosely equivalent to a C pointer. Just as C pointers can point to data as well as procedures, Perl's references can refer to conventional data types (scalars, arrays, and hashes) and other entities such as subroutines, typeglobs, and filehandles.[2] Unlike C, they don't let you peek and poke at raw memory locations.
[2] We'll study the latter set in Chapter 3, Typeglobs and Symbol Tables.
Perl excels from the standpoint of programmer efficiency. As we saw earlier, you can create complex structures with very few lines of code because, unlike C, Perl doesn't expect you to spell out every thing. A line like this:
$line[19] = "hello";
does in one line what amounts to quite a number of lines in C - allocating a dynamic array of 20 elements and setting the last element to a (dynamically allocated) string. Equally important, you don't spend any time at all thinking about memory management issues. Perl ensures that a piece of data is deleted when no one is pointing at it any more (that is, it ensures that there are no memory leaks) and, conversely, that it is not deleted when someone is still pointing to it (no dangling pointers).
Of course, just because all this can be done does not mean that Perl is an automatic choice for implementing complex applications such as aircraft scheduling systems. However, there is no dearth of other, less complex applications (not just throwaway scripts) for which Perl can more easily be used than any other language.
In this chapter, you will learn the following:
How to create references to scalars, arrays, and hashes and how to access data through them (dereferencing).
What Perl does internally to help you avoid thinking about memory management.
If you have a C background (not necessary for understanding this chapter), you know that there are two ways to initialize a pointer in C. You can refer to an existing variable:
int a, *p; p = &a; /* p now has the "address" of a */
The memory is statically allocated; that is, it is allocated by the compiler. Alternatively, you can use malloc(3) to allocate a piece of memory at run-time and obtain its address:
p = malloc(sizeof(int));
This dynamically allocated memory doesn't have a name (unlike that associated with a variable); it can be accessed only indirectly through the pointer, which is why we refer to it as "anonymous storage."
Perl provides references to both statically and dynamically allocated storage; in this section, we'll the study the former in some detail. That allows us to deal with the two concepts - references and anonymous storage - separately.
You can create a reference to an existing Perl variable by prefixing it with a backslash, like this:
# Create some variables
$a = "mama mia";
@array = (10, 20);
%hash = ("laurel" => "hardy", "nick" => "nora");
# Now create references to them
$ra = \$a; # $ra now "refers" to (points to) $a
$rarray = \@array;
$rhash = \%hash; You can create references to constant scalars in a similar fashion:
$ra = \10; $rs = \"hello world";
That's all there is to it. Since arrays and hashes are collections of scalars, it is possible to take a reference to an individual element the same way: just prefix it with a backslash:
$r_array_element = \$array[1]; # Refers to the scalar $array[1]
$r_hash_element = \$hash{"laurel"}; # Refers to the scalar
# $hash{"laurel"}A reference variable, such as $ra or $rarray, is an ordinary scalar - hence the prefix `$'. A scalar, in other words, can be a number, a string, or a reference and can be freely reassigned to one or the other of these (sub)types. If you print a scalar while it is a reference, you get something like this:
SCALAR(0xb06c0)
While a string and a number have direct printed representations, a reference doesn't. So Perl prints out whatever it can: the type of the value pointed to and its memory address. There is rarely a reason to print out a reference, but if you have to, Perl supplies a reasonable default. This is one of the things that makes Perl so productive to use. Don't just sit there and complain, do something. Perl takes this motherly advice seriously.
While we are on the subject, it is important that you understand what happens when references are used as keys for hashes. Perl requires hash keys to be strings, so when you use a reference as a key, Perl uses the reference's string representation (which will be unique, because it is a pointer value after all). But when you later retrieve the key from this hash, it will remain a string and will thus be unusable as a reference. It is possible that a future release of Perl may lift the restriction that hash keys have to be strings, but for the moment, the only recourse to this problem is to use the Tie::RefHash module presented in Chapter 9, Tie. I must add that this restriction is hardly debilitating in the larger scheme of things. There are few algorithms that require references to be used as hash keys and fewer still that cannot live with this restriction.
Dereferencing means getting at the value that a reference points to.
In C, if p is a pointer, *p refers to the value being pointed to. In Perl, if $r is a reference, then $$r, @$r, or %$r retrieves the value being referred to, depending on whether $r is pointing to a scalar, an array, or a hash. It is essential that you use the correct prefix for the corresponding type; if $r is pointing to an array, then you must use @$r, and not %$r or $$r. Using the wrong prefix results in a fatal run-time error.
Think of it this way: Wherever you would ordinarily use a Perl variable ($a, @b, or %c), you can replace the variable's name (a, b, or c) by a reference variable (as long as the reference is of the right type). A reference is usable in all the places where an ordinary data type can be used. The following examples show how references to different data types are dereferenced.
The following expressions involving a scalar,
$a += 2; print $a; # Print $a's contents ordinarily
can be changed to use a reference by simply replacing the string "a" by the string "$ra":
$ra = \$a; # First take a reference to $a $$ra += 2; # instead of $a += 2; print $$ra; # instead of print $a
Of course, you must make sure that $ra is a reference pointing to a scalar; otherwise, Perl dies with the run-time error "Not a SCALAR reference".
You can use ordinary arrays in three ways:
Access the array as a whole, using the @array notation. You can print an entire array or push elements into it, for example.
Access ranges of elements (slices), using the notation @array[index1,index2,...].
References to arrays are usable in all three of these situations. The following code shows an example of each, contrasting ordinary array usage to that using references to arrays:
$rarray = \@array;
push (@array , "a", 1, 2); # Using the array as a whole
push (@$rarray, "a", 1, 2); # Indirectly using the ref. to the array
print $array[$i] ; # Accessing single elements
print $$rarray[1]; # Indexing indirectly through a
# reference: array replaced by $rarray
@sl = @array[1,2,3]; # Ordinary array slice
@sl = @$rarray[1,2,3]; # Array slice using a reference
Note that in all these cases, we have simply replaced the string array with $rarray to get the appropriate indirection.
Beginners often make the mistake of confusing array variables and enumerated (comma-separated) lists. For example, putting a backslash in front of an enumerated list does not yield a reference to it:
$s = \('a', 'b', 'c'); # WARNING: probably not what you thinkAs it happens, this is identical to
$s = (\'a', \'b', \'c'); # List of references to scalars
An enumerated list always yields the last element in a scalar context (as in C), which means that $s contains a reference to the constant string c. Anonymous arrays, discussed later in the section "References to Anonymous Storage," provide the correct solution.
References to hashes are equally straightforward:
$rhash = \%hash;
print $hash{"key1"}; # Ordinary hash lookup
print $$rhash{"key1"}; # hash replaced by $rhashHash slices work the same way too:
@slice = @$rhash{'key1', 'key2'}; # instead of @hash{'key1', 'key2'}A word of advice: You must resist the temptation to implement basic data structures such as linked lists and trees just because a pointerlike capability is available. For small numbers of elements, the standard array data type has pretty decent insertion and removal performance characteristics and is far less resource intensive than linked lists built using Perl primitives. (On my machine, a small test shows that inserting up to around 1250 elements at the head of a Perl array is faster than creating an equivalent linked list.) And if you want BTrees, you should look at the Berkeley DB library (described in Section 10.1, "Persistence Issues") before rolling a Perl equivalent.
The expressions involving key lookups might cause some confusion. Do you read $$rarray[1] as ${$rarray[1]} or {$$rarray}[1] or ${$rarray}[1]?
(Pause here to give your eyes time to refocus!)
As it happens, the last one is the correct answer. Perl follows these two simple rules while parsing such expressions: (1) Key or index lookups are done at the end, and (2) the prefix closest to a variable name binds most closely. When Perl sees something like $$rarray[1] or $$rhash{"browns"}, it leaves index lookups ([1] and {"browns"}) to the very end. That leaves $$rarray and $$rhash. It gives preference to the `$' closest to the variable name. So the precedence works out like this: ${$rarray} and ${$rhash}. Another way of visualizing the second rule is that the preference is given to the symbols from right to left (the variable is always to the right of a series of symbols).
Note that we are not really talking about operator precedence, since $, @ , and % are not operators; the rules above indicate the way an expression is parsed.
Perl provides an alternate and easier-to-read syntax for accessing array or hash elements: the ->[ ] notation. For example, given the array's reference, you can obtain the second element of the array like this:
$rarray = \@array; print $rarray->[1] ; # The "visually clean" way
instead of the approaches we have seen earlier:
print $$rarray[1]; # Noisy, and have to think about precedence
print ${$rarray}[1]; # The way to get tendinitis!I prefer the arrow notation, because it is less visually noisy. Figure 1.1 shows a way to visualize this notation.
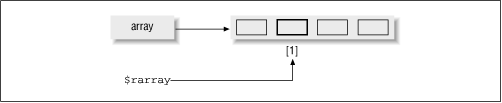
Similarly, you can use the ->{ } notation to access an element of a hash table:
$rhash = \%hash;
print $rhash->{"k1"};
#instead of ........
print $$rhash{"k1"};
# or
print ${$rhash}{"k1"};Caution: This notation works only for single indices, not for slices. Consider the following:
print $rarray->[0,2]; # Warning: This is NOT an indirect array slice.
Perl treats the stuff within the brackets as a comma-separated expression that yields the last term in the array: 2. Hence, this expression is equivalent to $rarray->[2], which is an index lookup, not a slice. (Recall the rule mentioned earlier: An enumerated or comma-separated list always returns the last element in a scalar context.)
Perl does not do any automatic dereferencing for you.[3] You must explicitly dereference using the constructs just described. This is similar to C, in which you have to say *p to indicate the object pointed to by p. Consider
$rarray = \@array; push ($rarray, 1, 2, 3); # Error: $rarray is a scalar, not an array push (@$rarray, 1, 2, 3); # OK
push expects an array as the first argument, not a reference to an array (which is a scalar). Similarly, when printing an array, Perl does not automatically dereference any references. Consider
print "$rarray, $rhash";This prints
ARRAY(0xc70858), HASH(0xb75ce8)
This issue may seem benign but has ugly consequences in two cases. The first is when a reference is used in an arithmetic or conditional expression by mistake; for example, if you said $a += $r when you really meant to say $a += $$r, you'll get only a hard-to-track bug. The second common mistake is assigning an array to a scalar ($a = @array) instead of the array reference ($a = \@array). Perl does not warn you in either case, and Murphy's law being what it is, you will discover this problem only when you are giving a demo to a customer.
|  | |
| Acknowledgments |  | 1.2 Using References |